 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEG Foundation Models: Progresses, Benchmarking, and Open Problems
Jan 25, 2026Electroencephalography (EEG) foundation models have recently emerged as a promising paradigm for brain-computer interfaces (BCIs), aiming to learn transferable neural representations from large-scale heterogeneous recordings. Despite rapid progresses, there lacks fair and comprehensive comparisons of existing EEG foundation models, due to inconsistent pre-training objectives, preprocessing choices, and downstream evaluation protocols. This paper fills this gap. We first review 50 representative models and organize their design choices into a unified taxonomic framework including data standardization, model architectures, and self-supervised pre-training strategies. We then evaluate 12 open-source foundation models and competitive specialist baselines across 13 EEG datasets spanning nine BCI paradigms. Emphasizing real-world deployments, we consider both cross-subject generalization under a leave-one-subject-out protocol and rapid calibration under a within-subject few-shot setting. We further compare full-parameter fine-tuning with linear probing to assess the transferability of pre-trained representations, and examine the relationship between model scale and downstream performance. Our results indicate that: 1) linear probing is frequently insufficient; 2) specialist models trained from scratch remain competitive across many tasks; and, 3) larger foundation models do not necessarily yield better generalization performance under current data regimes and training practices.
Trajectory Entropy: Modeling Game State Stability from Multimodality Trajectory Prediction
Jun 06, 2025Complex interactions among agents present a significant challenge for autonomous driving in real-world scenarios. Recently, a promising approach has emerged, which formulates the interactions of agents as a level-k game framework. It effectively decouples agent policies by hierarchical game levels. However, this framework ignores both the varying driving complexities among agents and the dynamic changes in agent states across game levels, instead treating them uniformly. Consequently, redundant and error-prone computations are introduced into this framework. To tackle the issue, this paper proposes a metric, termed as Trajectory Entropy, to reveal the game status of agents within the level-k game framework. The key insight stems from recognizing the inherit relationship between agent policy uncertainty and the associated driving complexity. Specifically, Trajectory Entropy extracts statistical signals representing uncertainty from the multimodality trajectory prediction results of agents in the game. Then, the signal-to-noise ratio of this signal is utilized to quantify the game status of agents. Based on the proposed Trajectory Entropy, we refine the current level-k game framework through a simple gating mechanism, significantly improving overall accuracy while reducing computational costs. Our method is evaluated on the Waymo and nuPlan datasets, in terms of trajectory prediction, open-loop and closed-loop planning tasks. The results demonstrate the state-of-the-art performance of our method, with precision improved by up to 19.89% for prediction and up to 16.48% for planning.
The Knowledge Microscope: Features as Better Analytical Lenses than Neurons
Feb 18, 2025



Previous studies primarily utilize MLP neurons as units of analysis for understanding the mechanisms of factual knowledge in Language Models (LMs); however, neurons suffer from polysemanticity, leading to limited knowledge expression and poor interpretability. In this paper, we first conduct preliminary experiments to validate that Sparse Autoencoders (SAE) can effectively decompose neurons into features, which serve as alternative analytical units. With this established, our core findings reveal three key advantages of features over neurons: (1) Features exhibit stronger influence on knowledge expression and superior interpretability. (2) Features demonstrate enhanced monosemanticity, showing distinct activation patterns between related and unrelated facts. (3) Features achieve better privacy protection than neurons, demonstrated through our proposed FeatureEdit method, which significantly outperforms existing neuron-based approaches in erasing privacy-sensitive information from LMs.Code and dataset will be available.
PearSAN: A Machine Learning Method for Inverse Design using Pearson Correlated Surrogate Annealing
Dec 26, 2024PearSAN is a machine learning-assisted optimization algorithm applicable to inverse design problems with large design spaces, where traditional optimizers struggle. The algorithm leverages the latent space of a generative model for rapid sampling and employs a Pearson correlated surrogate model to predict the figure of merit of the true design metric. As a showcase example, PearSAN is applied to thermophotovoltaic (TPV) metasurface design by matching the working bands between a thermal radiator and a photovoltaic cell. PearSAN can work with any pretrained generative model with a discretized latent space, making it easy to integrate with VQ-VAEs and binary autoencoders. Its novel Pearson correlational loss can be used as both a latent regularization method, similar to batch and layer normalization, and as a surrogate training loss. We compare both to previous energy matching losses, which are shown to enforce poor regularization and performance, even with upgraded affine parameters. PearSAN achieves a state-of-the-art maximum design efficiency of 97%, and is at least an order of magnitude faster than previous methods, with an improved maximum figure-of-merit gain.
One Mind, Many Tongues: A Deep Dive into Language-Agnostic Knowledge Neurons in Large Language Models
Nov 26, 2024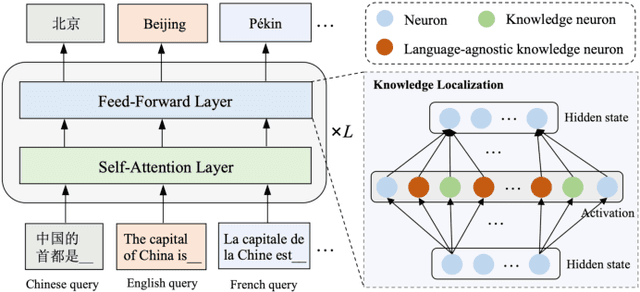
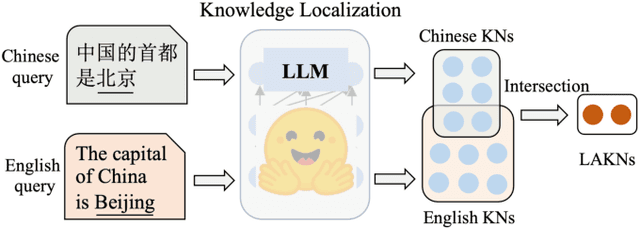
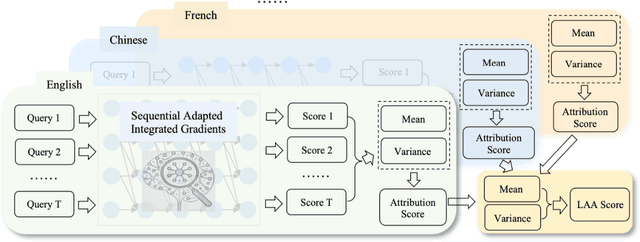
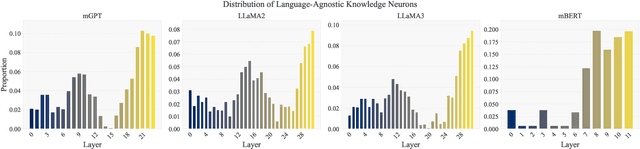
Large language models (LLMs) have learned vast amounts of factual knowledge through self-supervised pre-training on large-scale corpora. Meanwhile, LLMs have also demonstrated excellent multilingual capabilities, which can express the learned knowledge in multiple languages. However, the knowledge storage mechanism in LLMs still remains mysterious. Some researchers attempt to demystify the factual knowledge in LLMs from the perspective of knowledge neurons, and subsequently discover language-agnostic knowledge neurons that store factual knowledge in a form that transcends language barriers. However, the preliminary finding suffers from two limitations: 1) High Uncertainty in Localization Results. Existing study only uses a prompt-based probe to localize knowledge neurons for each fact, while LLMs cannot provide consistent answers for semantically equivalent queries. Thus, it leads to inaccurate localization results with high uncertainty. 2) Lack of Analysis in More Languages. The study only analyzes language-agnostic knowledge neurons on English and Chinese data, without exploring more language families and languages. Naturally, it limits the generalizability of the findings. To address aforementioned problems, we first construct a new benchmark called Rephrased Multilingual LAMA (RML-LAMA), which contains high-quality cloze-style multilingual parallel queries for each fact. Then, we propose a novel method named Multilingual Integrated Gradients with Uncertainty Estimation (MATRICE), which quantifies the uncertainty across queries and languages during knowledge localization. Extensive experiments show that our method can accurately localize language-agnostic knowledge neurons. We also further investigate the role of language-agnostic knowledge neurons in cross-lingual knowledge editing, knowledge enhancement and new knowledge injection.
Unveiling Factual Recall Behaviors of Large Language Models through Knowledge Neurons
Aug 06, 2024In this paper, we investigate whether Large Language Models (LLMs) actively recall or retrieve their internal repositories of factual knowledge when faced with reasoning tasks. Through an analysis of LLMs' internal factual recall at each reasoning step via Knowledge Neurons, we reveal that LLMs fail to harness the critical factual associations under certain circumstances. Instead, they tend to opt for alternative, shortcut-like pathways to answer reasoning questions. By manually manipulating the recall process of parametric knowledge in LLMs, we demonstrate that enhancing this recall process directly improves reasoning performance whereas suppressing it leads to notable degradation. Furthermore, we assess the effect of Chain-of-Thought (CoT) prompting, a powerful technique for addressing complex reasoning tasks. Our findings indicate that CoT can intensify the recall of factual knowledge by encouraging LLMs to engage in orderly and reliable reasoning. Furthermore, we explored how contextual conflicts affect the retrieval of facts during the reasoning process to gain a comprehensive understanding of the factual recall behaviors of LLMs. Code and data will be available soon.
MEMLA: Enhancing Multilingual Knowledge Editing with Neuron-Masked Low-Rank Adaptation
Jun 17, 2024
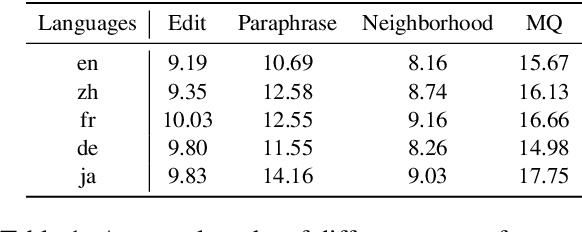

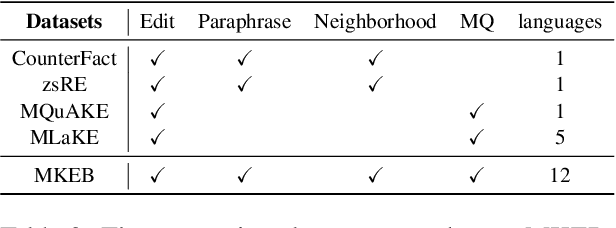
Knowledge editing aims to adjust the knowledge within large language models (LLMs) to prevent their responses from becoming obsolete or inaccurate. However, existing works on knowledge editing are primarily conducted in a single language, which is inadequate for multilingual language models. In this paper, we focus on multilingual knowledge editing (MKE), which requires propagating updates across multiple languages. This necessity poses a significant challenge for the task. Furthermore, the limited availability of a comprehensive dataset for MKE exacerbates this challenge, hindering progress in this area. Hence, we introduce the Multilingual Knowledge Editing Benchmark (MKEB), a novel dataset comprising 12 languages and providing a complete evaluation framework. Additionally, we propose a method that enhances Multilingual knowledge Editing with neuron-Masked Low-Rank Adaptation (MEMLA). Specifically, we identify two categories of knowledge neurons to improve editing precision. Moreover, we perform LoRA-based editing with neuron masks to efficiently modify parameters and facilitate the propagation of updates across multiple languages. Experiments demonstrate that our method outperforms existing baselines and significantly enhances the multi-hop reasoning capability of the edited model, with minimal impact on its downstream task performance. The dataset and code will be made publicly available.
Knowledge Localization: Mission Not Accomplished? Enter Query Localization!
May 23, 2024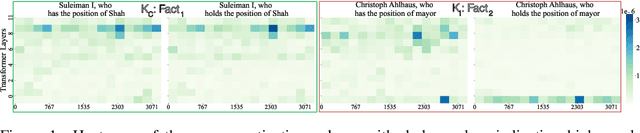


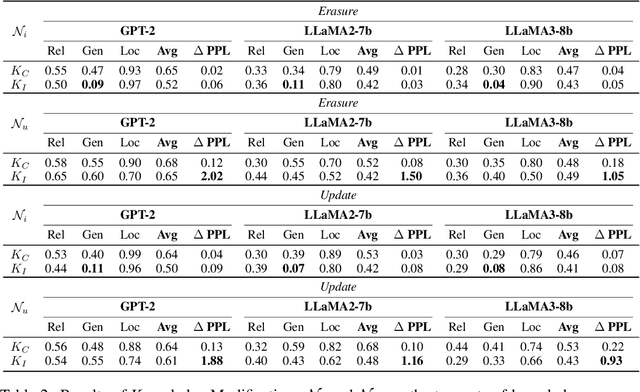
Large language models (LLMs) store extensive factual knowledge, but the mechanisms behind how they store and express this knowledge remain unclear. The Knowledge Neuron (KN) thesis is a prominent theory for explaining these mechanisms. This theory is based on the knowledge localization (KL) assumption, which suggests that a fact can be localized to a few knowledge storage units, namely knowledge neurons. However, this assumption may be overly strong regarding knowledge storage and neglects knowledge expression mechanisms. Thus, we re-examine the KL assumption and confirm the existence of facts that do not adhere to it from both statistical and knowledge modification perspectives. Furthermore, we propose the Query Localization (QL) assumption. (1) Query-KN Mapping: The localization results are associated with the query rather than the fact. (2) Dynamic KN Selection: The attention module contributes to the selection of KNs for answering a query. Based on this, we further propose the Consistency-Aware KN modification method, which improves the performance of knowledge modification. We conduct 39 sets of experiments, along with additional visualization experiments, to rigorously validate our conclusions.
The Da Vinci Code of Large Pre-trained Language Models: Deciphering Degenerate Knowledge Neurons
Feb 21, 2024



This study explores the mechanism of factual knowledge storage in pre-trained language models (PLMs). Previous research suggests that factual knowledge is stored within multi-layer perceptron weights, and some storage units exhibit degeneracy, referred to as Degenerate Knowledge Neurons (DKNs). This paper provides a comprehensive definition of DKNs that covers both structural and functional aspects, pioneering the study of structures in PLMs' factual knowledge storage units. Based on this, we introduce the Neurological Topology Clustering method, which allows the formation of DKNs in any numbers and structures, leading to a more accurate DKN acquisition. Furthermore, we introduce the Neuro-Degeneracy Analytic Analysis Framework, which uniquely integrates model robustness, evolvability, and complexity for a holistic assessment of PLMs. Within this framework, our execution of 34 experiments across 2 PLMs, 4 datasets, and 6 settings highlights the critical role of DKNs. The code will be available soon.
TRANSOM: An Efficient Fault-Tolerant System for Training LLMs
Oct 18, 2023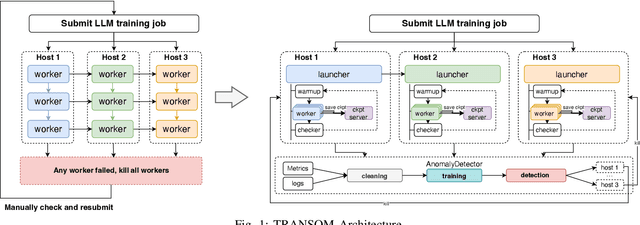
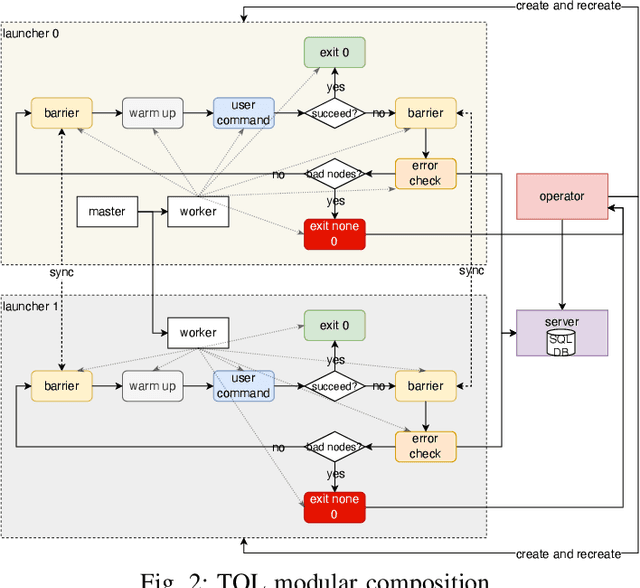
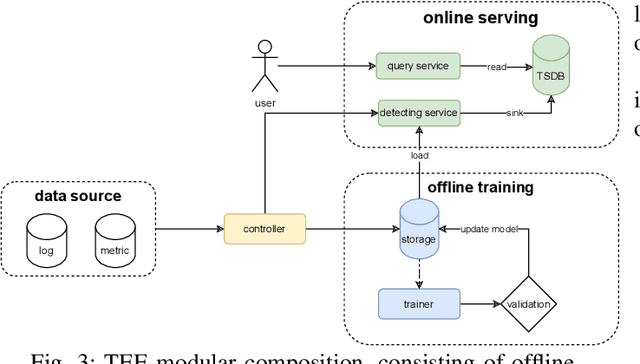
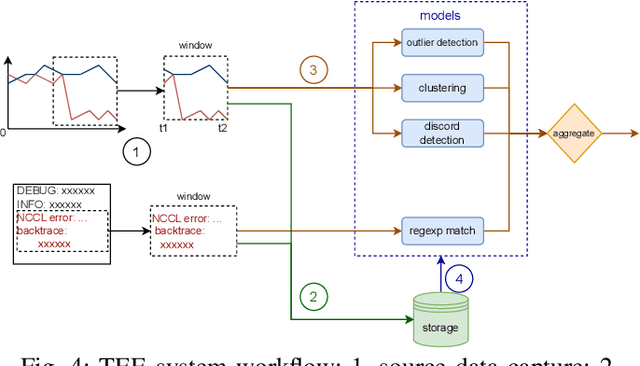
Large language models (LLMs) with hundreds of billions or trillions of parameters, represented by chatGPT, have achieved profound impact on various fields. However, training LLMs with super-large-scale parameters requires large high-performance GPU clusters and long training periods lasting for months. Due to the inevitable hardware and software failures in large-scale clusters, maintaining uninterrupted and long-duration training is extremely challenging. As a result, A substantial amount of training time is devoted to task checkpoint saving and loading, task rescheduling and restart, and task manual anomaly checks, which greatly harms the overall training efficiency. To address these issues, we propose TRANSOM, a novel fault-tolerant LLM training system. In this work, we design three key subsystems: the training pipeline automatic fault tolerance and recovery mechanism named Transom Operator and Launcher (TOL), the training task multi-dimensional metric automatic anomaly detection system named Transom Eagle Eye (TEE), and the training checkpoint asynchronous access automatic fault tolerance and recovery technology named Transom Checkpoint Engine (TCE). Here, TOL manages the lifecycle of training tasks, while TEE is responsible for task monitoring and anomaly reporting. TEE detects training anomalies and reports them to TOL, who automatically enters the fault tolerance strategy to eliminate abnormal nodes and restart the training task. And the asynchronous checkpoint saving and loading functionality provided by TCE greatly shorten the fault tolerance overhead. The experimental results indicate that TRANSOM significantly enhances the efficiency of large-scale LLM training on clusters. Specifically, the pre-training time for GPT3-175B has been reduced by 28%, while checkpoint saving and loading performance have improved by a factor of 20.