 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Navigation System for Library Service Robot Based on Unitree Go2 Edu
Jun 02, 2026Libraries require autonomous robots to move quietly through narrow aisles while remaining safe around readers, chairs, bags, and carts. This paper presents a ROS 2 navigation system for a Unitree Go2 Edu quadruped equipped with a 4D LiDAR, a front depth camera, and an IMU. Rather than assuming the library is rough terrain, we target the practical mobility discontinuities of real deployments, including floor transitions, temporary clutter, and partially blocked passages where low-clearance wheeled platforms are less tolerant. RTAB-Map is used for visual-LiDAR SLAM, AMCL and EKF-based sensor fusion provide localization, and a Nav2 stack with A* and DWA supports planning and local avoidance. In a real library, the system achieves 100%, 96%, and 88% success rates in static, low-density dynamic, and high-density dynamic scenes, while map validation against surveyed control distances yields a mean metric error of 3.7 cm.
The establishment of static digital humans and the integration with spinal models
Feb 11, 2025Adolescent idiopathic scoliosis (AIS), a prevalent spinal deformity, significantly affects individuals' health and quality of life. Conventional imaging techniques, such as X - rays, computed tomography (CT), and magnetic resonance imaging (MRI), offer static views of the spine. However, they are restricted in capturing the dynamic changes of the spine and its interactions with overall body motion. Therefore, developing new techniques to address these limitations has become extremely important. Dynamic digital human modeling represents a major breakthrough in digital medicine. It enables a three - dimensional (3D) view of the spine as it changes during daily activities, assisting clinicians in detecting deformities that might be missed in static imaging. Although dynamic modeling holds great potential, constructing an accurate static digital human model is a crucial initial step for high - precision simulations. In this study, our focus is on constructing an accurate static digital human model integrating the spine, which is vital for subsequent dynamic digital human research on AIS. First, we generate human point - cloud data by combining the 3D Gaussian method with the Skinned Multi - Person Linear (SMPL) model from the patient's multi - view images. Then, we fit a standard skeletal model to the generated human model. Next, we align the real spine model reconstructed from CT images with the standard skeletal model. We validated the resulting personalized spine model using X - ray data from six AIS patients, with Cobb angles (used to measure the severity of scoliosis) as evaluation metrics. The results indicate that the model's error was within 1 degree of the actual measurements. This study presents an important method for constructing digital humans.
Leveraging Large Language Models as Knowledge-Driven Agents for Reliable Retrosynthesis Planning
Jan 15, 2025



Identifying reliable synthesis pathways in materials chemistry is a complex task, particularly in polymer science, due to the intricate and often non-unique nomenclature of macromolecules. To address this challenge, we propose an agent system that integrates large language models (LLMs) and knowledge graphs (KGs). By leveraging LLMs' powerful capabilities for extracting and recognizing chemical substance names, and storing the extracted data in a structured knowledge graph, our system fully automates the retrieval of relevant literatures, extraction of reaction data, database querying, construction of retrosynthetic pathway trees, further expansion through the retrieval of additional literature and recommendation of optimal reaction pathways. A novel Multi-branched Reaction Pathway Search (MBRPS) algorithm enables the exploration of all pathways, with a particular focus on multi-branched ones, helping LLMs overcome weak reasoning in multi-branched paths. This work represents the first attempt to develop a fully automated retrosynthesis planning agent tailored specially for macromolecules powered by LLMs. Applied to polyimide synthesis, our new approach constructs a retrosynthetic pathway tree with hundreds of pathways and recommends optimized routes, including both known and novel pathways, demonstrating its effectiveness and potential for broader applications.
Learning to Adapt to Low-Resource Paraphrase Generation
Dec 22, 2024Paraphrase generation is a longstanding NLP task and achieves great success with the aid of large corpora. However, transferring a paraphrasing model to another domain encounters the problem of domain shifting especially when the data is sparse. At the same time, widely using large pre-trained language models (PLMs) faces the overfitting problem when training on scarce labeled data. To mitigate these two issues, we propose, LAPA, an effective adapter for PLMs optimized by meta-learning. LAPA has three-stage training on three types of related resources to solve this problem: 1. pre-training PLMs on unsupervised corpora, 2. inserting an adapter layer and meta-training on source domain labeled data, and 3. fine-tuning adapters on a small amount of target domain labeled data. This method enables paraphrase generation models to learn basic language knowledge first, then learn the paraphrasing task itself later, and finally adapt to the target task. Our experimental results demonstrate that LAPA achieves state-of-the-art in supervised, unsupervised, and low-resource settings on three benchmark datasets. With only 2\% of trainable parameters and 1\% labeled data of the target task, our approach can achieve a competitive performance with previous work.
HEP-NAS: Towards Efficient Few-shot Neural Architecture Search via Hierarchical Edge Partitioning
Dec 14, 2024One-shot methods have significantly advanced the field of neural architecture search (NAS) by adopting weight-sharing strategy to reduce search costs. However, the accuracy of performance estimation can be compromised by co-adaptation. Few-shot methods divide the entire supernet into individual sub-supernets by splitting edge by edge to alleviate this issue, yet neglect relationships among edges and result in performance degradation on huge search space. In this paper, we introduce HEP-NAS, a hierarchy-wise partition algorithm designed to further enhance accuracy. To begin with, HEP-NAS treats edges sharing the same end node as a hierarchy, permuting and splitting edges within the same hierarchy to directly search for the optimal operation combination for each intermediate node. This approach aligns more closely with the ultimate goal of NAS. Furthermore, HEP-NAS selects the most promising sub-supernet after each segmentation, progressively narrowing the search space in which the optimal architecture may exist. To improve performance evaluation of sub-supernets, HEP-NAS employs search space mutual distillation, stabilizing the training process and accelerating the convergence of each individual sub-supernet. Within a given budget, HEP-NAS enables the splitting of all edges and gradually searches for architectures with higher accuracy. Experimental results across various datasets and search spaces demonstrate the superiority of HEP-NAS compared to state-of-the-art methods.
Switchable deep beamformer for high-quality and real-time passive acoustic mapping
Dec 03, 2024
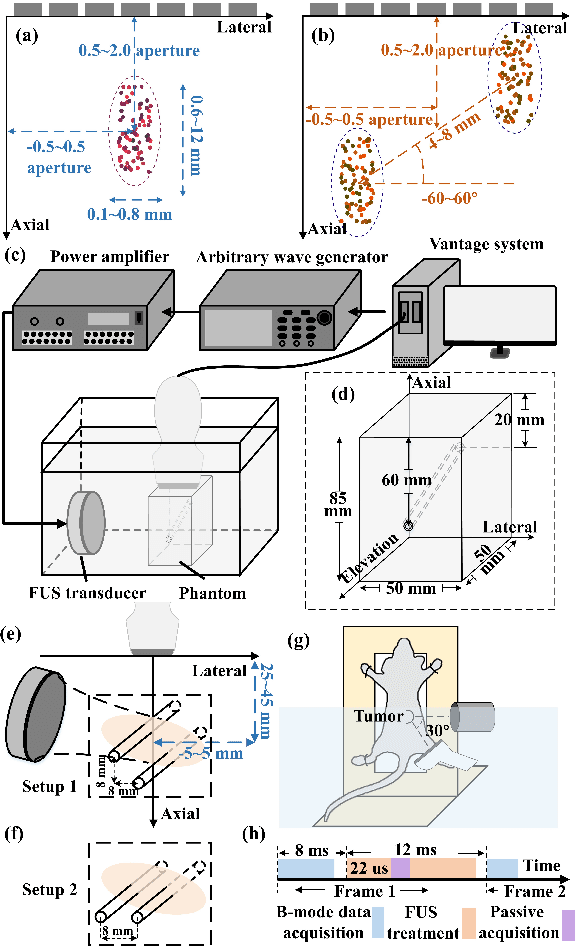
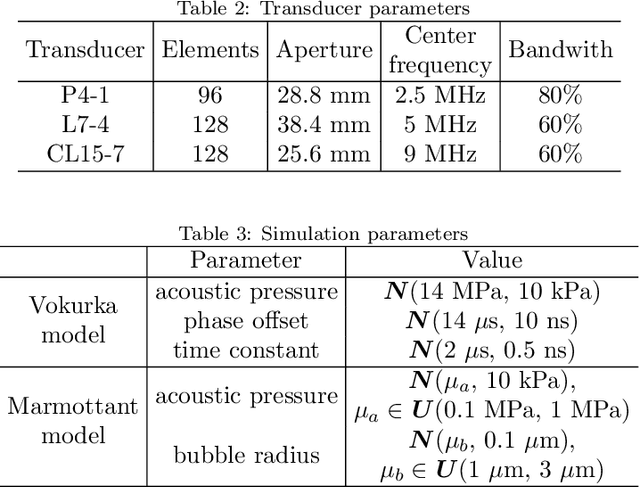
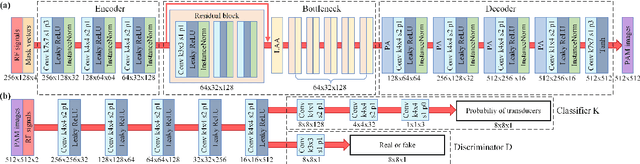
Passive acoustic mapping (PAM) is a promising tool for monitoring acoustic cavitation activities in the applications of ultrasound therapy. Data-adaptive beamformers for PAM have better image quality compared to the time exposure acoustics (TEA) algorithms. However, the computational cost of data-adaptive beamformers is considerably expensive. In this work, we develop a deep beamformer based on a generative adversarial network, which can switch between different transducer arrays and reconstruct high-quality PAM images directly from radio frequency ultrasound signals with low computational cost. The deep beamformer was trained on the dataset consisting of simulated and experimental cavitation signals of single and multiple microbubble clouds measured by different (linear and phased) arrays covering 1-15 MHz. We compared the performance of the deep beamformer to TEA and three different data-adaptive beamformers using the simulated and experimental test dataset. Compared with TEA, the deep beamformer reduced the energy spread area by 18.9%-65.0% and improved the image signal-to-noise ratio by 9.3-22.9 dB in average for the different arrays in our data. Compared to the data-adaptive beamformers, the deep beamformer reduced the computational cost by three orders of magnitude achieving 10.5 ms image reconstruction speed in our data, while the image quality was as good as that of the data-adaptive beamformers. These results demonstrated the potential of the deep beamformer for high-resolution monitoring of microbubble cavitation activities for ultrasound therapy.
Towards Fully Autonomous Research Powered by LLMs: Case Study on Simulations
Aug 28, 2024



The advent of Large Language Models (LLMs) has created new opportunities for the automation of scientific research, spanning both experimental processes and computational simulations. This study explores the feasibility of constructing an autonomous simulation agent (ASA) powered by LLM, through sophisticated API integration, to automate the entire research process, from experimental design, remote upload and simulation execution, data analysis, to report compilation. Using a simulation problem of polymer chain conformations as a case study, we assessed the performance of ASAs powered by different LLMs including GPT-4-Turbo. Our findings revealed that ASA-GPT-4o achieved near-flawless execution on designated research missions, underscoring the potential of LLMs to manage complete scientific investigations autonomously. The outlined automation can be iteratively performed up to twenty cycles without human intervention, illustrating the potential of LLMs for large-scale autonomous research endeavors. Additionally, we discussed the intrinsic traits of ASAs in managing extensive tasks, focusing on self-validation mechanisms and the balance between local attention and global oversight.
Planning with Large Language Models for Conversational Agents
Jul 04, 2024Controllability and proactivity are crucial properties of autonomous conversational agents (CAs). Controllability requires the CAs to follow the standard operating procedures (SOPs), such as verifying identity before activating credit cards. Proactivity requires the CAs to guide the conversation towards the goal during user uncooperation, such as persuasive dialogue. Existing research cannot be unified with controllability, proactivity, and low manual annotation. To bridge this gap, we propose a new framework for planning-based conversational agents (PCA) powered by large language models (LLMs), which only requires humans to define tasks and goals for the LLMs. Before conversation, LLM plans the core and necessary SOP for dialogue offline. During the conversation, LLM plans the best action path online referring to the SOP, and generates responses to achieve process controllability. Subsequently, we propose a semi-automatic dialogue data creation framework and curate a high-quality dialogue dataset (PCA-D). Meanwhile, we develop multiple variants and evaluation metrics for PCA, e.g., planning with Monte Carlo Tree Search (PCA-M), which searches for the optimal dialogue action while satisfying SOP constraints and achieving the proactive of the dialogue. Experiment results show that LLMs finetuned on PCA-D can significantly improve the performance and generalize to unseen domains. PCA-M outperforms other CoT and ToT baselines in terms of conversation controllability, proactivity, task success rate, and overall logical coherence, and is applicable in industry dialogue scenarios. The dataset and codes are available at XXXX.
Estimating Depth of Monocular Panoramic Image with Teacher-Student Model Fusing Equirectangular and Spherical Representations
May 27, 2024



Disconnectivity and distortion are the two problems which must be coped with when processing 360 degrees equirectangular images. In this paper, we propose a method of estimating the depth of monocular panoramic image with a teacher-student model fusing equirectangular and spherical representations. In contrast with the existing methods fusing an equirectangular representation with a cube map representation or tangent representation, a spherical representation is a better choice because a sampling on a sphere is more uniform and can also cope with distortion more effectively. In this processing, a novel spherical convolution kernel computing with sampling points on a sphere is developed to extract features from the spherical representation, and then, a Segmentation Feature Fusion(SFF) methodology is utilized to combine the features with ones extracted from the equirectangular representation. In contrast with the existing methods using a teacher-student model to obtain a lighter model of depth estimation, we use a teacher-student model to learn the latent features of depth images. This results in a trained model which estimates the depth map of an equirectangular image using not only the feature maps extracted from an input equirectangular image but also the distilled knowledge learnt from the ground truth of depth map of a training set. In experiments, the proposed method is tested on several well-known 360 monocular depth estimation benchmark datasets, and outperforms the existing methods for the most evaluation indexes.
TrafficGPT: Breaking the Token Barrier for Efficient Long Traffic Analysis and Generation
Mar 09, 2024



Over the years, network traffic analysis and generation have advanced significantly. From traditional statistical methods, the field has progressed to sophisticated deep learning techniques. This progress has improved the ability to detect complex patterns and security threats, as well as to test and optimize network performance. However, obstacles persist, such as the dependence on labeled data for analysis and the difficulty of generating traffic samples that follow realistic patterns. Pre-trained deep neural networks have emerged as powerful tools to resolve these issues, offering improved performance by learning robust data representations from large unlabeled datasets. Despite their benefits, existing pre-trained models face challenges like token length limitation, which restricts their usefulness in comprehensive traffic analysis and realistic traffic generation. To address these challenges, we introduce TrafficGPT, a deep learning model that can tackle complex challenges related to long flow classification and generation tasks. This model uses generative pre-training with the linear attention mechanism, which allows for a substantially increased capacity of up to 12,032 tokens from the previous limit of only 512 tokens. TrafficGPT demonstrates superior performance in classification tasks, reaching state-of-the-art levels. In generation tasks, it closely resembles real traffic flows, with low JS divergence and an F1 score close to 0.5 (representing a random guess) in discriminating generated data. These advancements hold promise for future applications in both traffic flow classification and generation tasks.