 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitSnap: Checkpoint Sparsification and Quantization in LLM Training
Nov 18, 2025As large language models (LLMs) continue to grow in size and complexity, efficient checkpoint saving\&loading has become crucial for managing storage, memory usage, and fault tolerance in LLM training. The current works do not comprehensively take into account the optimization of these several aspects. This paper proposes a novel checkpoint sparsification and quantization method that adapts dynamically to different training stages and model architectures. We present a comprehensive analysis of existing lossy and lossless compression techniques, identify current limitations, and introduce our adaptive approach that balances compression ratio, speed, and precision impact throughout the training process. Experiments on different sizes of LLMs demonstrate that our bitmask-based sparsification method achieves 16x compression ratio without compromising model accuracy. Additionally, the cluster-based quantization method achieves 2x compression ratio with little precision loss.
FlashSparse: Minimizing Computation Redundancy for Fast Sparse Matrix Multiplications on Tensor Cores
Dec 15, 2024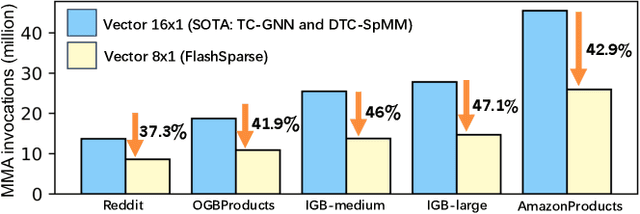

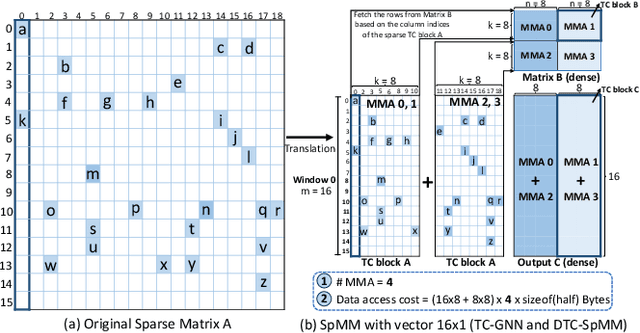

Sparse Matrix-matrix Multiplication (SpMM) and Sampled Dense-dense Matrix Multiplication (SDDMM) are important sparse operators in scientific computing and deep learning. Tensor Core Units (TCUs) enhance modern accelerators with superior computing power, which is promising to boost the performance of matrix operators to a higher level. However, due to the irregularity of unstructured sparse data, it is difficult to deliver practical speedups on TCUs. To this end, we propose FlashSparse, a novel approach to bridge the gap between sparse workloads and the TCU architecture. Specifically, FlashSparse minimizes the sparse granularity for SpMM and SDDMM on TCUs through a novel swap-and-transpose matrix multiplication strategy. Benefiting from the minimum sparse granularity, the computation redundancy is remarkably reduced while the computing power of TCUs is fully utilized. Besides, FlashSparse is equipped with a memory-efficient thread mapping strategy for coalesced data access and a sparse matrix storage format to save memory footprint. Extensive experimental results on H100 and RTX 4090 GPUs show that FlashSparse sets a new state-of-the-art for sparse matrix multiplications (geometric mean 5.5x speedup over DTC-SpMM and 3.22x speedup over RoDe).
Estimating Depth of Monocular Panoramic Image with Teacher-Student Model Fusing Equirectangular and Spherical Representations
May 27, 2024



Disconnectivity and distortion are the two problems which must be coped with when processing 360 degrees equirectangular images. In this paper, we propose a method of estimating the depth of monocular panoramic image with a teacher-student model fusing equirectangular and spherical representations. In contrast with the existing methods fusing an equirectangular representation with a cube map representation or tangent representation, a spherical representation is a better choice because a sampling on a sphere is more uniform and can also cope with distortion more effectively. In this processing, a novel spherical convolution kernel computing with sampling points on a sphere is developed to extract features from the spherical representation, and then, a Segmentation Feature Fusion(SFF) methodology is utilized to combine the features with ones extracted from the equirectangular representation. In contrast with the existing methods using a teacher-student model to obtain a lighter model of depth estimation, we use a teacher-student model to learn the latent features of depth images. This results in a trained model which estimates the depth map of an equirectangular image using not only the feature maps extracted from an input equirectangular image but also the distilled knowledge learnt from the ground truth of depth map of a training set. In experiments, the proposed method is tested on several well-known 360 monocular depth estimation benchmark datasets, and outperforms the existing methods for the most evaluation indexes.
TRANSOM: An Efficient Fault-Tolerant System for Training LLMs
Oct 18, 2023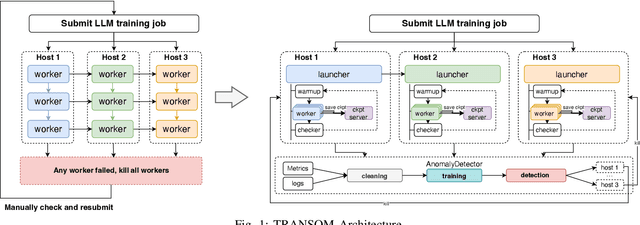
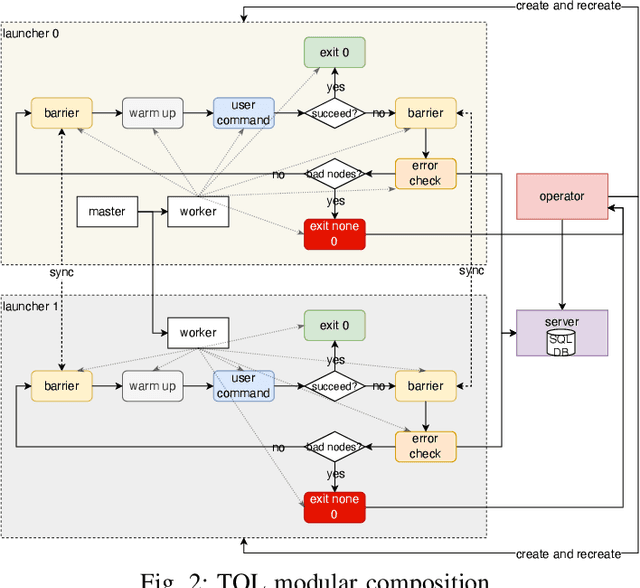
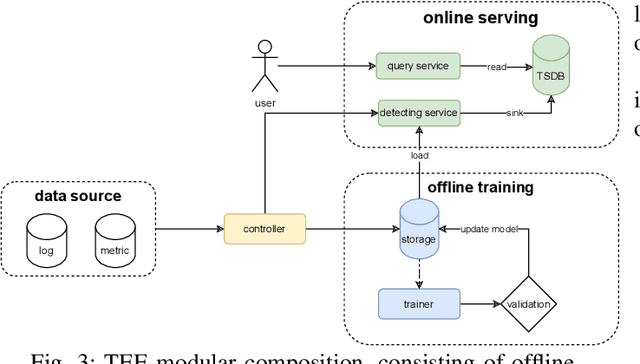
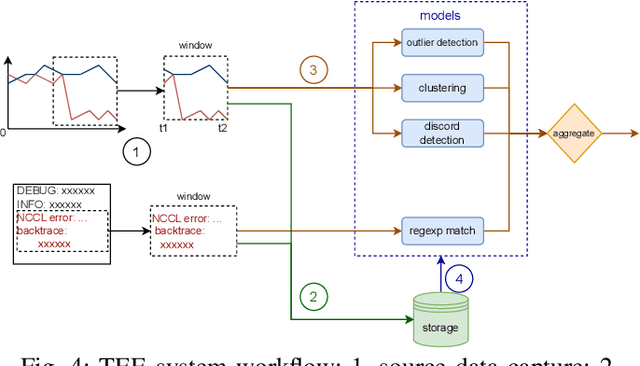
Large language models (LLMs) with hundreds of billions or trillions of parameters, represented by chatGPT, have achieved profound impact on various fields. However, training LLMs with super-large-scale parameters requires large high-performance GPU clusters and long training periods lasting for months. Due to the inevitable hardware and software failures in large-scale clusters, maintaining uninterrupted and long-duration training is extremely challenging. As a result, A substantial amount of training time is devoted to task checkpoint saving and loading, task rescheduling and restart, and task manual anomaly checks, which greatly harms the overall training efficiency. To address these issues, we propose TRANSOM, a novel fault-tolerant LLM training system. In this work, we design three key subsystems: the training pipeline automatic fault tolerance and recovery mechanism named Transom Operator and Launcher (TOL), the training task multi-dimensional metric automatic anomaly detection system named Transom Eagle Eye (TEE), and the training checkpoint asynchronous access automatic fault tolerance and recovery technology named Transom Checkpoint Engine (TCE). Here, TOL manages the lifecycle of training tasks, while TEE is responsible for task monitoring and anomaly reporting. TEE detects training anomalies and reports them to TOL, who automatically enters the fault tolerance strategy to eliminate abnormal nodes and restart the training task. And the asynchronous checkpoint saving and loading functionality provided by TCE greatly shorten the fault tolerance overhead. The experimental results indicate that TRANSOM significantly enhances the efficiency of large-scale LLM training on clusters. Specifically, the pre-training time for GPT3-175B has been reduced by 28%, while checkpoint saving and loading performance have improved by a factor of 20.
Co-design Hardware and Algorithm for Vector Search
Jul 06, 2023Vector search has emerged as the foundation for large-scale information retrieval and machine learning systems, with search engines like Google and Bing processing tens of thousands of queries per second on petabyte-scale document datasets by evaluating vector similarities between encoded query texts and web documents. As performance demands for vector search systems surge, accelerated hardware offers a promising solution in the post-Moore's Law era. We introduce \textit{FANNS}, an end-to-end and scalable vector search framework on FPGAs. Given a user-provided recall requirement on a dataset and a hardware resource budget, \textit{FANNS} automatically co-designs hardware and algorithm, subsequently generating the corresponding accelerator. The framework also supports scale-out by incorporating a hardware TCP/IP stack in the accelerator. \textit{FANNS} attains up to 23.0$\times$ and 37.2$\times$ speedup compared to FPGA and CPU baselines, respectively, and demonstrates superior scalability to GPUs, achieving 5.5$\times$ and 7.6$\times$ speedup in median and 95\textsuperscript{th} percentile (P95) latency within an eight-accelerator configuration. The remarkable performance of \textit{FANNS} lays a robust groundwork for future FPGA integration in data centers and AI supercomputers.
ASDL: A Unified Interface for Gradient Preconditioning in PyTorch
May 08, 2023



Gradient preconditioning is a key technique to integrate the second-order information into gradients for improving and extending gradient-based learning algorithms. In deep learning, stochasticity, nonconvexity, and high dimensionality lead to a wide variety of gradient preconditioning methods, with implementation complexity and inconsistent performance and feasibility. We propose the Automatic Second-order Differentiation Library (ASDL), an extension library for PyTorch, which offers various implementations and a plug-and-play unified interface for gradient preconditioning. ASDL enables the study and structured comparison of a range of gradient preconditioning methods.
An End-to-End Network for Upright Adjustment of Panoramic Images
Apr 12, 2023



Nowadays, panoramic images can be easily obtained by panoramic cameras. However, when the panoramic camera orientation is tilted, a non-upright panoramic image will be captured. Existing upright adjustment models focus on how to estimate more accurate camera orientation, and attribute image reconstruction to offline or post-processing tasks. To this end, we propose an online end-to-end network for upright adjustment. Our network is designed to reconstruct the image while finding the angle. Our network consists of three modules: orientation estimation, LUT online generation, and upright reconstruction. Direction estimation estimates the tilt angle of the panoramic image. Then, a converter block with upsampling function is designed to generate angle to LUT. This module can output corresponding online LUT for different input angles. Finally, a lightweight generative adversarial network (GAN) aims to generate upright images from shallow features. The experimental results show that in terms of angles, we have improved the accuracy of small angle errors. In terms of image reconstruction, In image reconstruction, we have achieved the first real-time online upright reconstruction of panoramic images using deep learning networks.
PipeFisher: Efficient Training of Large Language Models Using Pipelining and Fisher Information Matrices
Nov 25, 2022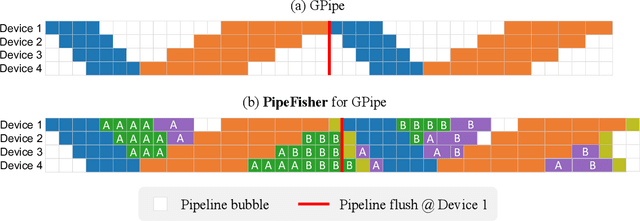
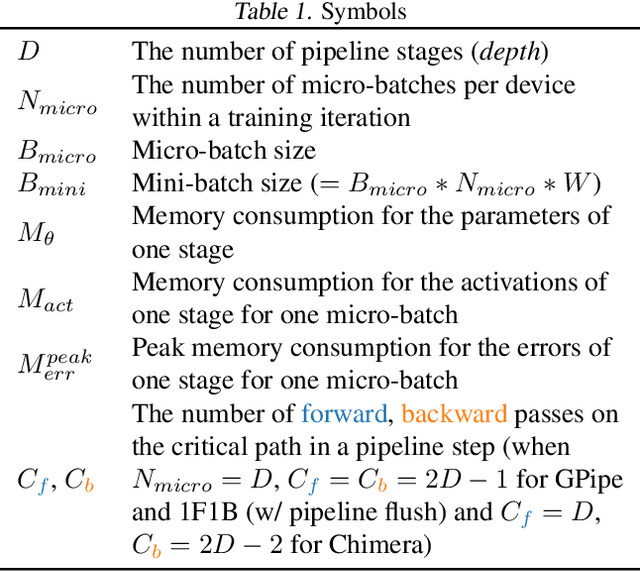
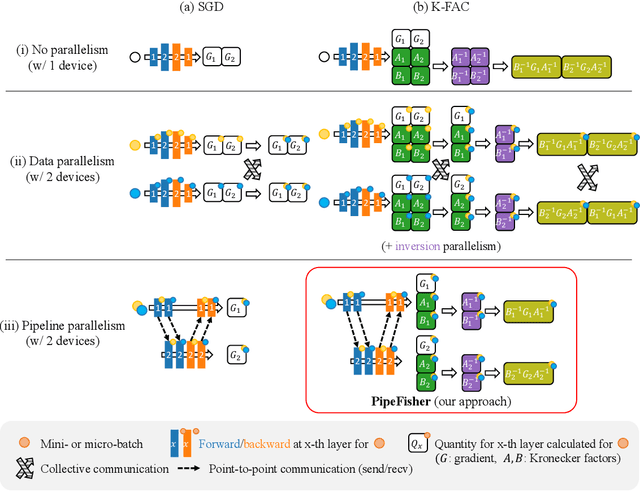

Pipeline parallelism enables efficient training of Large Language Models (LLMs) on large-scale distributed accelerator clusters. Yet, pipeline bubbles during startup and tear-down reduce the utilization of accelerators. Although efficient pipeline schemes with micro-batching and bidirectional pipelines have been proposed to maximize utilization, a significant number of bubbles cannot be filled using synchronous forward and backward passes. To address this problem, we suggest that extra work be assigned to the bubbles to gain auxiliary benefits in LLM training. As an example in this direction, we propose PipeFisher, which assigns the work of K-FAC, a second-order optimization method based on the Fisher information matrix, to the bubbles to accelerate convergence. In Phase 1 pretraining of BERT-Base and -Large models, PipeFisher reduces the (simulated) training time to 50-75% compared to training with a first-order optimizer by greatly improving the accelerator utilization and benefiting from the improved convergence by K-FAC.
Efficient Quantized Sparse Matrix Operations on Tensor Cores
Sep 14, 2022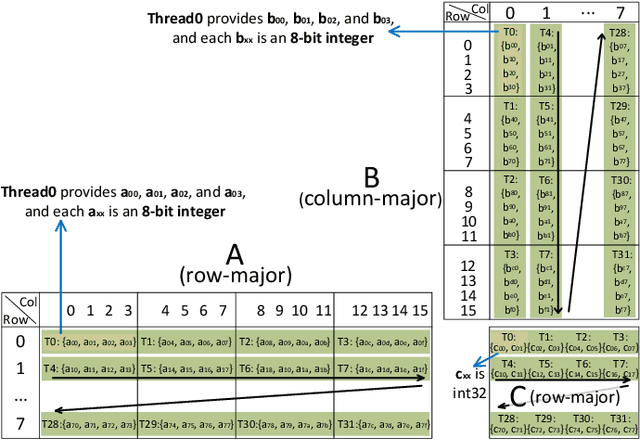
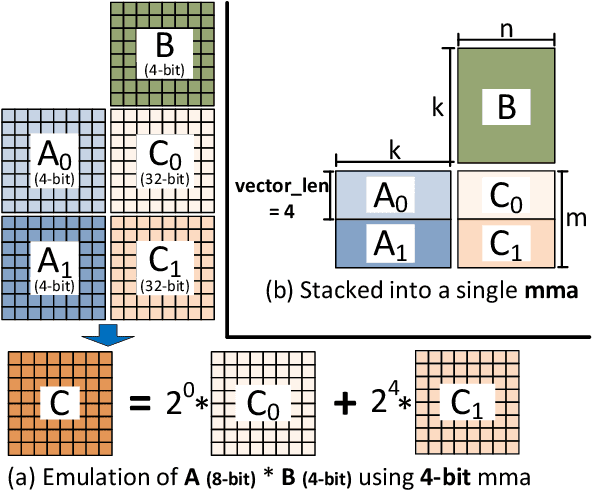
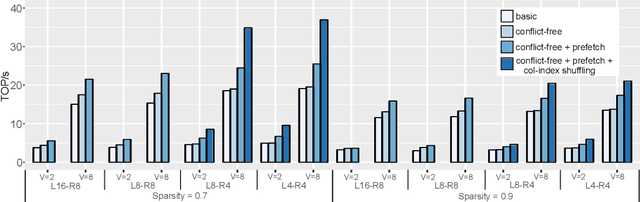
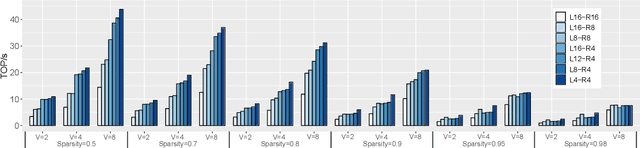
The exponentially growing model size drives the continued success of deep learning, but it brings prohibitive computation and memory cost. From the algorithm perspective, model sparsification and quantization have been studied to alleviate the problem. From the architecture perspective, hardware vendors provide Tensor cores for acceleration. However, it is very challenging to gain practical speedups from sparse, low-precision matrix operations on Tensor cores, because of the strict requirements for data layout and lack of support for efficiently manipulating the low-precision integers. We propose Magicube, a high-performance sparse-matrix library for low-precision integers on Tensor cores. Magicube supports SpMM and SDDMM, two major sparse operations in deep learning with mixed precision. Experimental results on an NVIDIA A100 GPU show that Magicube achieves on average 1.44x (up to 2.37x) speedup over the vendor-optimized library for sparse kernels, and 1.43x speedup over the state-of-the-art with a comparable accuracy for end-to-end sparse Transformer inference.
HammingMesh: A Network Topology for Large-Scale Deep Learning
Sep 03, 2022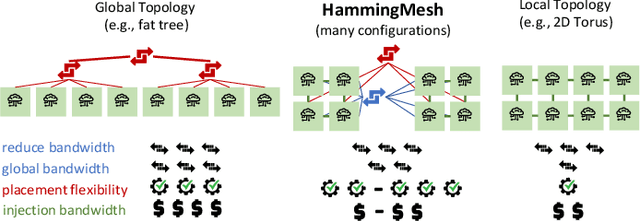
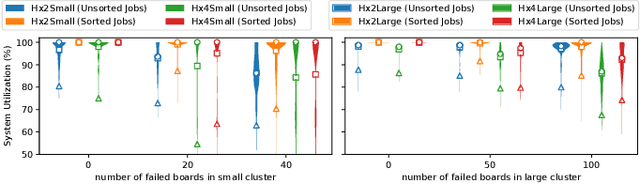
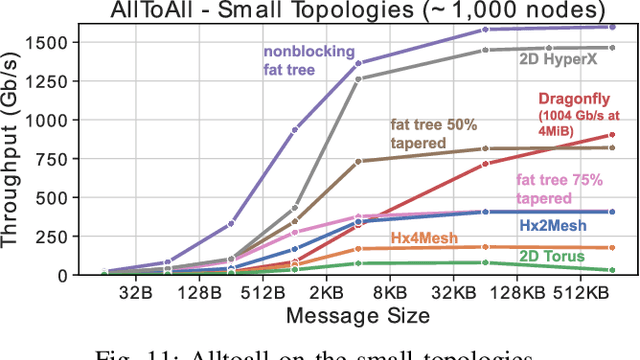
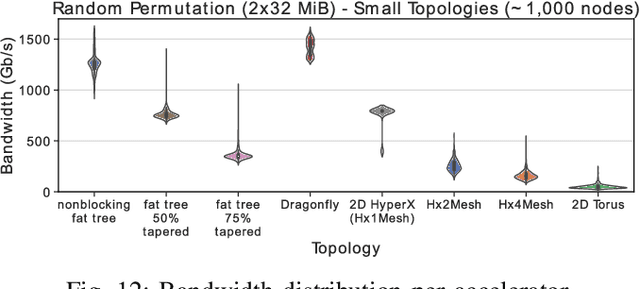
Numerous microarchitectural optimizations unlocked tremendous processing power for deep neural networks that in turn fueled the AI revolution. With the exhaustion of such optimizations, the growth of modern AI is now gated by the performance of training systems, especially their data movement. Instead of focusing on single accelerators, we investigate data-movement characteristics of large-scale training at full system scale. Based on our workload analysis, we design HammingMesh, a novel network topology that provides high bandwidth at low cost with high job scheduling flexibility. Specifically, HammingMesh can support full bandwidth and isolation to deep learning training jobs with two dimensions of parallelism. Furthermore, it also supports high global bandwidth for generic traffic. Thus, HammingMesh will power future large-scale deep learning systems with extreme bandwidth requirements.