 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Mar 23, 2026We present daVinci-MagiHuman, an open-source audio-video generative foundation model for human-centric generation. daVinci-MagiHuman jointly generates synchronized video and audio using a single-stream Transformer that processes text, video, and audio within a unified token sequence via self-attention only. This single-stream design avoids the complexity of multi-stream or cross-attention architectures while remaining easy to optimize with standard training and inference infrastructure. The model is particularly strong in human-centric scenarios, producing expressive facial performance, natural speech-expression coordination, realistic body motion, and precise audio-video synchronization. It supports multilingual spoken generation across Chinese (Mandarin and Cantonese), English, Japanese, Korean, German, and French. For efficient inference, we combine the single-stream backbone with model distillation, latent-space super-resolution, and a Turbo VAE decoder, enabling generation of a 5-second 256p video in 2 seconds on a single H100 GPU. In automatic evaluation, daVinci-MagiHuman achieves the highest visual quality and text alignment among leading open models, along with the lowest word error rate (14.60%) for speech intelligibility. In pairwise human evaluation, it achieves win rates of 80.0% against Ovi 1.1 and 60.9% against LTX 2.3 over 2000 comparisons. We open-source the complete model stack, including the base model, the distilled model, the super-resolution model, and the inference codebase.
LibraGen: Playing a Balance Game in Subject-Driven Video Generation
Mar 17, 2026With the advancement of video generation foundation models (VGFMs), customized generation, particularly subject-to-video (S2V), has attracted growing attention. However, a key challenge lies in balancing the intrinsic priors of a VGFM, such as motion coherence, visual aesthetics, and prompt alignment, with its newly derived S2V capability. Existing methods often neglect this balance by enhancing one aspect at the expense of others. To address this, we propose LibraGen, a novel framework that views extending foundation models for S2V generation as a balance game between intrinsic VGFM strengths and S2V capability. Specifically, guided by the core philosophy of "Raising the Fulcrum, Tuning to Balance," we identify data quality as the fulcrum and advocate a quality-over-quantity approach. We construct a hybrid pipeline that combines automated and manual data filtering to improve overall data quality. To further harmonize the VGFM's native capabilities with its S2V extension, we introduce a Tune-to-Balance post-training paradigm. During supervised fine-tuning, both cross-pair and in-pair data are incorporated, and model merging is employed to achieve an effective trade-off. Subsequently, two tailored direct preference optimization (DPO) pipelines, namely Consis-DPO and Real-Fake DPO, are designed and merged to consolidate this balance. During inference, we introduce a time-dependent dynamic classifier-free guidance scheme to enable flexible and fine-grained control. Experimental results demonstrate that LibraGen outperforms both open-source and commercial S2V models using only thousand-scale training data.
HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
Sep 10, 2025Human-Centric Video Generation (HCVG) methods seek to synthesize human videos from multimodal inputs, including text, image, and audio. Existing methods struggle to effectively coordinate these heterogeneous modalities due to two challenges: the scarcity of training data with paired triplet conditions and the difficulty of collaborating the sub-tasks of subject preservation and audio-visual sync with multimodal inputs. In this work, we present HuMo, a unified HCVG framework for collaborative multimodal control. For the first challenge, we construct a high-quality dataset with diverse and paired text, reference images, and audio. For the second challenge, we propose a two-stage progressive multimodal training paradigm with task-specific strategies. For the subject preservation task, to maintain the prompt following and visual generation abilities of the foundation model, we adopt the minimal-invasive image injection strategy. For the audio-visual sync task, besides the commonly adopted audio cross-attention layer, we propose a focus-by-predicting strategy that implicitly guides the model to associate audio with facial regions. For joint learning of controllabilities across multimodal inputs, building on previously acquired capabilities, we progressively incorporate the audio-visual sync task. During inference, for flexible and fine-grained multimodal control, we design a time-adaptive Classifier-Free Guidance strategy that dynamically adjusts guidance weights across denoising steps. Extensive experimental results demonstrate that HuMo surpasses specialized state-of-the-art methods in sub-tasks, establishing a unified framework for collaborative multimodal-conditioned HCVG. Project Page: https://phantom-video.github.io/HuMo.
Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset
Jun 23, 2025Subject-to-video generation has witnessed substantial progress in recent years. However, existing models still face significant challenges in faithfully following textual instructions. This limitation, commonly known as the copy-paste problem, arises from the widely used in-pair training paradigm. This approach inherently entangles subject identity with background and contextual attributes by sampling reference images from the same scene as the target video. To address this issue, we introduce \textbf{Phantom-Data, the first general-purpose cross-pair subject-to-video consistency dataset}, containing approximately one million identity-consistent pairs across diverse categories. Our dataset is constructed via a three-stage pipeline: (1) a general and input-aligned subject detection module, (2) large-scale cross-context subject retrieval from more than 53 million videos and 3 billion images, and (3) prior-guided identity verification to ensure visual consistency under contextual variation. Comprehensive experiments show that training with Phantom-Data significantly improves prompt alignment and visual quality while preserving identity consistency on par with in-pair baselines.
Energy-Efficient WiFi Backscatter Communication for Green IoTs
May 16, 2023
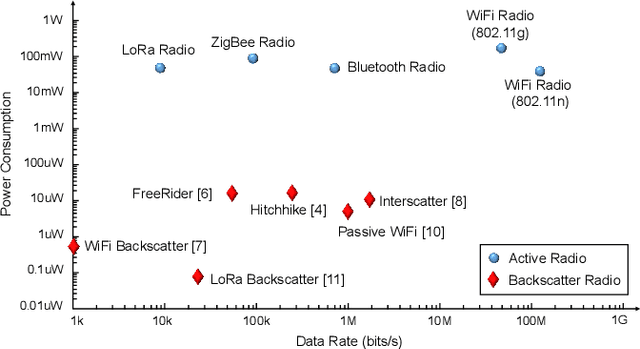
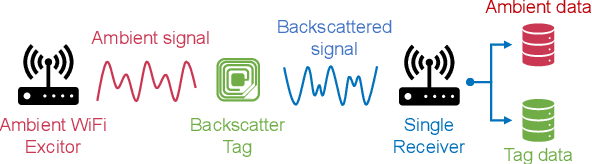
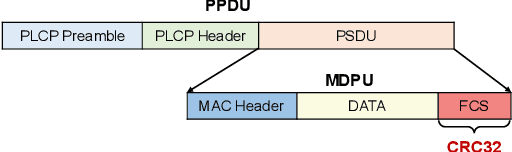
The boom of the Internet of Things has revolutionized people's lives, but it has also resulted in massive resource consumption and environmental pollution. Recently, Green IoT (GIoT) has become a worldwide consensus to address this issue. In this paper, we propose EEWScatter, an energy-efficient WiFi backscatter communication system to pursue the goal of GIoT. Unlike previous backscatter systems that solely focus on tags, our approach offers a comprehensive system-wide view on energy conservation. Specifically, we reuse ambient signals as carriers and utilize an ultra-low-power and battery-free design for tag nodes by backscatter. Further, we design a new CRC-based algorithm that enables the demodulation of both ambient and tag data by only a single receiver while using ambient carriers. Such a design eliminates system reliance on redundant transceivers with high power consumption. Results demonstrate that EEWScatter achieves the lowest overall system power consumption and saves at least half of the energy. What's more, the power consumption of our tag is only 1/1000 of that of active radio. We believe that EEWScatter is a critical step towards a sustainable future.
HS-Diffusion: Learning a Semantic-Guided Diffusion Model for Head Swapping
Dec 13, 2022Image-based head swapping task aims to stitch a source head to another source body flawlessly. This seldom-studied task faces two major challenges: 1) Preserving the head and body from various sources while generating a seamless transition region. 2) No paired head swapping dataset and benchmark so far. In this paper, we propose an image-based head swapping framework (HS-Diffusion) which consists of a semantic-guided latent diffusion model (SG-LDM) and a semantic layout generator. We blend the semantic layouts of source head and source body, and then inpaint the transition region by the semantic layout generator, achieving a coarse-grained head swapping. SG-LDM can further implement fine-grained head swapping with the blended layout as condition by a progressive fusion process, while preserving source head and source body with high-quality reconstruction. To this end, we design a head-cover augmentation strategy for training and a neck alignment trick for geometric realism. Importantly, we construct a new image-based head swapping benchmark and propose two tailor-designed metrics (Mask-FID and Focal-FID). Extensive experiments demonstrate the superiority of our framework. The code will be available: https://github.com/qinghew/HS-Diffusion.
FaceEraser: Removing Facial Parts for Augmented Reality
Sep 22, 2021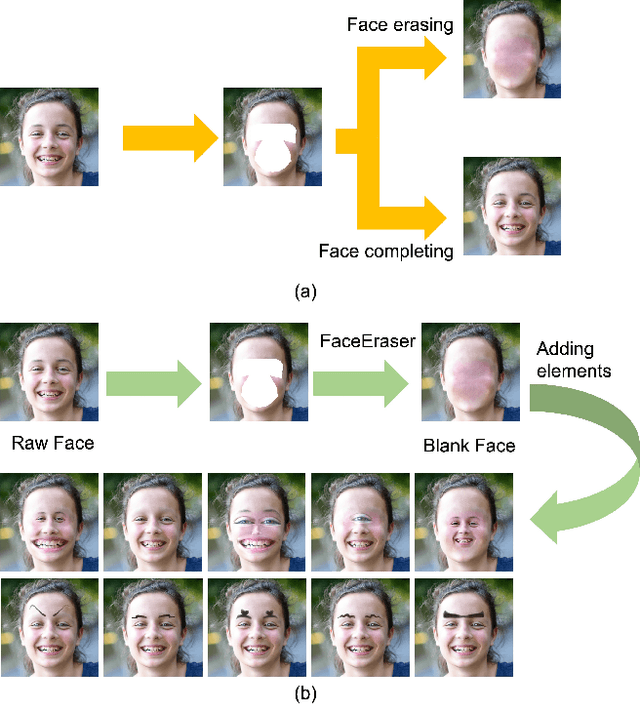
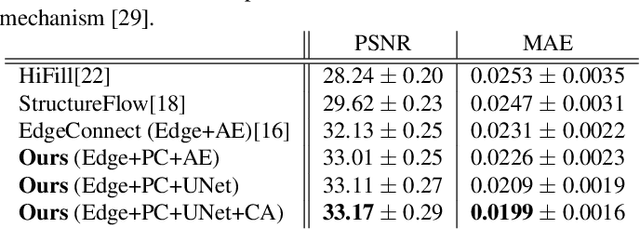

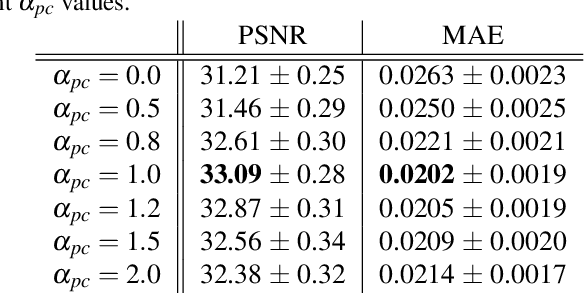
Our task is to remove all facial parts (e.g., eyebrows, eyes, mouth and nose), and then impose visual elements onto the ``blank'' face for augmented reality. Conventional object removal methods rely on image inpainting techniques (e.g., EdgeConnect, HiFill) that are trained in a self-supervised manner with randomly manipulated image pairs. Specifically, given a set of natural images, randomly masked images are used as inputs and the raw images are treated as ground truths. Whereas, this technique does not satisfy the requirements of facial parts removal, as it is hard to obtain ``ground-truth'' images with real ``blank'' faces. To address this issue, we propose a novel data generation technique to produce paired training data that well mimic the ``blank'' faces. In the mean time, we propose a novel network architecture for improved inpainting quality for our task. Finally, we demonstrate various face-oriented augmented reality applications on top of our facial parts removal model. Our method has been integrated into commercial products and its effectiveness has been verified with unconstrained user inputs. The source codes, pre-trained models and training data will be released for research purposes.
Reinforced Axial Refinement Network for Monocular 3D Object Detection
Aug 31, 2020
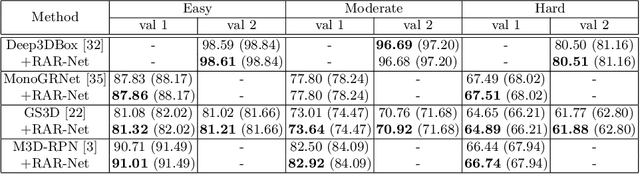
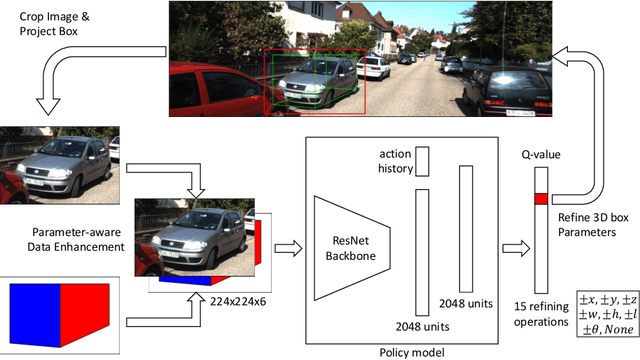
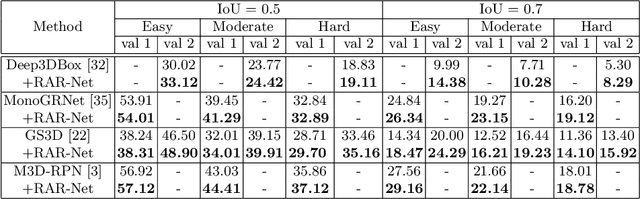
Monocular 3D object detection aims to extract the 3D position and properties of objects from a 2D input image. This is an ill-posed problem with a major difficulty lying in the information loss by depth-agnostic cameras. Conventional approaches sample 3D bounding boxes from the space and infer the relationship between the target object and each of them, however, the probability of effective samples is relatively small in the 3D space. To improve the efficiency of sampling, we propose to start with an initial prediction and refine it gradually towards the ground truth, with only one 3d parameter changed in each step. This requires designing a policy which gets a reward after several steps, and thus we adopt reinforcement learning to optimize it. The proposed framework, Reinforced Axial Refinement Network (RAR-Net), serves as a post-processing stage which can be freely integrated into existing monocular 3D detection methods, and improve the performance on the KITTI dataset with small extra computational costs.
Deep Fitting Degree Scoring Network for Monocular 3D Object Detection
Apr 26, 2019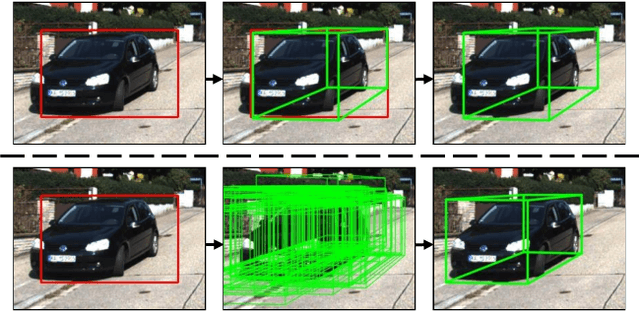

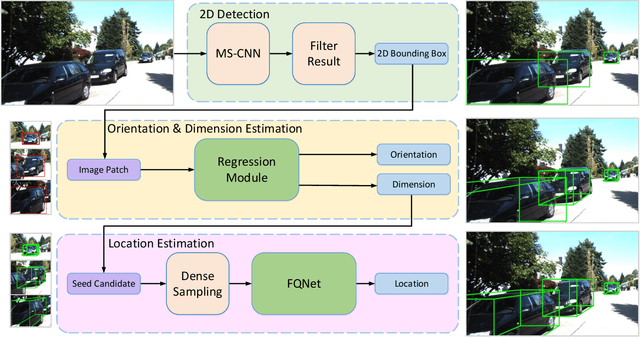

In this paper, we propose to learn a deep fitting degree scoring network for monocular 3D object detection, which aims to score fitting degree between proposals and object conclusively. Different from most existing monocular frameworks which use tight constraint to get 3D location, our approach achieves high-precision localization through measuring the visual fitting degree between the projected 3D proposals and the object. We first regress the dimension and orientation of the object using an anchor-based method so that a suitable 3D proposal can be constructed. We propose FQNet, which can infer the 3D IoU between the 3D proposals and the object solely based on 2D cues. Therefore, during the detection process, we sample a large number of candidates in the 3D space and project these 3D bounding boxes on 2D image individually. The best candidate can be picked out by simply exploring the spatial overlap between proposals and the object, in the form of the output 3D IoU score of FQNet. Experiments on the KITTI dataset demonstrate the effectiveness of our framework.