 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoPA: Benchmarking Personalized Question Answering with Data-Informed Cognitive Factors
Apr 16, 2026While LLMs have demonstrated remarkable potential in Question Answering (QA), evaluating personalization remains a critical bottleneck. Existing paradigms predominantly rely on lexical-level similarity or manual heuristics, often lacking sufficient data-driven validation. We address this by mining Community-Individual Preference Divergence (CIPD), where individual choices override consensus, to distill six key personalization factors as evaluative dimensions. Accordingly, we introduce CoPA, a benchmark with 1,985 user profiles for fine-grained, factor-level assessment. By quantifying the alignment between model outputs and user-specific cognitive preferences inferred from interaction patterns, CoPA provides a more comprehensive and discriminative standard for evaluating personalized QA than generic metrics. The code is available at https://github.com/bjzgcai/CoPA.
MIXAR: Scaling Autoregressive Pixel-based Language Models to Multiple Languages and Scripts
Apr 13, 2026Pixel-based language models are gaining momentum as alternatives to traditional token-based approaches, promising to circumvent tokenization challenges. However, the inherent perceptual diversity across languages poses a significant hurdle for multilingual generalization in pixel space. This paper introduces MIXAR, the first generative pixel-based language model trained on eight different languages utilizing a range of different scripts. We empirically evaluate MIXAR against previous pixel-based models as well as comparable tokenizer-based models, demonstrating substantial performance improvement on discriminative and generative multilingual tasks. Additionally, we show how MIXAR is robust to languages never seen during the training. These results are further strengthened when scaling the model to 0.5B parameters which not only improves its capabilities in generative tasks like LAMBADA but also its robustness when challenged with input perturbations such as orthographic attacks.
Radiology Report Generation for Low-Quality X-Ray Images
Apr 11, 2026Vision-Language Models (VLMs) have significantly advanced automated Radiology Report Generation (RRG). However, existing methods implicitly assume high-quality inputs, overlooking the noise and artifacts prevalent in real-world clinical environments. Consequently, current models exhibit severe performance degradation when processing suboptimal images. To bridge this gap, we propose a robust report generation framework explicitly designed for image quality variations. We first introduce an Automated Quality Assessment Agent (AQAA) to identify low-quality samples within the MIMIC-CXR dataset and establish the Low-quality Radiology Report Generation (LRRG) benchmark. To tackle degradation-induced shifts, we propose a novel Dual-loop Training Strategy leveraging bi-level optimization and gradient consistency. This approach ensures the model learns quality-agnostic diagnostic features by aligning gradient directions across varying quality regimes. Extensive experiments demonstrate that our approach effectively mitigates model performance degradation caused by image quality deterioration. The code and data will be released upon acceptance.
MedPruner: Training-Free Hierarchical Token Pruning for Efficient 3D Medical Image Understanding in Vision-Language Models
Mar 12, 2026While specialized Medical Vision-Language Models (VLMs) have achieved remarkable success in interpreting 2D and 3D medical modalities, their deployment for 3D volumetric data remains constrained by significant computational inefficiencies. Current architectures typically suffer from massive anatomical redundancy due to the direct concatenation of consecutive 2D slices and lack the flexibility to handle heterogeneous information densities across different slices using fixed pruning ratios. To address these challenges, we propose MedPruner, a training-free and model-agnostic hierarchical token pruning framework specifically designed for efficient 3D medical image understanding. MedPruner introduces a two-stage mechanism: an Inter-slice Anchor-based Filtering module to eliminate slice-level temporal redundancy, followed by a Dynamic Information Nucleus Selection strategy that achieves adaptive token-level compression by quantifying cumulative attention weights. Extensive experiments on three 3D medical benchmarks and across three diverse medical VLMs reveal massive token redundancy in existing architectures. Notably, MedPruner enables models such as MedGemma to maintain or even exceed their original performance while retaining fewer than 5% of visual tokens, thereby drastically reducing computational overhead and validating the necessity of dynamic token selection for practical clinical deployment. Our code will be released.
SpotAgent: Grounding Visual Geo-localization in Large Vision-Language Models through Agentic Reasoning
Feb 11, 2026Large Vision-Language Models (LVLMs) have demonstrated strong reasoning capabilities in geo-localization, yet they often struggle in real-world scenarios where visual cues are sparse, long-tailed, and highly ambiguous. Previous approaches, bound by internal knowledge, often fail to provide verifiable results, yielding confident but ungrounded predictions when faced with confounded evidence. To address these challenges, we propose SpotAgent, a framework that formalizes geo-localization into an agentic reasoning process that leverages expert-level reasoning to synergize visual interpretation with tool-assisted verification. SpotAgent actively explores and verifies visual cues by leveraging external tools (e.g., web search, maps) through a ReAct diagram. We introduce a 3-stage post-training pipeline starting with a Supervised Fine-Tuning (SFT) stage for basic alignment, followed by an Agentic Cold Start phase utilizing high-quality trajectories synthesized via a Multi-Agent framework, aiming to instill tool-calling expertise. Subsequently, the model's reasoning capabilities are refined through Reinforcement Learning. We propose a Spatially-Aware Dynamic Filtering strategy to enhance the efficiency of the RL stage by prioritizing learnable samples based on spatial difficulty. Extensive experiments on standard benchmarks demonstrate that SpotAgent achieves state-of-the-art performance, effectively mitigating hallucinations while delivering precise and verifiable geo-localization.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
OVGrasp: Open-Vocabulary Grasping Assistance via Multimodal Intent Detection
Sep 04, 2025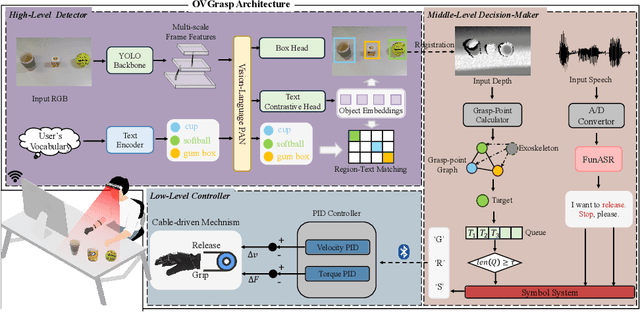
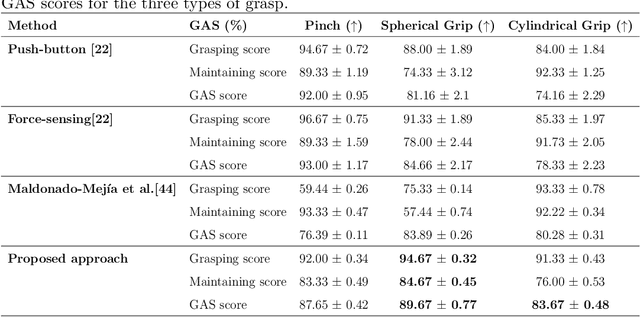

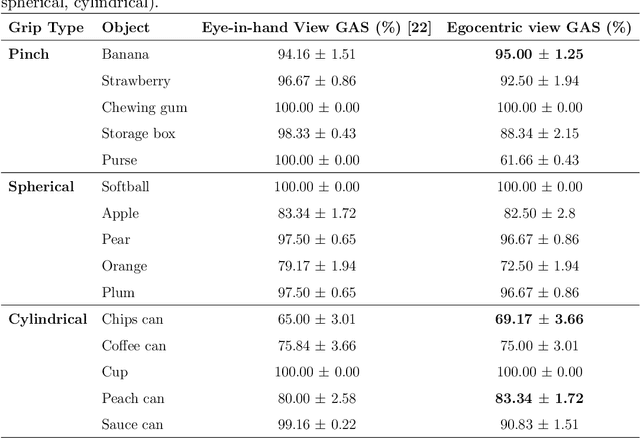
Grasping assistance is essential for restoring autonomy in individuals with motor impairments, particularly in unstructured environments where object categories and user intentions are diverse and unpredictable. We present OVGrasp, a hierarchical control framework for soft exoskeleton-based grasp assistance that integrates RGB-D vision, open-vocabulary prompts, and voice commands to enable robust multimodal interaction. To enhance generalization in open environments, OVGrasp incorporates a vision-language foundation model with an open-vocabulary mechanism, allowing zero-shot detection of previously unseen objects without retraining. A multimodal decision-maker further fuses spatial and linguistic cues to infer user intent, such as grasp or release, in multi-object scenarios. We deploy the complete framework on a custom egocentric-view wearable exoskeleton and conduct systematic evaluations on 15 objects across three grasp types. Experimental results with ten participants demonstrate that OVGrasp achieves a grasping ability score (GAS) of 87.00%, outperforming state-of-the-art baselines and achieving improved kinematic alignment with natural hand motion.
GitTaskBench: A Benchmark for Code Agents Solving Real-World Tasks Through Code Repository Leveraging
Aug 26, 2025

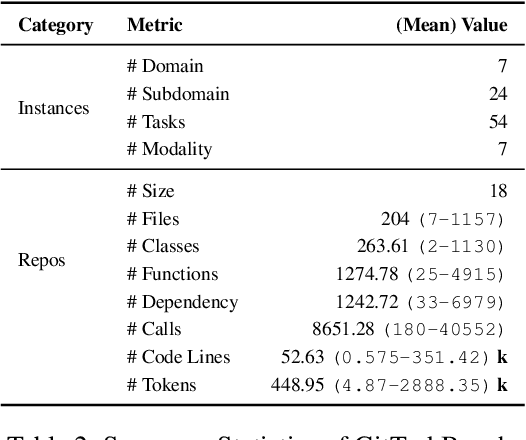
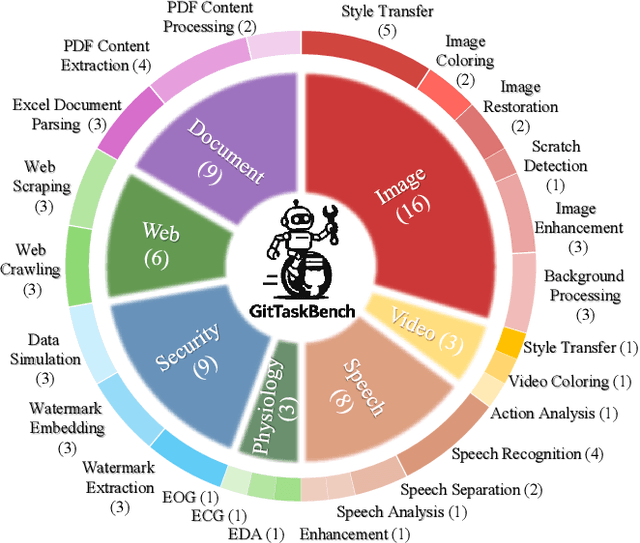
Beyond scratch coding, exploiting large-scale code repositories (e.g., GitHub) for practical tasks is vital in real-world software development, yet current benchmarks rarely evaluate code agents in such authentic, workflow-driven scenarios. To bridge this gap, we introduce GitTaskBench, a benchmark designed to systematically assess this capability via 54 realistic tasks across 7 modalities and 7 domains. Each task pairs a relevant repository with an automated, human-curated evaluation harness specifying practical success criteria. Beyond measuring execution and task success, we also propose the alpha-value metric to quantify the economic benefit of agent performance, which integrates task success rates, token cost, and average developer salaries. Experiments across three state-of-the-art agent frameworks with multiple advanced LLMs show that leveraging code repositories for complex task solving remains challenging: even the best-performing system, OpenHands+Claude 3.7, solves only 48.15% of tasks. Error analysis attributes over half of failures to seemingly mundane yet critical steps like environment setup and dependency resolution, highlighting the need for more robust workflow management and increased timeout preparedness. By releasing GitTaskBench, we aim to drive progress and attention toward repository-aware code reasoning, execution, and deployment -- moving agents closer to solving complex, end-to-end real-world tasks. The benchmark and code are open-sourced at https://github.com/QuantaAlpha/GitTaskBench.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.