 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRANSOM: An Efficient Fault-Tolerant System for Training LLMs
Oct 18, 2023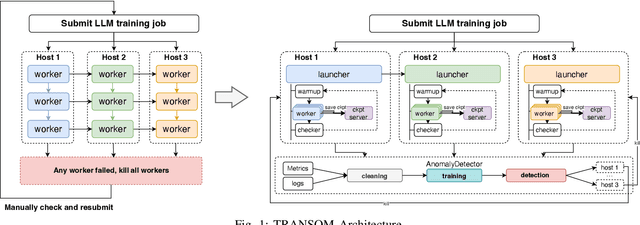
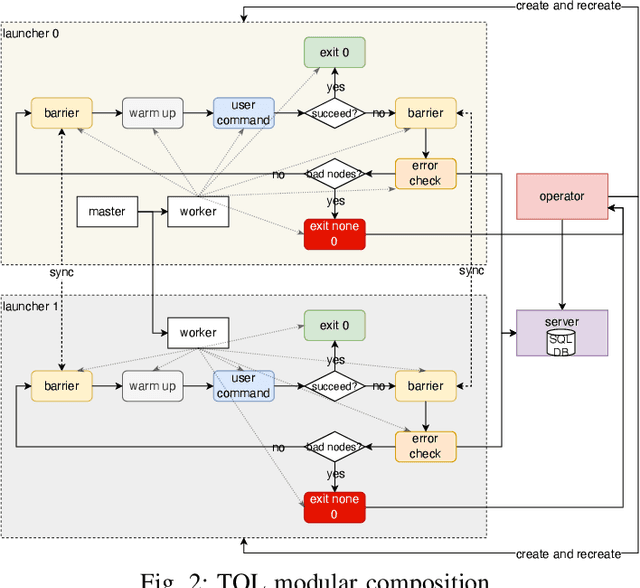
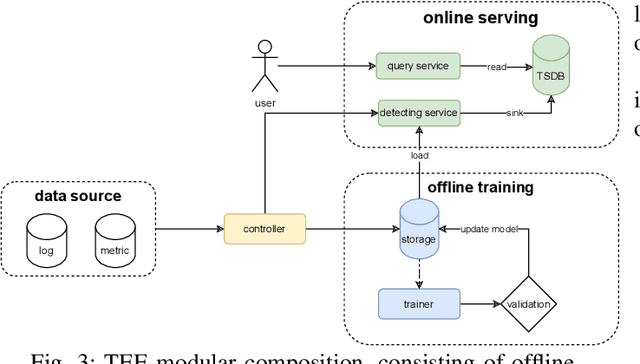
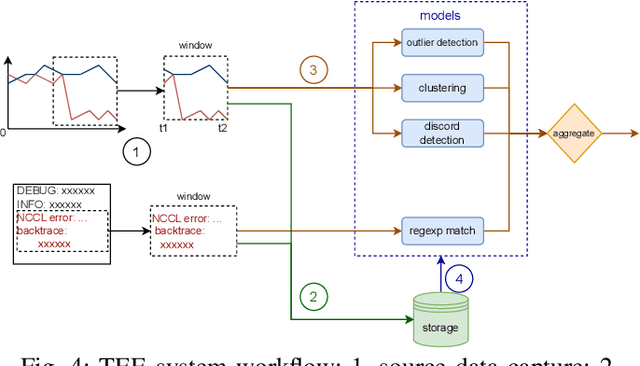
Large language models (LLMs) with hundreds of billions or trillions of parameters, represented by chatGPT, have achieved profound impact on various fields. However, training LLMs with super-large-scale parameters requires large high-performance GPU clusters and long training periods lasting for months. Due to the inevitable hardware and software failures in large-scale clusters, maintaining uninterrupted and long-duration training is extremely challenging. As a result, A substantial amount of training time is devoted to task checkpoint saving and loading, task rescheduling and restart, and task manual anomaly checks, which greatly harms the overall training efficiency. To address these issues, we propose TRANSOM, a novel fault-tolerant LLM training system. In this work, we design three key subsystems: the training pipeline automatic fault tolerance and recovery mechanism named Transom Operator and Launcher (TOL), the training task multi-dimensional metric automatic anomaly detection system named Transom Eagle Eye (TEE), and the training checkpoint asynchronous access automatic fault tolerance and recovery technology named Transom Checkpoint Engine (TCE). Here, TOL manages the lifecycle of training tasks, while TEE is responsible for task monitoring and anomaly reporting. TEE detects training anomalies and reports them to TOL, who automatically enters the fault tolerance strategy to eliminate abnormal nodes and restart the training task. And the asynchronous checkpoint saving and loading functionality provided by TCE greatly shorten the fault tolerance overhead. The experimental results indicate that TRANSOM significantly enhances the efficiency of large-scale LLM training on clusters. Specifically, the pre-training time for GPT3-175B has been reduced by 28%, while checkpoint saving and loading performance have improved by a factor of 20.