 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualization of Machine Learning Models through Their Spatial and Temporal Listeners
Mar 29, 2026Model visualization (ModelVis) has emerged as a major research direction, yet existing taxonomies are largely organized by data or tasks, making it difficult to treat models as first-class analysis objects. We present a model-centric two-stage framework that employs abstract listeners to capture spatial and temporal model behaviors, and then connects the translated model behavior data to the classical InfoVis pipeline. To apply the framework at scale, we build a retrieval-augmented human--large language model (LLM) extraction workflow and curate a corpus of 128 VIS/VAST ModelVis papers with 331 coded figures. Our analysis shows a dominant result-centric priority on visualizing model outcomes, quantitative/nominal data type, statistical charts, and performance evaluation. Citation-weighted trends further indicate that less frequent model-mechanism-oriented studies have disproportionately high impact while are less investigated recently. Overall, the framework is a general approach for comparing existing ModelVis systems and guiding possible future designs.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025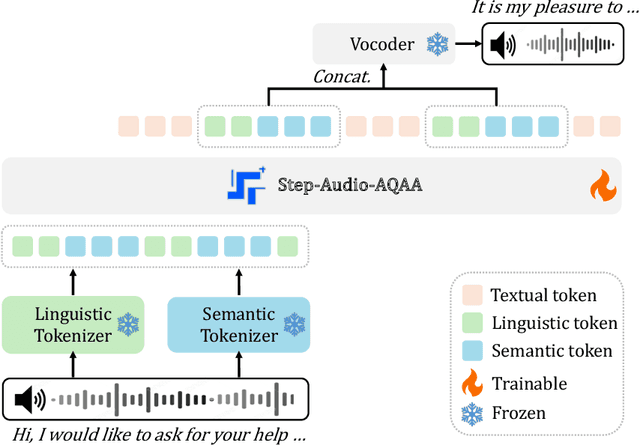
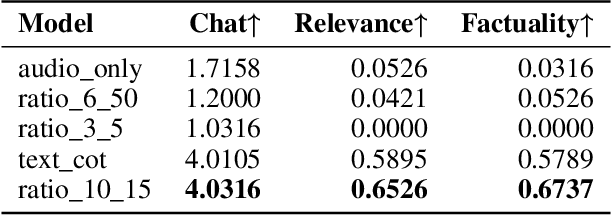
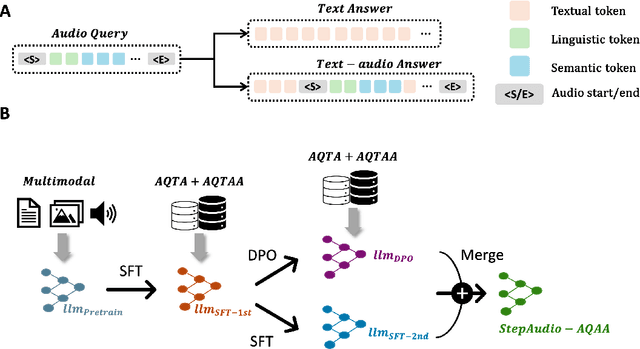

Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
Step1X-Edit: A Practical Framework for General Image Editing
Apr 24, 2025In recent years, image editing models have witnessed remarkable and rapid development. The recent unveiling of cutting-edge multimodal models such as GPT-4o and Gemini2 Flash has introduced highly promising image editing capabilities. These models demonstrate an impressive aptitude for fulfilling a vast majority of user-driven editing requirements, marking a significant advancement in the field of image manipulation. However, there is still a large gap between the open-source algorithm with these closed-source models. Thus, in this paper, we aim to release a state-of-the-art image editing model, called Step1X-Edit, which can provide comparable performance against the closed-source models like GPT-4o and Gemini2 Flash. More specifically, we adopt the Multimodal LLM to process the reference image and the user's editing instruction. A latent embedding has been extracted and integrated with a diffusion image decoder to obtain the target image. To train the model, we build a data generation pipeline to produce a high-quality dataset. For evaluation, we develop the GEdit-Bench, a novel benchmark rooted in real-world user instructions. Experimental results on GEdit-Bench demonstrate that Step1X-Edit outperforms existing open-source baselines by a substantial margin and approaches the performance of leading proprietary models, thereby making significant contributions to the field of image editing.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
Document-level Causal Relation Extraction with Knowledge-guided Binary Question Answering
Oct 07, 2024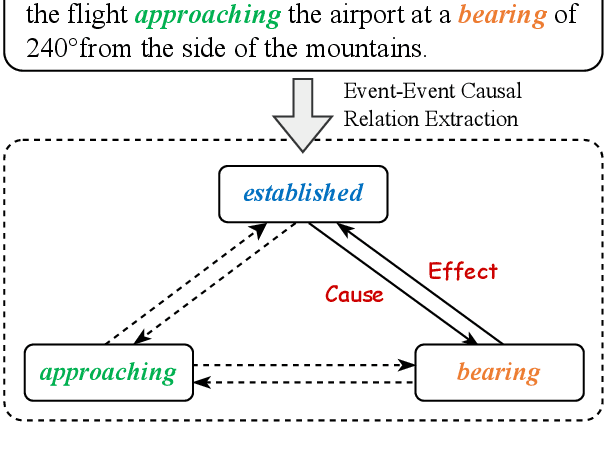
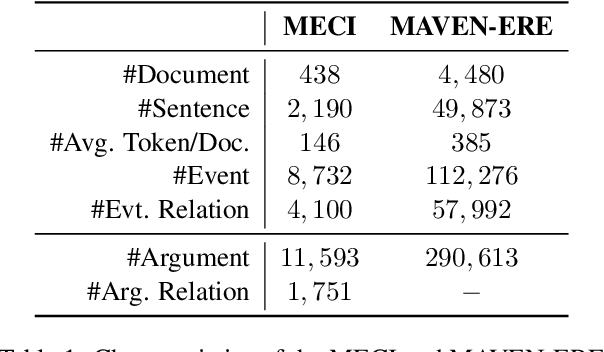
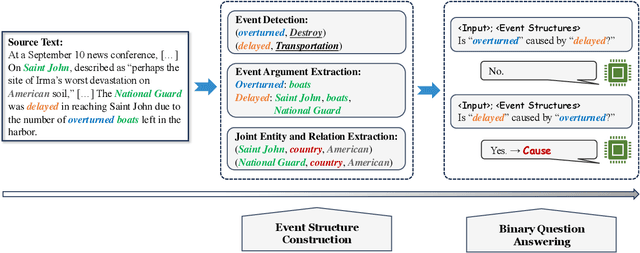
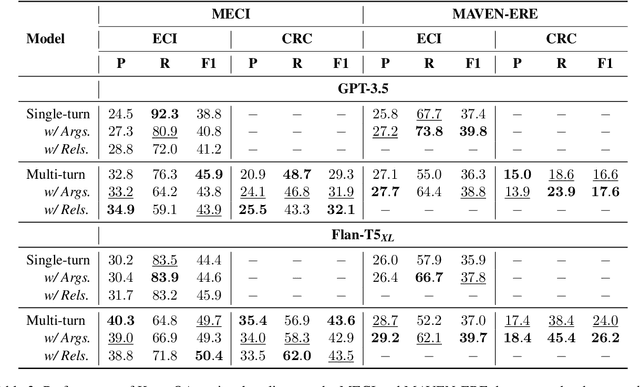
As an essential task in information extraction (IE), Event-Event Causal Relation Extraction (ECRE) aims to identify and classify the causal relationships between event mentions in natural language texts. However, existing research on ECRE has highlighted two critical challenges, including the lack of document-level modeling and causal hallucinations. In this paper, we propose a Knowledge-guided binary Question Answering (KnowQA) method with event structures for ECRE, consisting of two stages: Event Structure Construction and Binary Question Answering. We conduct extensive experiments under both zero-shot and fine-tuning settings with large language models (LLMs) on the MECI and MAVEN-ERE datasets. Experimental results demonstrate the usefulness of event structures on document-level ECRE and the effectiveness of KnowQA by achieving state-of-the-art on the MECI dataset. We observe not only the effectiveness but also the high generalizability and low inconsistency of our method, particularly when with complete event structures after fine-tuning the models.
TRANSOM: An Efficient Fault-Tolerant System for Training LLMs
Oct 18, 2023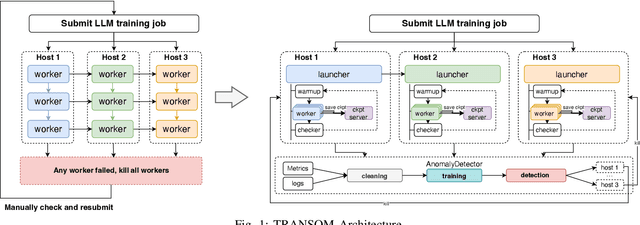
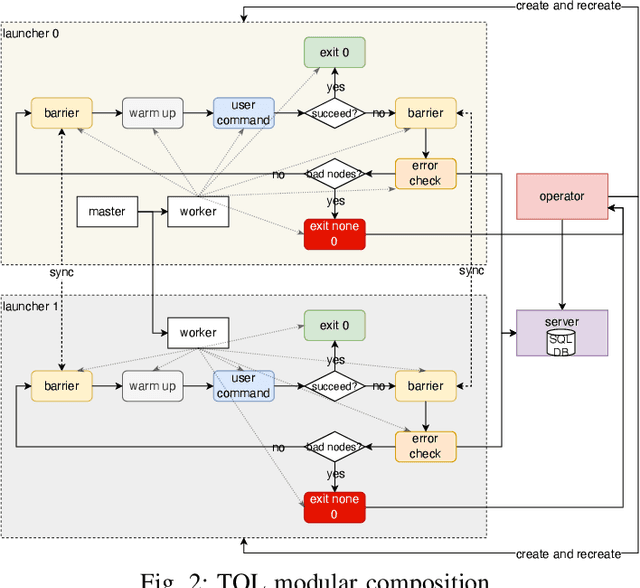
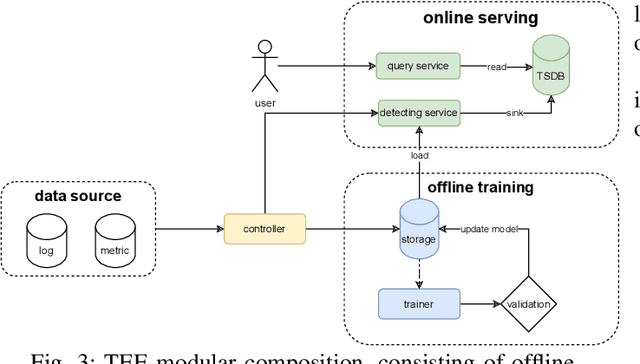
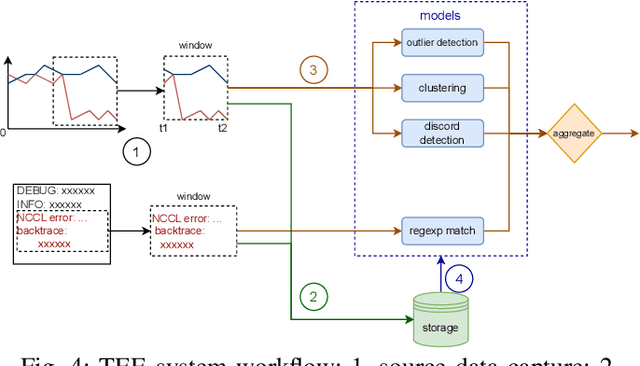
Large language models (LLMs) with hundreds of billions or trillions of parameters, represented by chatGPT, have achieved profound impact on various fields. However, training LLMs with super-large-scale parameters requires large high-performance GPU clusters and long training periods lasting for months. Due to the inevitable hardware and software failures in large-scale clusters, maintaining uninterrupted and long-duration training is extremely challenging. As a result, A substantial amount of training time is devoted to task checkpoint saving and loading, task rescheduling and restart, and task manual anomaly checks, which greatly harms the overall training efficiency. To address these issues, we propose TRANSOM, a novel fault-tolerant LLM training system. In this work, we design three key subsystems: the training pipeline automatic fault tolerance and recovery mechanism named Transom Operator and Launcher (TOL), the training task multi-dimensional metric automatic anomaly detection system named Transom Eagle Eye (TEE), and the training checkpoint asynchronous access automatic fault tolerance and recovery technology named Transom Checkpoint Engine (TCE). Here, TOL manages the lifecycle of training tasks, while TEE is responsible for task monitoring and anomaly reporting. TEE detects training anomalies and reports them to TOL, who automatically enters the fault tolerance strategy to eliminate abnormal nodes and restart the training task. And the asynchronous checkpoint saving and loading functionality provided by TCE greatly shorten the fault tolerance overhead. The experimental results indicate that TRANSOM significantly enhances the efficiency of large-scale LLM training on clusters. Specifically, the pre-training time for GPT3-175B has been reduced by 28%, while checkpoint saving and loading performance have improved by a factor of 20.
Transaction Fraud Detection Using GRU-centered Sandwich-structured Model
Mar 19, 2018



Rapid growth of modern technologies such as internet and mobile computing are bringing dramatically increased e-commerce payments, as well as the explosion in transaction fraud. Meanwhile, fraudsters are continually refining their tricks, making rule-based fraud detection systems difficult to handle the ever-changing fraud patterns. Many data mining and artificial intelligence methods have been proposed for identifying small anomalies in large transaction data sets, increasing detecting efficiency to some extent. Nevertheless, there is always a contradiction that most methods are irrelevant to transaction sequence, yet sequence-related methods usually cannot learn information at single-transaction level well. In this paper, a new "within->between->within" sandwich-structured sequence learning architecture has been proposed by stacking an ensemble method, a deep sequential learning method and another top-layer ensemble classifier in proper order. Moreover, attention mechanism has also been introduced in to further improve performance. Models in this structure have been manifested to be very efficient in scenarios like fraud detection, where the information sequence is made up of vectors with complex interconnected features.