 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxRole: A Comprehensive Benchmark for Evaluating Speech-Based Role-Playing Agents
Sep 04, 2025Recent significant advancements in Large Language Models (LLMs) have greatly propelled the development of Role-Playing Conversational Agents (RPCAs). These systems aim to create immersive user experiences through consistent persona adoption. However, current RPCA research faces dual limitations. First, existing work predominantly focuses on the textual modality, entirely overlooking critical paralinguistic features including intonation, prosody, and rhythm in speech, which are essential for conveying character emotions and shaping vivid identities. Second, the speech-based role-playing domain suffers from a long-standing lack of standardized evaluation benchmarks. Most current spoken dialogue datasets target only fundamental capability assessments, featuring thinly sketched or ill-defined character profiles. Consequently, they fail to effectively quantify model performance on core competencies like long-term persona consistency. To address this critical gap, we introduce VoxRole, the first comprehensive benchmark specifically designed for the evaluation of speech-based RPCAs. The benchmark comprises 13335 multi-turn dialogues, totaling 65.6 hours of speech from 1228 unique characters across 261 movies. To construct this resource, we propose a novel two-stage automated pipeline that first aligns movie audio with scripts and subsequently employs an LLM to systematically build multi-dimensional profiles for each character. Leveraging VoxRole, we conduct a multi-dimensional evaluation of contemporary spoken dialogue models, revealing crucial insights into their respective strengths and limitations in maintaining persona consistency.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025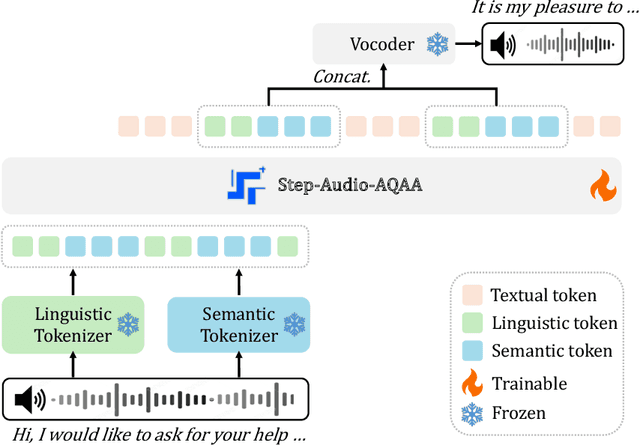
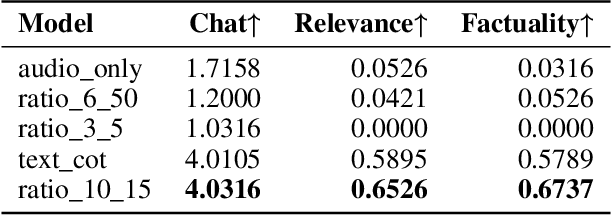
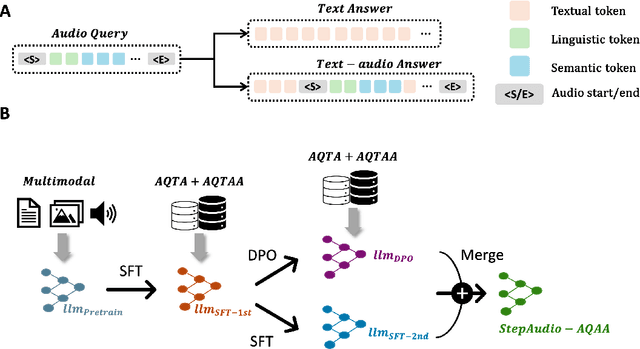

Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
DiffCSS: Diverse and Expressive Conversational Speech Synthesis with Diffusion Models
Feb 27, 2025



Conversational speech synthesis (CSS) aims to synthesize both contextually appropriate and expressive speech, and considerable efforts have been made to enhance the understanding of conversational context. However, existing CSS systems are limited to deterministic prediction, overlooking the diversity of potential responses. Moreover, they rarely employ language model (LM)-based TTS backbones, limiting the naturalness and quality of synthesized speech. To address these issues, in this paper, we propose DiffCSS, an innovative CSS framework that leverages diffusion models and an LM-based TTS backbone to generate diverse, expressive, and contextually coherent speech. A diffusion-based context-aware prosody predictor is proposed to sample diverse prosody embeddings conditioned on multimodal conversational context. Then a prosody-controllable LM-based TTS backbone is developed to synthesize high-quality speech with sampled prosody embeddings. Experimental results demonstrate that the synthesized speech from DiffCSS is more diverse, contextually coherent, and expressive than existing CSS systems
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
DiCLET-TTS: Diffusion Model based Cross-lingual Emotion Transfer for Text-to-Speech -- A Study between English and Mandarin
Sep 02, 2023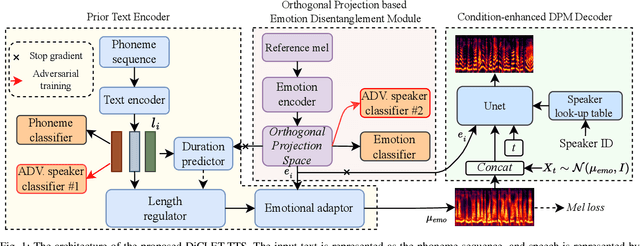
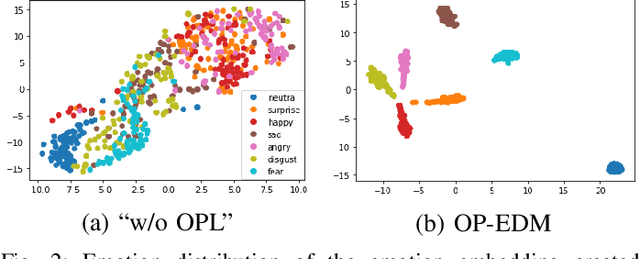
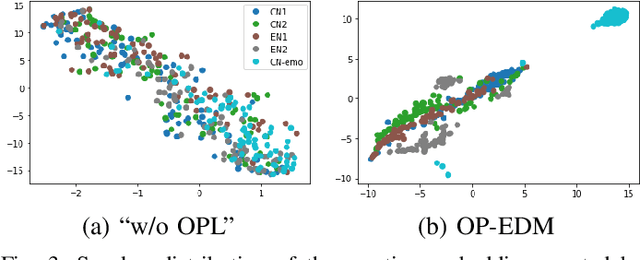
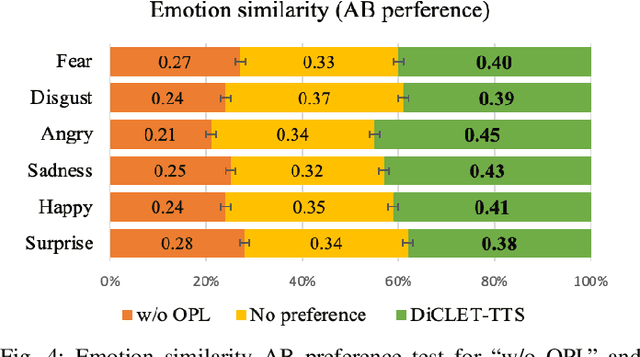
While the performance of cross-lingual TTS based on monolingual corpora has been significantly improved recently, generating cross-lingual speech still suffers from the foreign accent problem, leading to limited naturalness. Besides, current cross-lingual methods ignore modeling emotion, which is indispensable paralinguistic information in speech delivery. In this paper, we propose DiCLET-TTS, a Diffusion model based Cross-Lingual Emotion Transfer method that can transfer emotion from a source speaker to the intra- and cross-lingual target speakers. Specifically, to relieve the foreign accent problem while improving the emotion expressiveness, the terminal distribution of the forward diffusion process is parameterized into a speaker-irrelevant but emotion-related linguistic prior by a prior text encoder with the emotion embedding as a condition. To address the weaker emotional expressiveness problem caused by speaker disentanglement in emotion embedding, a novel orthogonal projection based emotion disentangling module (OP-EDM) is proposed to learn the speaker-irrelevant but emotion-discriminative embedding. Moreover, a condition-enhanced DPM decoder is introduced to strengthen the modeling ability of the speaker and the emotion in the reverse diffusion process to further improve emotion expressiveness in speech delivery. Cross-lingual emotion transfer experiments show the superiority of DiCLET-TTS over various competitive models and the good design of OP-EDM in learning speaker-irrelevant but emotion-discriminative embedding.
Joint Multi-scale Cross-lingual Speaking Style Transfer with Bidirectional Attention Mechanism for Automatic Dubbing
May 09, 2023Automatic dubbing, which generates a corresponding version of the input speech in another language, could be widely utilized in many real-world scenarios such as video and game localization. In addition to synthesizing the translated scripts, automatic dubbing needs to further transfer the speaking style in the original language to the dubbed speeches to give audiences the impression that the characters are speaking in their native tongue. However, state-of-the-art automatic dubbing systems only model the transfer on duration and speaking rate, neglecting the other aspects in speaking style such as emotion, intonation and emphasis which are also crucial to fully perform the characters and speech understanding. In this paper, we propose a joint multi-scale cross-lingual speaking style transfer framework to simultaneously model the bidirectional speaking style transfer between languages at both global (i.e. utterance level) and local (i.e. word level) scales. The global and local speaking styles in each language are extracted and utilized to predicted the global and local speaking styles in the other language with an encoder-decoder framework for each direction and a shared bidirectional attention mechanism for both directions. A multi-scale speaking style enhanced FastSpeech 2 is then utilized to synthesize the predicted the global and local speaking styles to speech for each language. Experiment results demonstrate the effectiveness of our proposed framework, which outperforms a baseline with only duration transfer in both objective and subjective evaluations.
NeuFA: Neural Network Based End-to-End Forced Alignment with Bidirectional Attention Mechanism
Mar 31, 2022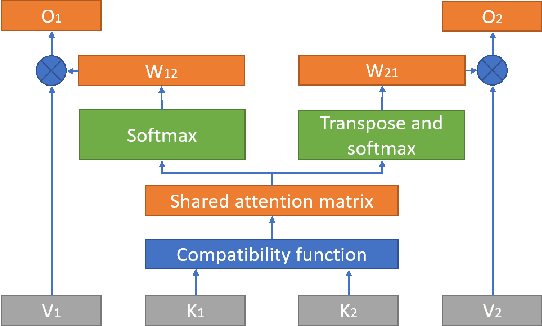
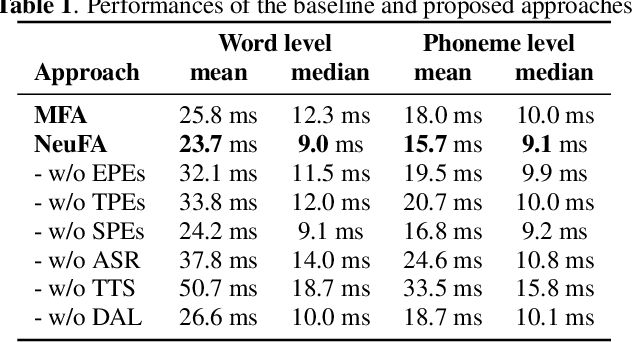
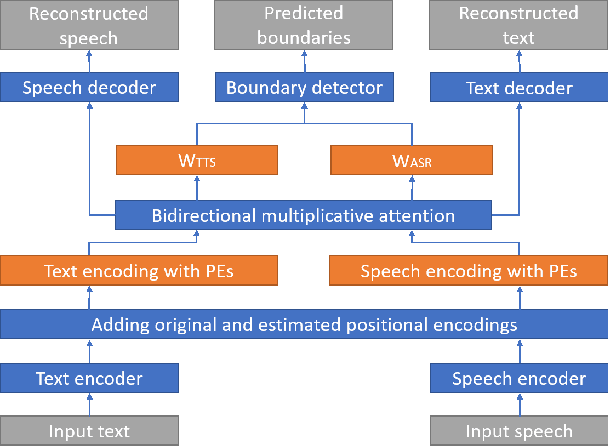
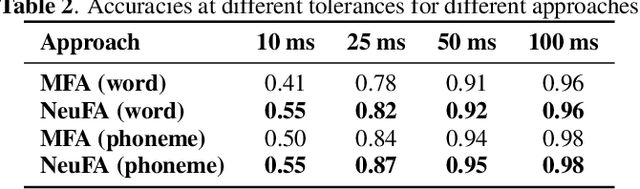
Although deep learning and end-to-end models have been widely used and shown superiority in automatic speech recognition (ASR) and text-to-speech (TTS) synthesis, state-of-the-art forced alignment (FA) models are still based on hidden Markov model (HMM). HMM has limited view of contextual information and is developed with long pipelines, leading to error accumulation and unsatisfactory performance. Inspired by the capability of attention mechanism in capturing long term contextual information and learning alignments in ASR and TTS, we propose a neural network based end-to-end forced aligner called NeuFA, in which a novel bidirectional attention mechanism plays an essential role. NeuFA integrates the alignment learning of both ASR and TTS tasks in a unified framework by learning bidirectional alignment information from a shared attention matrix in the proposed bidirectional attention mechanism. Alignments are extracted from the learnt attention weights and optimized by the ASR, TTS and FA tasks in a multi-task learning manner. Experimental results demonstrate the effectiveness of our proposed model, with mean absolute error on test set drops from 25.8 ms to 23.7 ms at word level, and from 17.0 ms to 15.7 ms at phoneme level compared with state-of-the-art HMM based model.
Spoken Style Learning with Multi-modal Hierarchical Context Encoding for Conversational Text-to-Speech Synthesis
Jun 11, 2021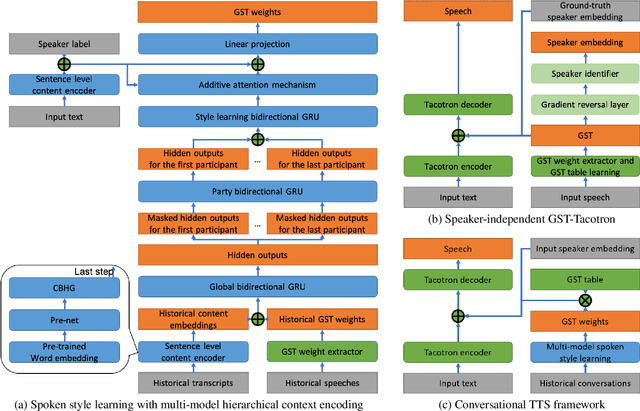

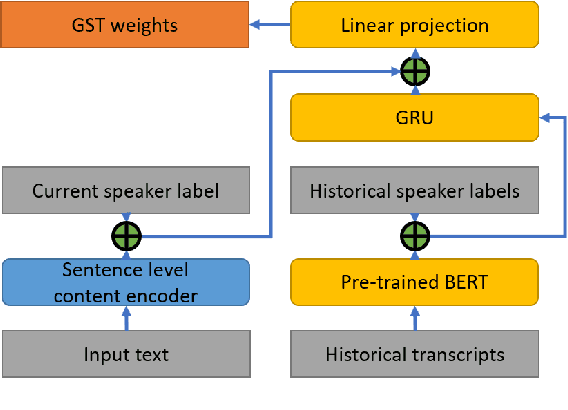

For conversational text-to-speech (TTS) systems, it is vital that the systems can adjust the spoken styles of synthesized speech according to different content and spoken styles in historical conversations. However, the study about learning spoken styles from historical conversations is still in its infancy. Only the transcripts of the historical conversations are considered, which neglects the spoken styles in historical speeches. Moreover, only the interactions of the global aspect between speakers are modeled, missing the party aspect self interactions inside each speaker. In this paper, to achieve better spoken style learning for conversational TTS, we propose a spoken style learning approach with multi-modal hierarchical context encoding. The textual information and spoken styles in the historical conversations are processed through multiple hierarchical recurrent neural networks to learn the spoken style related features in global and party aspects. The attention mechanism is further employed to summarize these features into a conversational context encoding. Experimental results demonstrate the effectiveness of our proposed approach, which outperform a baseline method using context encoding learnt only from the transcripts in global aspects, with MOS score on the naturalness of synthesized speech increasing from 3.138 to 3.408 and ABX preference rate exceeding the baseline method by 36.45%.
Dependency Parsing based Semantic Representation Learning with Graph Neural Network for Enhancing Expressiveness of Text-to-Speech
Apr 20, 2021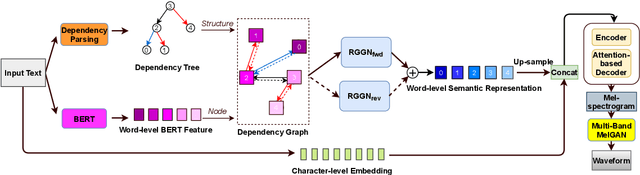



Semantic information of a sentence is crucial for improving the expressiveness of a text-to-speech (TTS) system, but can not be well learned from the limited training TTS dataset just by virtue of the nowadays encoder structures. As large scale pre-trained text representation develops, bidirectional encoder representations from transformers (BERT) has been proven to embody text-context semantic information and applied to TTS as additional input. However BERT can not explicitly associate semantic tokens from point of dependency relations in a sentence. In this paper, to enhance expressiveness, we propose a semantic representation learning method based on graph neural network, considering dependency relations of a sentence. Dependency graph of input text is composed of edges from dependency tree structure considering both the forward and the reverse directions. Semantic representations are then extracted at word level by the relational gated graph network (RGGN) fed with features from BERT as nodes input. Upsampled semantic representations and character-level embeddings are concatenated to serve as the encoder input of Tacotron-2. Experimental results show that our proposed method outperforms the baseline using vanilla BERT features both in LJSpeech and Blizzard Challenge 2013 datasets, and semantic representations learned from the reverse direction are more effective for enhancing expressiveness.