 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSRCodec: Unified and Low-Bitrate Single Codebook Codec with Sub-Band Reconstruction
Jan 06, 2026Neural Audio Codecs (NACs) can reduce transmission overhead by performing compact compression and reconstruction, which also aim to bridge the gap between continuous and discrete signals. Existing NACs can be divided into two categories: multi-codebook and single-codebook codecs. Multi-codebook codecs face challenges such as structural complexity and difficulty in adapting to downstream tasks, while single-codebook codecs, though structurally simpler, suffer from low-fidelity, ineffective modeling of unified audio, and an inability to support modeling of high-frequency audio. We propose the UniSRCodec, a single-codebook codec capable of supporting high sampling rate, low-bandwidth, high fidelity, and unified. We analyze the inefficiency of waveform-based compression and introduce the time and frequency compression method using the Mel-spectrogram, and cooperate with a Vocoder to recover the phase information of the original audio. Moreover, we propose a sub-band reconstruction technique to achieve high-quality compression across both low and high frequency bands. Subjective and objective experimental results demonstrate that UniSRCodec achieves state-of-the-art (SOTA) performance among cross-domain single-codebook codecs with only a token rate of 40, and its reconstruction quality is comparable to that of certain multi-codebook methods. Our demo page is available at https://wxzyd123.github.io/unisrcodec.
From Inpainting to Editing: A Self-Bootstrapping Framework for Context-Rich Visual Dubbing
Dec 31, 2025Audio-driven visual dubbing aims to synchronize a video's lip movements with new speech, but is fundamentally challenged by the lack of ideal training data: paired videos where only a subject's lip movements differ while all other visual conditions are identical. Existing methods circumvent this with a mask-based inpainting paradigm, where an incomplete visual conditioning forces models to simultaneously hallucinate missing content and sync lips, leading to visual artifacts, identity drift, and poor synchronization. In this work, we propose a novel self-bootstrapping framework that reframes visual dubbing from an ill-posed inpainting task into a well-conditioned video-to-video editing problem. Our approach employs a Diffusion Transformer, first as a data generator, to synthesize ideal training data: a lip-altered companion video for each real sample, forming visually aligned video pairs. A DiT-based audio-driven editor is then trained on these pairs end-to-end, leveraging the complete and aligned input video frames to focus solely on precise, audio-driven lip modifications. This complete, frame-aligned input conditioning forms a rich visual context for the editor, providing it with complete identity cues, scene interactions, and continuous spatiotemporal dynamics. Leveraging this rich context fundamentally enables our method to achieve highly accurate lip sync, faithful identity preservation, and exceptional robustness against challenging in-the-wild scenarios. We further introduce a timestep-adaptive multi-phase learning strategy as a necessary component to disentangle conflicting editing objectives across diffusion timesteps, thereby facilitating stable training and yielding enhanced lip synchronization and visual fidelity. Additionally, we propose ContextDubBench, a comprehensive benchmark dataset for robust evaluation in diverse and challenging practical application scenarios.
E2E-VGuard: Adversarial Prevention for Production LLM-based End-To-End Speech Synthesis
Nov 10, 2025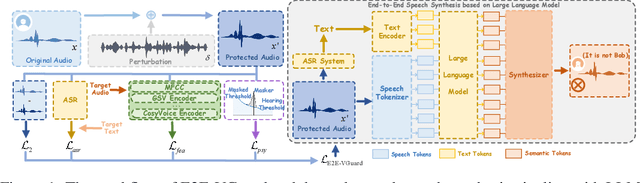
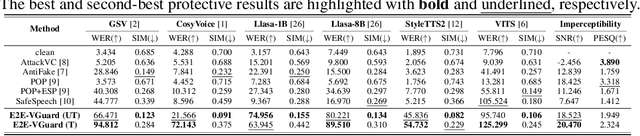

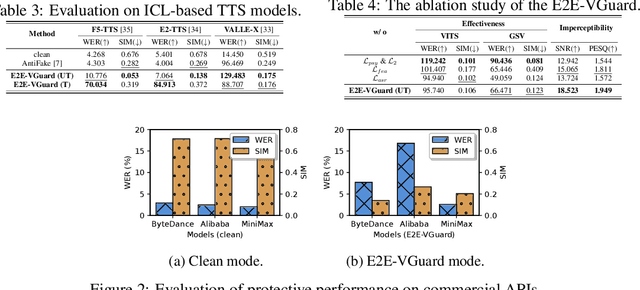
Recent advancements in speech synthesis technology have enriched our daily lives, with high-quality and human-like audio widely adopted across real-world applications. However, malicious exploitation like voice-cloning fraud poses severe security risks. Existing defense techniques struggle to address the production large language model (LLM)-based speech synthesis. While previous studies have considered the protection for fine-tuning synthesizers, they assume manually annotated transcripts. Given the labor intensity of manual annotation, end-to-end (E2E) systems leveraging automatic speech recognition (ASR) to generate transcripts are becoming increasingly prevalent, e.g., voice cloning via commercial APIs. Therefore, this E2E speech synthesis also requires new security mechanisms. To tackle these challenges, we propose E2E-VGuard, a proactive defense framework for two emerging threats: (1) production LLM-based speech synthesis, and (2) the novel attack arising from ASR-driven E2E scenarios. Specifically, we employ the encoder ensemble with a feature extractor to protect timbre, while ASR-targeted adversarial examples disrupt pronunciation. Moreover, we incorporate the psychoacoustic model to ensure perturbative imperceptibility. For a comprehensive evaluation, we test 16 open-source synthesizers and 3 commercial APIs across Chinese and English datasets, confirming E2E-VGuard's effectiveness in timbre and pronunciation protection. Real-world deployment validation is also conducted. Our code and demo page are available at https://wxzyd123.github.io/e2e-vguard/.
HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
Sep 10, 2025Human-Centric Video Generation (HCVG) methods seek to synthesize human videos from multimodal inputs, including text, image, and audio. Existing methods struggle to effectively coordinate these heterogeneous modalities due to two challenges: the scarcity of training data with paired triplet conditions and the difficulty of collaborating the sub-tasks of subject preservation and audio-visual sync with multimodal inputs. In this work, we present HuMo, a unified HCVG framework for collaborative multimodal control. For the first challenge, we construct a high-quality dataset with diverse and paired text, reference images, and audio. For the second challenge, we propose a two-stage progressive multimodal training paradigm with task-specific strategies. For the subject preservation task, to maintain the prompt following and visual generation abilities of the foundation model, we adopt the minimal-invasive image injection strategy. For the audio-visual sync task, besides the commonly adopted audio cross-attention layer, we propose a focus-by-predicting strategy that implicitly guides the model to associate audio with facial regions. For joint learning of controllabilities across multimodal inputs, building on previously acquired capabilities, we progressively incorporate the audio-visual sync task. During inference, for flexible and fine-grained multimodal control, we design a time-adaptive Classifier-Free Guidance strategy that dynamically adjusts guidance weights across denoising steps. Extensive experimental results demonstrate that HuMo surpasses specialized state-of-the-art methods in sub-tasks, establishing a unified framework for collaborative multimodal-conditioned HCVG. Project Page: https://phantom-video.github.io/HuMo.
Human Motion Video Generation: A Survey
Sep 04, 2025Human motion video generation has garnered significant research interest due to its broad applications, enabling innovations such as photorealistic singing heads or dynamic avatars that seamlessly dance to music. However, existing surveys in this field focus on individual methods, lacking a comprehensive overview of the entire generative process. This paper addresses this gap by providing an in-depth survey of human motion video generation, encompassing over ten sub-tasks, and detailing the five key phases of the generation process: input, motion planning, motion video generation, refinement, and output. Notably, this is the first survey that discusses the potential of large language models in enhancing human motion video generation. Our survey reviews the latest developments and technological trends in human motion video generation across three primary modalities: vision, text, and audio. By covering over two hundred papers, we offer a thorough overview of the field and highlight milestone works that have driven significant technological breakthroughs. Our goal for this survey is to unveil the prospects of human motion video generation and serve as a valuable resource for advancing the comprehensive applications of digital humans. A complete list of the models examined in this survey is available in Our Repository https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation.
* Accepted by TPAMI. Github Repo: https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation IEEE Access: https://ieeexplore.ieee.org/document/11106267
VoxRole: A Comprehensive Benchmark for Evaluating Speech-Based Role-Playing Agents
Sep 04, 2025Recent significant advancements in Large Language Models (LLMs) have greatly propelled the development of Role-Playing Conversational Agents (RPCAs). These systems aim to create immersive user experiences through consistent persona adoption. However, current RPCA research faces dual limitations. First, existing work predominantly focuses on the textual modality, entirely overlooking critical paralinguistic features including intonation, prosody, and rhythm in speech, which are essential for conveying character emotions and shaping vivid identities. Second, the speech-based role-playing domain suffers from a long-standing lack of standardized evaluation benchmarks. Most current spoken dialogue datasets target only fundamental capability assessments, featuring thinly sketched or ill-defined character profiles. Consequently, they fail to effectively quantify model performance on core competencies like long-term persona consistency. To address this critical gap, we introduce VoxRole, the first comprehensive benchmark specifically designed for the evaluation of speech-based RPCAs. The benchmark comprises 13335 multi-turn dialogues, totaling 65.6 hours of speech from 1228 unique characters across 261 movies. To construct this resource, we propose a novel two-stage automated pipeline that first aligns movie audio with scripts and subsequently employs an LLM to systematically build multi-dimensional profiles for each character. Leveraging VoxRole, we conduct a multi-dimensional evaluation of contemporary spoken dialogue models, revealing crucial insights into their respective strengths and limitations in maintaining persona consistency.
DualSpeechLM: Towards Unified Speech Understanding and Generation via Dual Speech Token Modeling with Large Language Models
Aug 12, 2025Extending pre-trained Large Language Models (LLMs)'s speech understanding or generation abilities by introducing various effective speech tokens has attracted great attention in the speech community. However, building a unified speech understanding and generation model still faces the following challenges: (1) Due to the huge modality gap between speech tokens and text tokens, extending text LLMs to unified speech LLMs relies on large-scale paired data for fine-tuning, and (2) Generation and understanding tasks prefer information at different levels, e.g., generation benefits from detailed acoustic features, while understanding favors high-level semantics. This divergence leads to difficult performance optimization in one unified model. To solve these challenges, in this paper, we present two key insights in speech tokenization and speech language modeling. Specifically, we first propose an Understanding-driven Speech Tokenizer (USTokenizer), which extracts high-level semantic information essential for accomplishing understanding tasks using text LLMs. In this way, USToken enjoys better modality commonality with text, which reduces the difficulty of modality alignment in adapting text LLMs to speech LLMs. Secondly, we present DualSpeechLM, a dual-token modeling framework that concurrently models USToken as input and acoustic token as output within a unified, end-to-end framework, seamlessly integrating speech understanding and generation capabilities. Furthermore, we propose a novel semantic supervision loss and a Chain-of-Condition (CoC) strategy to stabilize model training and enhance speech generation performance. Experimental results demonstrate that our proposed approach effectively fosters a complementary relationship between understanding and generation tasks, highlighting the promising strategy of mutually enhancing both tasks in one unified model.
Towards Hallucination-Free Music: A Reinforcement Learning Preference Optimization Framework for Reliable Song Generation
Aug 07, 2025Recent advances in audio-based generative language models have accelerated AI-driven lyric-to-song generation. However, these models frequently suffer from content hallucination, producing outputs misaligned with the input lyrics and undermining musical coherence. Current supervised fine-tuning (SFT) approaches, limited by passive label-fitting, exhibit constrained self-improvement and poor hallucination mitigation. To address this core challenge, we propose a novel reinforcement learning (RL) framework leveraging preference optimization for hallucination control. Our key contributions include: (1) Developing a robust hallucination preference dataset constructed via phoneme error rate (PER) computation and rule-based filtering to capture alignment with human expectations; (2) Implementing and evaluating three distinct preference optimization strategies within the RL framework: Direct Preference Optimization (DPO), Proximal Policy Optimization (PPO), and Group Relative Policy Optimization (GRPO). DPO operates off-policy to enhance positive token likelihood, achieving a significant 7.4% PER reduction. PPO and GRPO employ an on-policy approach, training a PER-based reward model to iteratively optimize sequences via reward maximization and KL-regularization, yielding PER reductions of 4.9% and 4.7%, respectively. Comprehensive objective and subjective evaluations confirm that our methods effectively suppress hallucinations while preserving musical quality. Crucially, this work presents a systematic, RL-based solution to hallucination control in lyric-to-song generation. The framework's transferability also unlocks potential for music style adherence and musicality enhancement, opening new avenues for future generative song research.
A Scalable Pipeline for Enabling Non-Verbal Speech Generation and Understanding
Aug 07, 2025Human spoken communication involves not only lexical content but also non-verbal vocalizations (NVs) such as laughter, sighs, and coughs, which convey emotions, intentions, and social signals. However, most existing speech systems focus solely on verbal content and lack the ability to understand and generate such non-verbal cues, reducing the emotional intelligence and communicative richness of spoken interfaces. In this work, we introduce $\textbf{NonVerbalSpeech-38K}$, a large and diverse dataset for non-verbal speech generation and understanding, collected from real-world media and annotated using an automatic pipeline. The dataset contains 38,718 samples (about 131 hours) with 10 categories of non-verbal cues, such as laughter, sniff, and throat clearing. We further validate the dataset by fine-tuning state-of-the-art models, including F5-TTS and Qwen2-Audio, demonstrating its effectiveness in non-verbal speech generation and understanding tasks. Our contributions are threefold: (1) We propose a practical pipeline for building natural and diverse non-verbal speech datasets; (2) We release a large-scale dataset to advance research on non-verbal speech generation and understanding; (3) We validate the dataset's effectiveness by demonstrating improvements in both non-verbal speech synthesis and captioning, thereby facilitating richer human-computer interaction.
A Multi-Stage Framework for Multimodal Controllable Speech Synthesis
Jun 26, 2025Controllable speech synthesis aims to control the style of generated speech using reference input, which can be of various modalities. Existing face-based methods struggle with robustness and generalization due to data quality constraints, while text prompt methods offer limited diversity and fine-grained control. Although multimodal approaches aim to integrate various modalities, their reliance on fully matched training data significantly constrains their performance and applicability. This paper proposes a 3-stage multimodal controllable speech synthesis framework to address these challenges. For face encoder, we use supervised learning and knowledge distillation to tackle generalization issues. Furthermore, the text encoder is trained on both text-face and text-speech data to enhance the diversity of the generated speech. Experimental results demonstrate that this method outperforms single-modal baseline methods in both face based and text prompt based speech synthesis, highlighting its effectiveness in generating high-quality speech.