 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLibraGen: Playing a Balance Game in Subject-Driven Video Generation
Mar 17, 2026With the advancement of video generation foundation models (VGFMs), customized generation, particularly subject-to-video (S2V), has attracted growing attention. However, a key challenge lies in balancing the intrinsic priors of a VGFM, such as motion coherence, visual aesthetics, and prompt alignment, with its newly derived S2V capability. Existing methods often neglect this balance by enhancing one aspect at the expense of others. To address this, we propose LibraGen, a novel framework that views extending foundation models for S2V generation as a balance game between intrinsic VGFM strengths and S2V capability. Specifically, guided by the core philosophy of "Raising the Fulcrum, Tuning to Balance," we identify data quality as the fulcrum and advocate a quality-over-quantity approach. We construct a hybrid pipeline that combines automated and manual data filtering to improve overall data quality. To further harmonize the VGFM's native capabilities with its S2V extension, we introduce a Tune-to-Balance post-training paradigm. During supervised fine-tuning, both cross-pair and in-pair data are incorporated, and model merging is employed to achieve an effective trade-off. Subsequently, two tailored direct preference optimization (DPO) pipelines, namely Consis-DPO and Real-Fake DPO, are designed and merged to consolidate this balance. During inference, we introduce a time-dependent dynamic classifier-free guidance scheme to enable flexible and fine-grained control. Experimental results demonstrate that LibraGen outperforms both open-source and commercial S2V models using only thousand-scale training data.
DreamID-Omni: Unified Framework for Controllable Human-Centric Audio-Video Generation
Feb 12, 2026Recent advancements in foundation models have revolutionized joint audio-video generation. However, existing approaches typically treat human-centric tasks including reference-based audio-video generation (R2AV), video editing (RV2AV) and audio-driven video animation (RA2V) as isolated objectives. Furthermore, achieving precise, disentangled control over multiple character identities and voice timbres within a single framework remains an open challenge. In this paper, we propose DreamID-Omni, a unified framework for controllable human-centric audio-video generation. Specifically, we design a Symmetric Conditional Diffusion Transformer that integrates heterogeneous conditioning signals via a symmetric conditional injection scheme. To resolve the pervasive identity-timbre binding failures and speaker confusion in multi-person scenarios, we introduce a Dual-Level Disentanglement strategy: Synchronized RoPE at the signal level to ensure rigid attention-space binding, and Structured Captions at the semantic level to establish explicit attribute-subject mappings. Furthermore, we devise a Multi-Task Progressive Training scheme that leverages weakly-constrained generative priors to regularize strongly-constrained tasks, preventing overfitting and harmonizing disparate objectives. Extensive experiments demonstrate that DreamID-Omni achieves comprehensive state-of-the-art performance across video, audio, and audio-visual consistency, even outperforming leading proprietary commercial models. We will release our code to bridge the gap between academic research and commercial-grade applications.
HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
Sep 10, 2025Human-Centric Video Generation (HCVG) methods seek to synthesize human videos from multimodal inputs, including text, image, and audio. Existing methods struggle to effectively coordinate these heterogeneous modalities due to two challenges: the scarcity of training data with paired triplet conditions and the difficulty of collaborating the sub-tasks of subject preservation and audio-visual sync with multimodal inputs. In this work, we present HuMo, a unified HCVG framework for collaborative multimodal control. For the first challenge, we construct a high-quality dataset with diverse and paired text, reference images, and audio. For the second challenge, we propose a two-stage progressive multimodal training paradigm with task-specific strategies. For the subject preservation task, to maintain the prompt following and visual generation abilities of the foundation model, we adopt the minimal-invasive image injection strategy. For the audio-visual sync task, besides the commonly adopted audio cross-attention layer, we propose a focus-by-predicting strategy that implicitly guides the model to associate audio with facial regions. For joint learning of controllabilities across multimodal inputs, building on previously acquired capabilities, we progressively incorporate the audio-visual sync task. During inference, for flexible and fine-grained multimodal control, we design a time-adaptive Classifier-Free Guidance strategy that dynamically adjusts guidance weights across denoising steps. Extensive experimental results demonstrate that HuMo surpasses specialized state-of-the-art methods in sub-tasks, establishing a unified framework for collaborative multimodal-conditioned HCVG. Project Page: https://phantom-video.github.io/HuMo.
Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset
Jun 23, 2025Subject-to-video generation has witnessed substantial progress in recent years. However, existing models still face significant challenges in faithfully following textual instructions. This limitation, commonly known as the copy-paste problem, arises from the widely used in-pair training paradigm. This approach inherently entangles subject identity with background and contextual attributes by sampling reference images from the same scene as the target video. To address this issue, we introduce \textbf{Phantom-Data, the first general-purpose cross-pair subject-to-video consistency dataset}, containing approximately one million identity-consistent pairs across diverse categories. Our dataset is constructed via a three-stage pipeline: (1) a general and input-aligned subject detection module, (2) large-scale cross-context subject retrieval from more than 53 million videos and 3 billion images, and (3) prior-guided identity verification to ensure visual consistency under contextual variation. Comprehensive experiments show that training with Phantom-Data significantly improves prompt alignment and visual quality while preserving identity consistency on par with in-pair baselines.
Customize Your Own Paired Data via Few-shot Way
May 21, 2024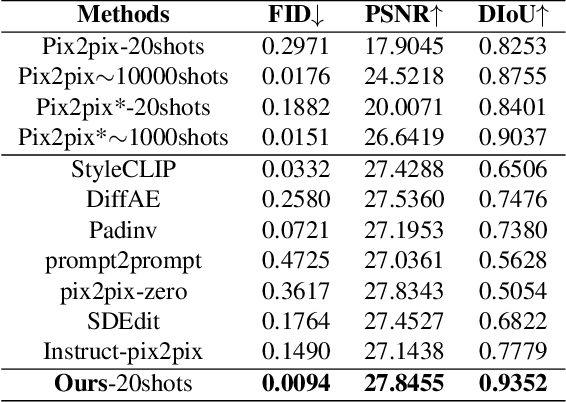
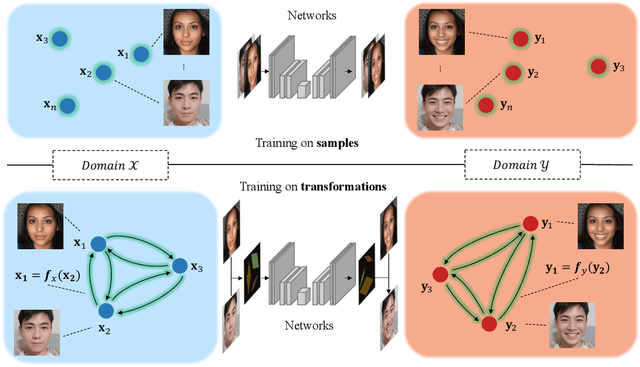
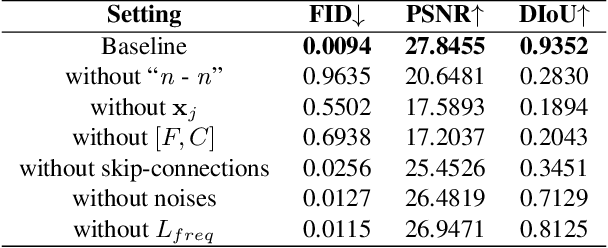
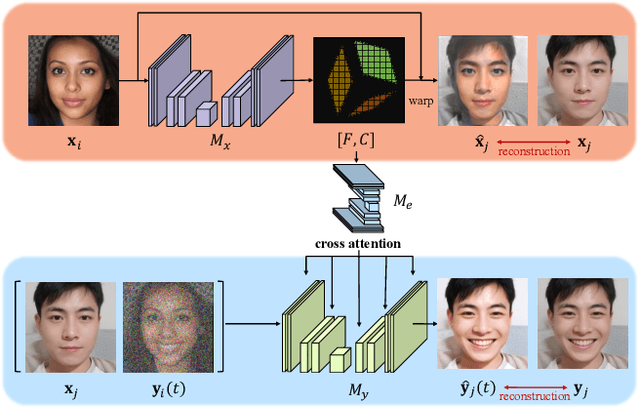
Existing solutions to image editing tasks suffer from several issues. Though achieving remarkably satisfying generated results, some supervised methods require huge amounts of paired training data, which greatly limits their usages. The other unsupervised methods take full advantage of large-scale pre-trained priors, thus being strictly restricted to the domains where the priors are trained on and behaving badly in out-of-distribution cases. The task we focus on is how to enable the users to customize their desired effects through only few image pairs. In our proposed framework, a novel few-shot learning mechanism based on the directional transformations among samples is introduced and expands the learnable space exponentially. Adopting a diffusion model pipeline, we redesign the condition calculating modules in our model and apply several technical improvements. Experimental results demonstrate the capabilities of our method in various cases.
GaFET: Learning Geometry-aware Facial Expression Translation from In-The-Wild Images
Aug 07, 2023While current face animation methods can manipulate expressions individually, they suffer from several limitations. The expressions manipulated by some motion-based facial reenactment models are crude. Other ideas modeled with facial action units cannot generalize to arbitrary expressions not covered by annotations. In this paper, we introduce a novel Geometry-aware Facial Expression Translation (GaFET) framework, which is based on parametric 3D facial representations and can stably decoupled expression. Among them, a Multi-level Feature Aligned Transformer is proposed to complement non-geometric facial detail features while addressing the alignment challenge of spatial features. Further, we design a De-expression model based on StyleGAN, in order to reduce the learning difficulty of GaFET in unpaired "in-the-wild" images. Extensive qualitative and quantitative experiments demonstrate that we achieve higher-quality and more accurate facial expression transfer results compared to state-of-the-art methods, and demonstrate applicability of various poses and complex textures. Besides, videos or annotated training data are omitted, making our method easier to use and generalize.
Semantic 3D-aware Portrait Synthesis and Manipulation Based on Compositional Neural Radiance Field
Feb 03, 2023
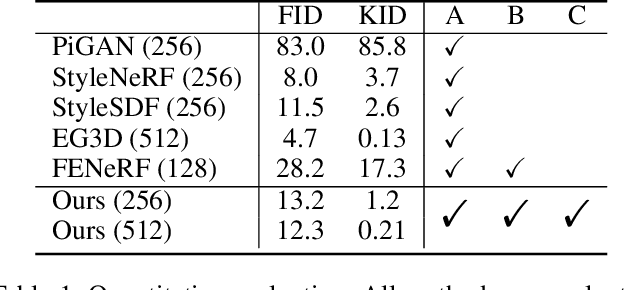
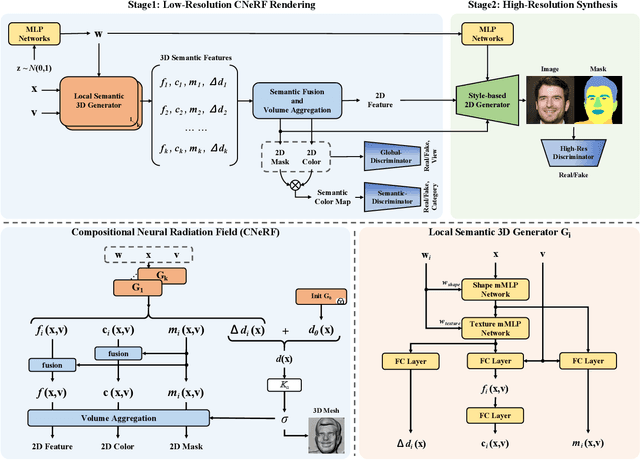

Recently 3D-aware GAN methods with neural radiance field have developed rapidly. However, current methods model the whole image as an overall neural radiance field, which limits the partial semantic editability of synthetic results. Since NeRF renders an image pixel by pixel, it is possible to split NeRF in the spatial dimension. We propose a Compositional Neural Radiance Field (CNeRF) for semantic 3D-aware portrait synthesis and manipulation. CNeRF divides the image by semantic regions and learns an independent neural radiance field for each region, and finally fuses them and renders the complete image. Thus we can manipulate the synthesized semantic regions independently, while fixing the other parts unchanged. Furthermore, CNeRF is also designed to decouple shape and texture within each semantic region. Compared to state-of-the-art 3D-aware GAN methods, our approach enables fine-grained semantic region manipulation, while maintaining high-quality 3D-consistent synthesis. The ablation studies show the effectiveness of the structure and loss function used by our method. In addition real image inversion and cartoon portrait 3D editing experiments demonstrate the application potential of our method.
CFFT-GAN: Cross-domain Feature Fusion Transformer for Exemplar-based Image Translation
Feb 03, 2023

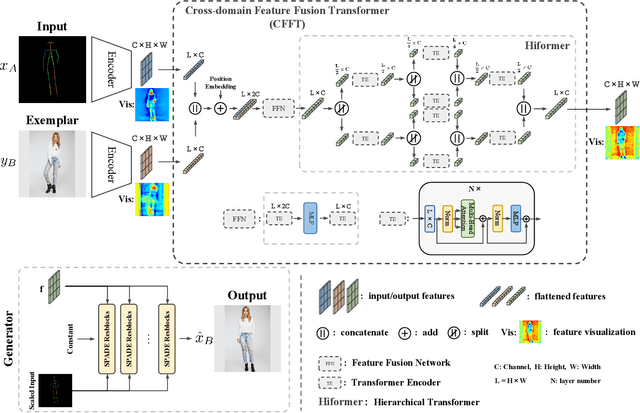
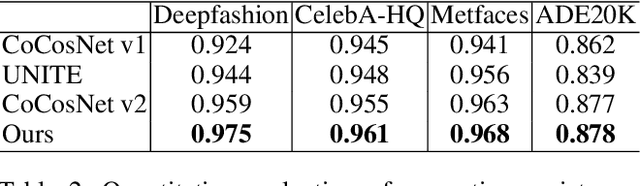
Exemplar-based image translation refers to the task of generating images with the desired style, while conditioning on certain input image. Most of the current methods learn the correspondence between two input domains and lack the mining of information within the domains. In this paper, we propose a more general learning approach by considering two domain features as a whole and learning both inter-domain correspondence and intra-domain potential information interactions. Specifically, we propose a Cross-domain Feature Fusion Transformer (CFFT) to learn inter- and intra-domain feature fusion. Based on CFFT, the proposed CFFT-GAN works well on exemplar-based image translation. Moreover, CFFT-GAN is able to decouple and fuse features from multiple domains by cascading CFFT modules. We conduct rich quantitative and qualitative experiments on several image translation tasks, and the results demonstrate the superiority of our approach compared to state-of-the-art methods. Ablation studies show the importance of our proposed CFFT. Application experimental results reflect the potential of our method.
ReGANIE: Rectifying GAN Inversion Errors for Accurate Real Image Editing
Jan 31, 2023



The StyleGAN family succeed in high-fidelity image generation and allow for flexible and plausible editing of generated images by manipulating the semantic-rich latent style space.However, projecting a real image into its latent space encounters an inherent trade-off between inversion quality and editability. Existing encoder-based or optimization-based StyleGAN inversion methods attempt to mitigate the trade-off but see limited performance. To fundamentally resolve this problem, we propose a novel two-phase framework by designating two separate networks to tackle editing and reconstruction respectively, instead of balancing the two. Specifically, in Phase I, a W-space-oriented StyleGAN inversion network is trained and used to perform image inversion and editing, which assures the editability but sacrifices reconstruction quality. In Phase II, a carefully designed rectifying network is utilized to rectify the inversion errors and perform ideal reconstruction. Experimental results show that our approach yields near-perfect reconstructions without sacrificing the editability, thus allowing accurate manipulation of real images. Further, we evaluate the performance of our rectifying network, and see great generalizability towards unseen manipulation types and out-of-domain images.
FaceEraser: Removing Facial Parts for Augmented Reality
Sep 22, 2021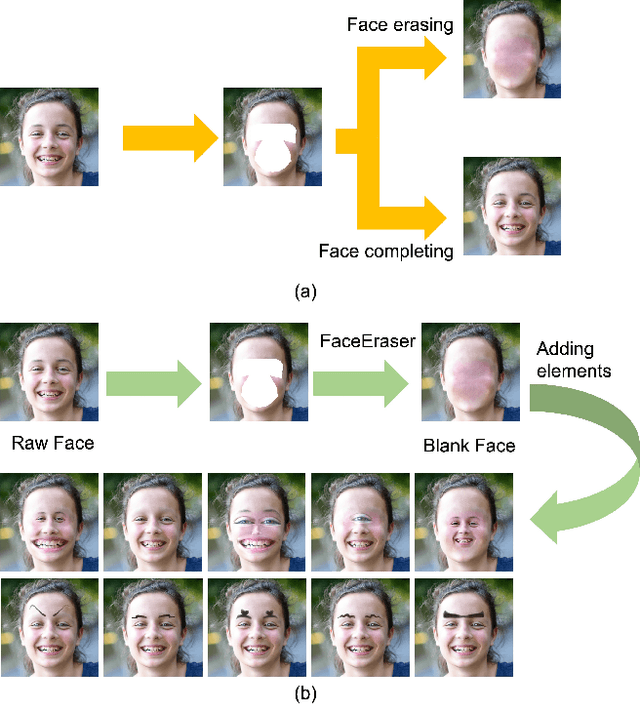
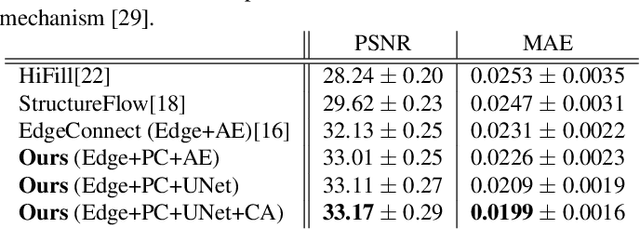

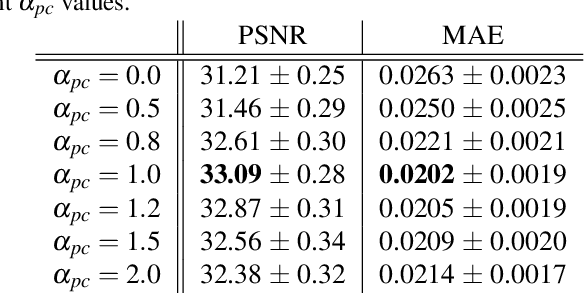
Our task is to remove all facial parts (e.g., eyebrows, eyes, mouth and nose), and then impose visual elements onto the ``blank'' face for augmented reality. Conventional object removal methods rely on image inpainting techniques (e.g., EdgeConnect, HiFill) that are trained in a self-supervised manner with randomly manipulated image pairs. Specifically, given a set of natural images, randomly masked images are used as inputs and the raw images are treated as ground truths. Whereas, this technique does not satisfy the requirements of facial parts removal, as it is hard to obtain ``ground-truth'' images with real ``blank'' faces. To address this issue, we propose a novel data generation technique to produce paired training data that well mimic the ``blank'' faces. In the mean time, we propose a novel network architecture for improved inpainting quality for our task. Finally, we demonstrate various face-oriented augmented reality applications on top of our facial parts removal model. Our method has been integrated into commercial products and its effectiveness has been verified with unconstrained user inputs. The source codes, pre-trained models and training data will be released for research purposes.