 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoPrep: An Automatic Preprocessing Framework for In-the-Wild Speech Data
Sep 25, 2023Recently, the utilization of extensive open-sourced text data has significantly advanced the performance of text-based large language models (LLMs). However, the use of in-the-wild large-scale speech data in the speech technology community remains constrained. One reason for this limitation is that a considerable amount of the publicly available speech data is compromised by background noise, speech overlapping, lack of speech segmentation information, missing speaker labels, and incomplete transcriptions, which can largely hinder their usefulness. On the other hand, human annotation of speech data is both time-consuming and costly. To address this issue, we introduce an automatic in-the-wild speech data preprocessing framework (AutoPrep) in this paper, which is designed to enhance speech quality, generate speaker labels, and produce transcriptions automatically. The proposed AutoPrep framework comprises six components: speech enhancement, speech segmentation, speaker clustering, target speech extraction, quality filtering and automatic speech recognition. Experiments conducted on the open-sourced WenetSpeech and our self-collected AutoPrepWild corpora demonstrate that the proposed AutoPrep framework can generate preprocessed data with similar DNSMOS and PDNSMOS scores compared to several open-sourced TTS datasets. The corresponding TTS system can achieve up to 0.68 in-domain speaker similarity.
SnakeGAN: A Universal Vocoder Leveraging DDSP Prior Knowledge and Periodic Inductive Bias
Sep 14, 2023



Generative adversarial network (GAN)-based neural vocoders have been widely used in audio synthesis tasks due to their high generation quality, efficient inference, and small computation footprint. However, it is still challenging to train a universal vocoder which can generalize well to out-of-domain (OOD) scenarios, such as unseen speaking styles, non-speech vocalization, singing, and musical pieces. In this work, we propose SnakeGAN, a GAN-based universal vocoder, which can synthesize high-fidelity audio in various OOD scenarios. SnakeGAN takes a coarse-grained signal generated by a differentiable digital signal processing (DDSP) model as prior knowledge, aiming at recovering high-fidelity waveform from a Mel-spectrogram. We introduce periodic nonlinearities through the Snake activation function and anti-aliased representation into the generator, which further brings the desired inductive bias for audio synthesis and significantly improves the extrapolation capacity for universal vocoding in unseen scenarios. To validate the effectiveness of our proposed method, we train SnakeGAN with only speech data and evaluate its performance for various OOD distributions with both subjective and objective metrics. Experimental results show that SnakeGAN significantly outperforms the compared approaches and can generate high-fidelity audio samples including unseen speakers with unseen styles, singing voices, instrumental pieces, and nonverbal vocalization.
Automatic Prosody Annotation with Pre-Trained Text-Speech Model
Jun 16, 2022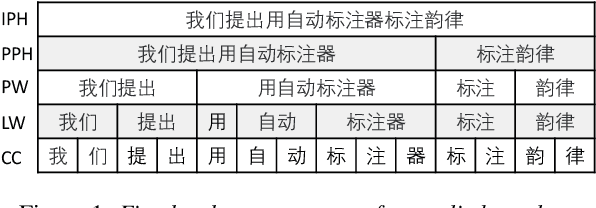
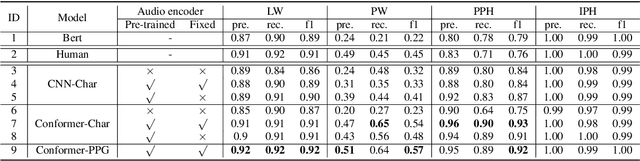

Prosodic boundary plays an important role in text-to-speech synthesis (TTS) in terms of naturalness and readability. However, the acquisition of prosodic boundary labels relies on manual annotation, which is costly and time-consuming. In this paper, we propose to automatically extract prosodic boundary labels from text-audio data via a neural text-speech model with pre-trained audio encoders. This model is pre-trained on text and speech data separately and jointly fine-tuned on TTS data in a triplet format: {speech, text, prosody}. The experimental results on both automatic evaluation and human evaluation demonstrate that: 1) the proposed text-speech prosody annotation framework significantly outperforms text-only baselines; 2) the quality of automatic prosodic boundary annotations is comparable to human annotations; 3) TTS systems trained with model-annotated boundaries are slightly better than systems that use manual ones.
Content-Dependent Fine-Grained Speaker Embedding for Zero-Shot Speaker Adaptation in Text-to-Speech Synthesis
Apr 03, 2022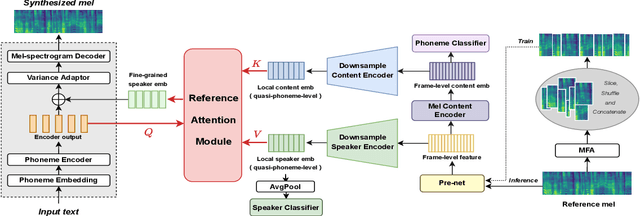

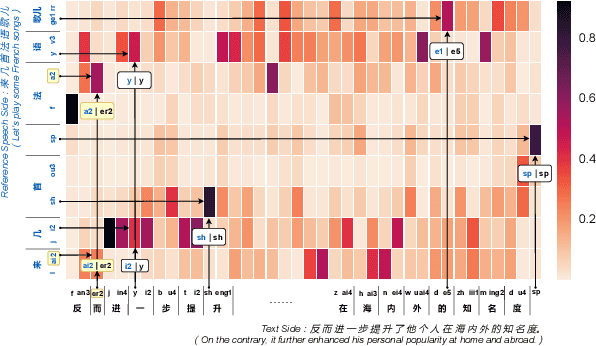

Zero-shot speaker adaptation aims to clone an unseen speaker's voice without any adaptation time and parameters. Previous researches usually use a speaker encoder to extract a global fixed speaker embedding from reference speech, and several attempts have tried variable-length speaker embedding. However, they neglect to transfer the personal pronunciation characteristics related to phoneme content, leading to poor speaker similarity in terms of detailed speaking styles and pronunciation habits. To improve the ability of the speaker encoder to model personal pronunciation characteristics, we propose content-dependent fine-grained speaker embedding for zero-shot speaker adaptation. The corresponding local content embeddings and speaker embeddings are extracted from a reference speech, respectively. Instead of modeling the temporal relations, a reference attention module is introduced to model the content relevance between the reference speech and the input text, and to generate the fine-grained speaker embedding for each phoneme encoder output. The experimental results show that our proposed method can improve speaker similarity of synthesized speeches, especially for unseen speakers.
Multi-reference Tacotron by Intercross Training for Style Disentangling,Transfer and Control in Speech Synthesis
Apr 04, 2019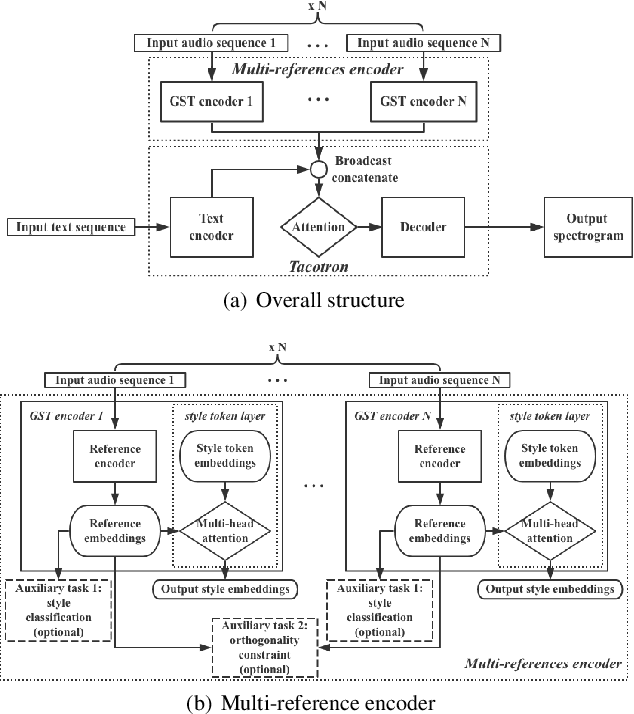
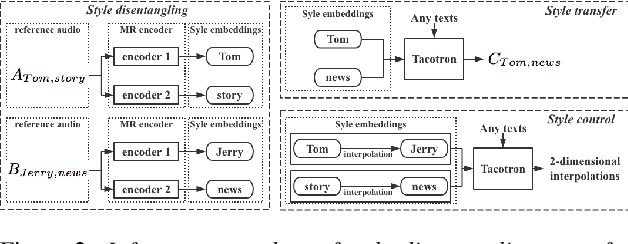
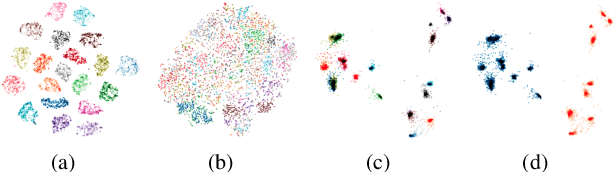

Speech style control and transfer techniques aim to enrich the diversity and expressiveness of synthesized speech. Existing approaches model all speech styles into one representation, lacking the ability to control a specific speech feature independently. To address this issue, we introduce a novel multi-reference structure to Tacotron and propose intercross training approach, which together ensure that each sub-encoder of the multi-reference encoder independently disentangles and controls a specific style. Experimental results show that our model is able to control and transfer desired speech styles individually.