 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025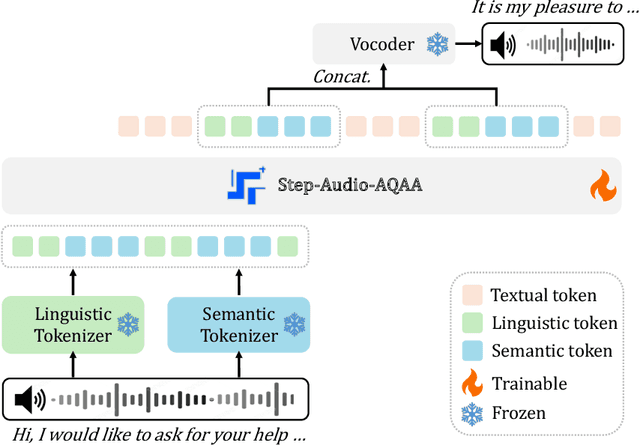
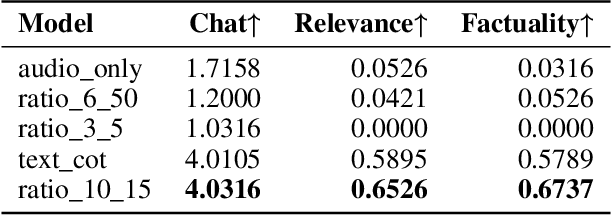
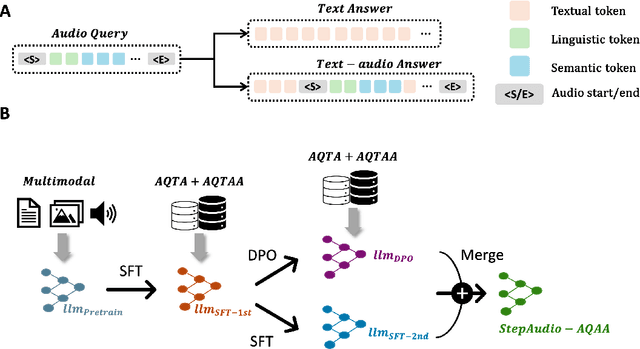

Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
Unearthing Gems from Stones: Policy Optimization with Negative Sample Augmentation for LLM Reasoning
May 20, 2025Recent advances in reasoning language models have witnessed a paradigm shift from short to long CoT pattern. Given the substantial computational cost of rollouts in long CoT models, maximizing the utility of fixed training datasets becomes crucial. Our analysis reveals that negative responses contain valuable components such as self-reflection and error-correction steps, yet primary existing methods either completely discard negative samples (RFT) or apply equal penalization across all tokens (RL), failing to leverage these potential learning signals. In light of this, we propose Behavior Constrained Policy Gradient with Negative Sample Augmentation (BCPG-NSA), a fine-grained offline RL framework that encompasses three stages: 1) sample segmentation, 2) consensus-based step correctness assessment combining LLM and PRM judgers, and 3) policy optimization with NSA designed to effectively mine positive steps within negative samples. Experimental results show that BCPG-NSA outperforms baselines on several challenging math/coding reasoning benchmarks using the same training dataset, achieving improved sample efficiency and demonstrating robustness and scalability when extended to multiple iterations.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
Probability Density Estimation Based Imitation Learning
Dec 13, 2021
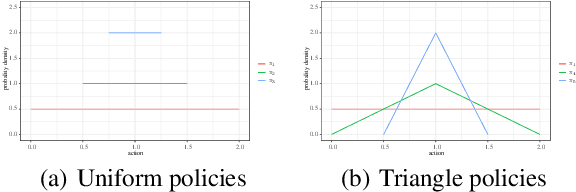


Imitation Learning (IL) is an effective learning paradigm exploiting the interactions between agents and environments. It does not require explicit reward signals and instead tries to recover desired policies using expert demonstrations. In general, IL methods can be categorized into Behavioral Cloning (BC) and Inverse Reinforcement Learning (IRL). In this work, a novel reward function based on probability density estimation is proposed for IRL, which can significantly reduce the complexity of existing IRL methods. Furthermore, we prove that the theoretically optimal policy derived from our reward function is identical to the expert policy as long as it is deterministic. Consequently, an IRL problem can be gracefully transformed into a probability density estimation problem. Based on the proposed reward function, we present a "watch-try-learn" style framework named Probability Density Estimation based Imitation Learning (PDEIL), which can work in both discrete and continuous action spaces. Finally, comprehensive experiments in the Gym environment show that PDEIL is much more efficient than existing algorithms in recovering rewards close to the ground truth.