 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FM Agent
Oct 30, 2025Large language models (LLMs) are catalyzing the development of autonomous AI research agents for scientific and engineering discovery. We present FM Agent, a novel and general-purpose multi-agent framework that leverages a synergistic combination of LLM-based reasoning and large-scale evolutionary search to address complex real-world challenges. The core of FM Agent integrates several key innovations: 1) a cold-start initialization phase incorporating expert guidance, 2) a novel evolutionary sampling strategy for iterative optimization, 3) domain-specific evaluators that combine correctness, effectiveness, and LLM-supervised feedback, and 4) a distributed, asynchronous execution infrastructure built on Ray. Demonstrating broad applicability, our system has been evaluated across diverse domains, including operations research, machine learning, GPU kernel optimization, and classical mathematical problems. FM Agent reaches state-of-the-art results autonomously, without human interpretation or tuning -- 1976.3 on ALE-Bench (+5.2\%), 43.56\% on MLE-Bench (+4.0pp), up to 20x speedups on KernelBench, and establishes new state-of-the-art(SOTA) results on several classical mathematical problems. Beyond academic benchmarks, FM Agent shows considerable promise for both large-scale enterprise R\&D workflows and fundamental scientific research, where it can accelerate innovation, automate complex discovery processes, and deliver substantial engineering and scientific advances with broader societal impact.
Mitigating Knowledge Conflicts in Language Model-Driven Question Answering
Nov 18, 2024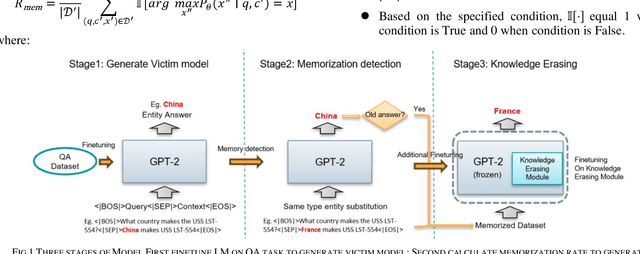


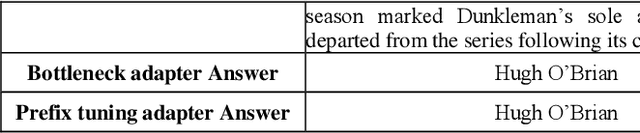
Knowledge-aware sequence to sequence generation tasks such as document question answering and abstract summarization typically requires two types of knowledge: encoded parametric knowledge and retrieved contextual information. Previous work show improper correlation between parametric knowledge and answers in the training set could cause the model ignore input information at test time, resulting in un-desirable model behaviour such as over-stability and hallucination. In this work, we argue that hallucination could be mitigated via explicit correlation between input source and generated content. We focus on a typical example of hallucination, entity-based knowledge conflicts in question answering, where correlation of entities and their description at training time hinders model behaviour during inference.
Reinforced Axial Refinement Network for Monocular 3D Object Detection
Aug 31, 2020
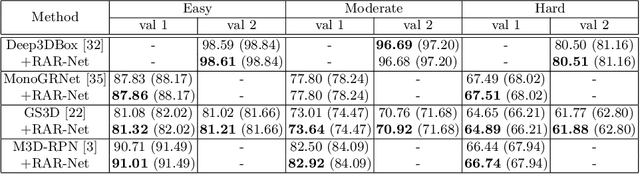
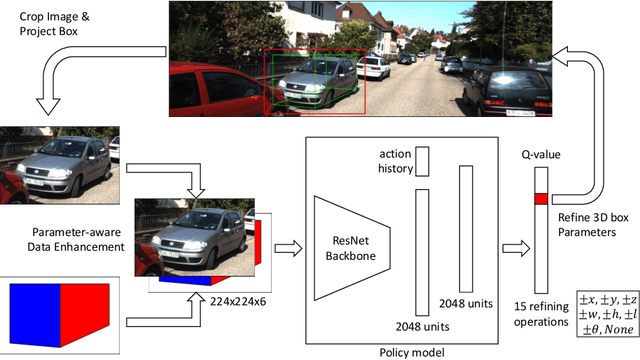
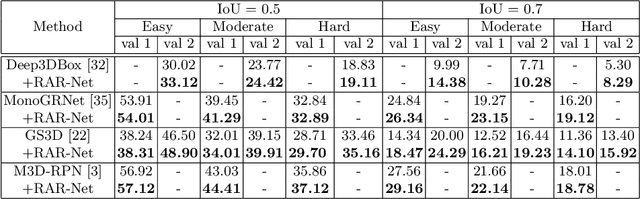
Monocular 3D object detection aims to extract the 3D position and properties of objects from a 2D input image. This is an ill-posed problem with a major difficulty lying in the information loss by depth-agnostic cameras. Conventional approaches sample 3D bounding boxes from the space and infer the relationship between the target object and each of them, however, the probability of effective samples is relatively small in the 3D space. To improve the efficiency of sampling, we propose to start with an initial prediction and refine it gradually towards the ground truth, with only one 3d parameter changed in each step. This requires designing a policy which gets a reward after several steps, and thus we adopt reinforcement learning to optimize it. The proposed framework, Reinforced Axial Refinement Network (RAR-Net), serves as a post-processing stage which can be freely integrated into existing monocular 3D detection methods, and improve the performance on the KITTI dataset with small extra computational costs.
LadaBERT: Lightweight Adaptation of BERT through Hybrid Model Compression
Apr 08, 2020
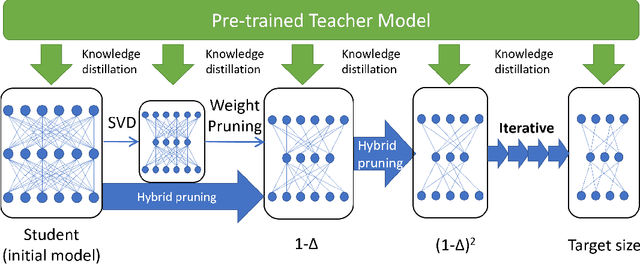
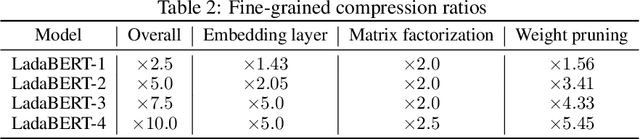
BERT is a cutting-edge language representation model pre-trained by a large corpus, which achieves superior performances on various natural language understanding tasks. However, a major blocking issue of applying BERT to online services is that it is memory-intensive and leads to unsatisfactory latency of user requests, raising the necessity of model compression. Existing solutions leverage the knowledge distillation framework to learn a smaller model that imitates the behaviors of BERT. However, the training procedure of knowledge distillation is expensive itself as it requires sufficient training data to imitate the teacher model. In this paper, we address this issue by proposing a hybrid solution named LadaBERT (Lightweight adaptation of BERT through hybrid model compression), which combines the advantages of different model compression methods, including weight pruning, matrix factorization and knowledge distillation. LadaBERT achieves state-of-the-art accuracy on various public datasets while the training overheads can be reduced by an order of magnitude.