 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowSE: Efficient and High-Quality Speech Enhancement via Flow Matching
May 26, 2025Generative models have excelled in audio tasks using approaches such as language models, diffusion, and flow matching. However, existing generative approaches for speech enhancement (SE) face notable challenges: language model-based methods suffer from quantization loss, leading to compromised speaker similarity and intelligibility, while diffusion models require complex training and high inference latency. To address these challenges, we propose FlowSE, a flow-matching-based model for SE. Flow matching learns a continuous transformation between noisy and clean speech distributions in a single pass, significantly reducing inference latency while maintaining high-quality reconstruction. Specifically, FlowSE trains on noisy mel spectrograms and optional character sequences, optimizing a conditional flow matching loss with ground-truth mel spectrograms as supervision. It implicitly learns speech's temporal-spectral structure and text-speech alignment. During inference, FlowSE can operate with or without textual information, achieving impressive results in both scenarios, with further improvements when transcripts are available. Extensive experiments demonstrate that FlowSE significantly outperforms state-of-the-art generative methods, establishing a new paradigm for generative-based SE and demonstrating the potential of flow matching to advance the field. Our code, pre-trained checkpoints, and audio samples are available.
DurIAN-E 2: Duration Informed Attention Network with Adaptive Variational Autoencoder and Adversarial Learning for Expressive Text-to-Speech Synthesis
Oct 17, 2024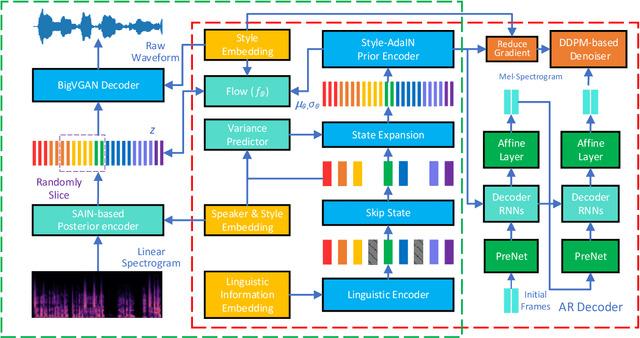
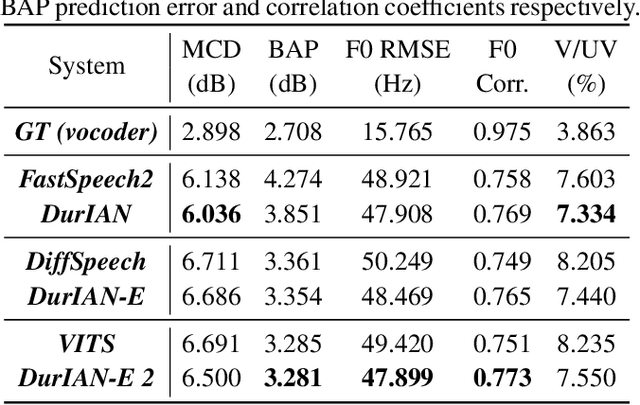
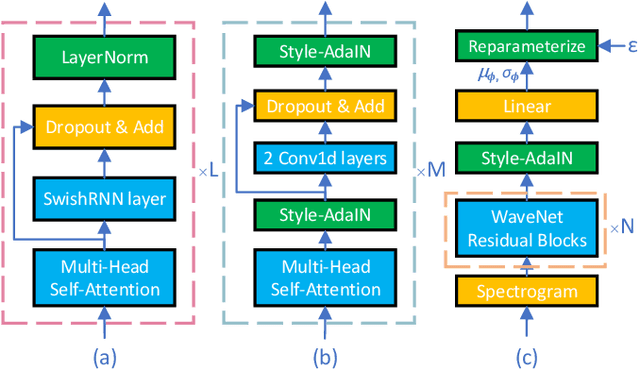

This paper proposes an improved version of DurIAN-E (DurIAN-E 2), which is also a duration informed attention neural network for expressive and high-fidelity text-to-speech (TTS) synthesis. Similar with the DurIAN-E model, multiple stacked SwishRNN-based Transformer blocks are utilized as linguistic encoders and Style-Adaptive Instance Normalization (SAIN) layers are also exploited into frame-level encoders to improve the modeling ability of expressiveness in the proposed the DurIAN-E 2. Meanwhile, motivated by other TTS models using generative models such as VITS, the proposed DurIAN-E 2 utilizes variational autoencoders (VAEs) augmented with normalizing flows and a BigVGAN waveform generator with adversarial training strategy, which further improve the synthesized speech quality and expressiveness. Both objective test and subjective evaluation results prove that the proposed expressive TTS model DurIAN-E 2 can achieve better performance than several state-of-the-art approaches besides DurIAN-E.
SiFiSinger: A High-Fidelity End-to-End Singing Voice Synthesizer based on Source-filter Model
Oct 16, 2024



This paper presents an advanced end-to-end singing voice synthesis (SVS) system based on the source-filter mechanism that directly translates lyrical and melodic cues into expressive and high-fidelity human-like singing. Similarly to VISinger 2, the proposed system also utilizes training paradigms evolved from VITS and incorporates elements like the fundamental pitch (F0) predictor and waveform generation decoder. To address the issue that the coupling of mel-spectrogram features with F0 information may introduce errors during F0 prediction, we consider two strategies. Firstly, we leverage mel-cepstrum (mcep) features to decouple the intertwined mel-spectrogram and F0 characteristics. Secondly, inspired by the neural source-filter models, we introduce source excitation signals as the representation of F0 in the SVS system, aiming to capture pitch nuances more accurately. Meanwhile, differentiable mcep and F0 losses are employed as the waveform decoder supervision to fortify the prediction accuracy of speech envelope and pitch in the generated speech. Experiments on the Opencpop dataset demonstrate efficacy of the proposed model in synthesis quality and intonation accuracy.
Gull: A Generative Multifunctional Audio Codec
Apr 07, 2024



We introduce Gull, a generative multifunctional audio codec. Gull is a general purpose neural audio compression and decompression model which can be applied to a wide range of tasks and applications such as real-time communication, audio super-resolution, and codec language models. The key components of Gull include (1) universal-sample-rate modeling via subband modeling schemes motivated by recent progress in audio source separation, (2) gain-shape representations motivated by traditional audio codecs, (3) improved residual vector quantization modules for simpler training, (4) elastic decoder network that enables user-defined model size and complexity during inference time, (5) built-in ability for audio super-resolution without the increase of bitrate. We compare Gull with existing traditional and neural audio codecs and show that Gull is able to achieve on par or better performance across various sample rates, bitrates and model complexities in both subjective and objective evaluation metrics.
VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models
Jan 17, 2024



Text-to-video generation aims to produce a video based on a given prompt. Recently, several commercial video models have been able to generate plausible videos with minimal noise, excellent details, and high aesthetic scores. However, these models rely on large-scale, well-filtered, high-quality videos that are not accessible to the community. Many existing research works, which train models using the low-quality WebVid-10M dataset, struggle to generate high-quality videos because the models are optimized to fit WebVid-10M. In this work, we explore the training scheme of video models extended from Stable Diffusion and investigate the feasibility of leveraging low-quality videos and synthesized high-quality images to obtain a high-quality video model. We first analyze the connection between the spatial and temporal modules of video models and the distribution shift to low-quality videos. We observe that full training of all modules results in a stronger coupling between spatial and temporal modules than only training temporal modules. Based on this stronger coupling, we shift the distribution to higher quality without motion degradation by finetuning spatial modules with high-quality images, resulting in a generic high-quality video model. Evaluations are conducted to demonstrate the superiority of the proposed method, particularly in picture quality, motion, and concept composition.
Consistent and Relevant: Rethink the Query Embedding in General Sound Separation
Dec 24, 2023



The query-based audio separation usually employs specific queries to extract target sources from a mixture of audio signals. Currently, most query-based separation models need additional networks to obtain query embedding. In this way, separation model is optimized to be adapted to the distribution of query embedding. However, query embedding may exhibit mismatches with separation models due to inconsistent structures and independent information. In this paper, we present CaRE-SEP, a consistent and relevant embedding network for general sound separation to encourage a comprehensive reconsideration of query usage in audio separation. CaRE-SEP alleviates the potential mismatch between queries and separation in two aspects, including sharing network structure and sharing feature information. First, a Swin-Unet model with a shared encoder is conducted to unify query encoding and sound separation into one model, eliminating the network architecture difference and generating consistent distribution of query and separation features. Second, by initializing CaRE-SEP with a pretrained classification network and allowing gradient backpropagation, the query embedding is optimized to be relevant to the separation feature, further alleviating the feature mismatch problem. Experimental results indicate the proposed CaRE-SEP model substantially improves the performance of separation tasks. Moreover, visualizations validate the potential mismatch and how CaRE-SEP solves it.
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Oct 30, 2023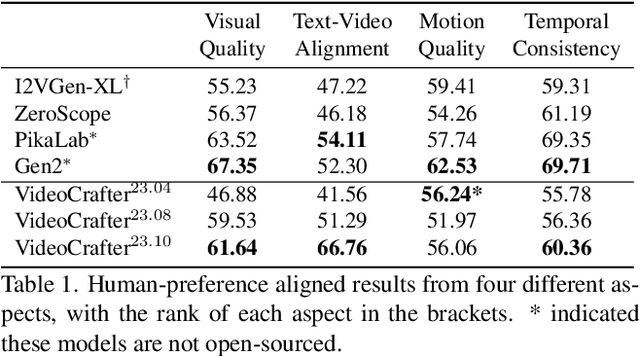

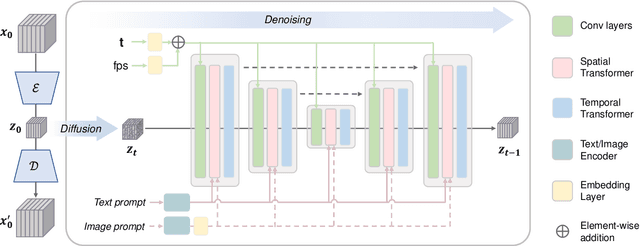
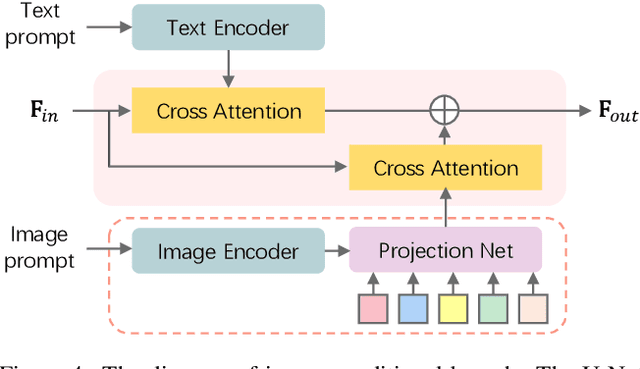
Video generation has increasingly gained interest in both academia and industry. Although commercial tools can generate plausible videos, there is a limited number of open-source models available for researchers and engineers. In this work, we introduce two diffusion models for high-quality video generation, namely text-to-video (T2V) and image-to-video (I2V) models. T2V models synthesize a video based on a given text input, while I2V models incorporate an additional image input. Our proposed T2V model can generate realistic and cinematic-quality videos with a resolution of $1024 \times 576$, outperforming other open-source T2V models in terms of quality. The I2V model is designed to produce videos that strictly adhere to the content of the provided reference image, preserving its content, structure, and style. This model is the first open-source I2V foundation model capable of transforming a given image into a video clip while maintaining content preservation constraints. We believe that these open-source video generation models will contribute significantly to the technological advancements within the community.
DurIAN-E: Duration Informed Attention Network For Expressive Text-to-Speech Synthesis
Sep 22, 2023This paper introduces an improved duration informed attention neural network (DurIAN-E) for expressive and high-fidelity text-to-speech (TTS) synthesis. Inherited from the original DurIAN model, an auto-regressive model structure in which the alignments between the input linguistic information and the output acoustic features are inferred from a duration model is adopted. Meanwhile the proposed DurIAN-E utilizes multiple stacked SwishRNN-based Transformer blocks as linguistic encoders. Style-Adaptive Instance Normalization (SAIN) layers are exploited into frame-level encoders to improve the modeling ability of expressiveness. A denoiser incorporating both denoising diffusion probabilistic model (DDPM) for mel-spectrograms and SAIN modules is conducted to further improve the synthetic speech quality and expressiveness. Experimental results prove that the proposed expressive TTS model in this paper can achieve better performance than the state-of-the-art approaches in both subjective mean opinion score (MOS) and preference tests.
SnakeGAN: A Universal Vocoder Leveraging DDSP Prior Knowledge and Periodic Inductive Bias
Sep 14, 2023



Generative adversarial network (GAN)-based neural vocoders have been widely used in audio synthesis tasks due to their high generation quality, efficient inference, and small computation footprint. However, it is still challenging to train a universal vocoder which can generalize well to out-of-domain (OOD) scenarios, such as unseen speaking styles, non-speech vocalization, singing, and musical pieces. In this work, we propose SnakeGAN, a GAN-based universal vocoder, which can synthesize high-fidelity audio in various OOD scenarios. SnakeGAN takes a coarse-grained signal generated by a differentiable digital signal processing (DDSP) model as prior knowledge, aiming at recovering high-fidelity waveform from a Mel-spectrogram. We introduce periodic nonlinearities through the Snake activation function and anti-aliased representation into the generator, which further brings the desired inductive bias for audio synthesis and significantly improves the extrapolation capacity for universal vocoding in unseen scenarios. To validate the effectiveness of our proposed method, we train SnakeGAN with only speech data and evaluate its performance for various OOD distributions with both subjective and objective metrics. Experimental results show that SnakeGAN significantly outperforms the compared approaches and can generate high-fidelity audio samples including unseen speakers with unseen styles, singing voices, instrumental pieces, and nonverbal vocalization.
Complexity Scaling for Speech Denoising
Sep 14, 2023



Computational complexity is critical when deploying deep learning-based speech denoising models for on-device applications. Most prior research focused on optimizing model architectures to meet specific computational cost constraints, often creating distinct neural network architectures for different complexity limitations. This study conducts complexity scaling for speech denoising tasks, aiming to consolidate models with various complexities into a unified architecture. We present a Multi-Path Transform-based (MPT) architecture to handle both low- and high-complexity scenarios. A series of MPT networks present high performance covering a wide range of computational complexities on the DNS challenge dataset. Moreover, inspired by the scaling experiments in natural language processing, we explore the empirical relationship between model performance and computational cost on the denoising task. As the complexity number of multiply-accumulate operations (MACs) is scaled from 50M/s to 15G/s on MPT networks, we observe a linear increase in the values of PESQ-WB and SI-SNR, proportional to the logarithm of MACs, which might contribute to the understanding and application of complexity scaling in speech denoising tasks.