 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
Beyond Two-Stage Training: Cooperative SFT and RL for LLM Reasoning
Sep 08, 2025Reinforcement learning (RL) has proven effective in incentivizing the reasoning abilities of large language models (LLMs), but suffers from severe efficiency challenges due to its trial-and-error nature. While the common practice employs supervised fine-tuning (SFT) as a warm-up stage for RL, this decoupled two-stage approach limits interaction between SFT and RL, thereby constraining overall effectiveness. This study introduces a novel method for learning reasoning models that employs bilevel optimization to facilitate better cooperation between these training paradigms. By conditioning the SFT objective on the optimal RL policy, our approach enables SFT to meta-learn how to guide RL's optimization process. During training, the lower level performs RL updates while simultaneously receiving SFT supervision, and the upper level explicitly maximizes the cooperative gain-the performance advantage of joint SFT-RL training over RL alone. Empirical evaluations on five reasoning benchmarks demonstrate that our method consistently outperforms baselines and achieves a better balance between effectiveness and efficiency.
ReVeal: Self-Evolving Code Agents via Iterative Generation-Verification
Jun 13, 2025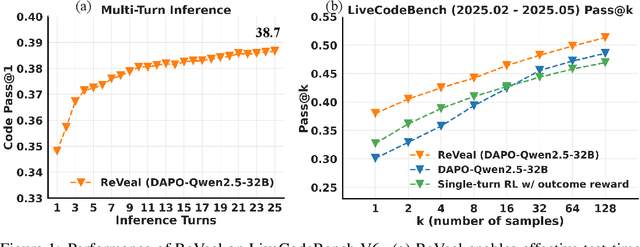



Recent advances in reinforcement learning (RL) with verifiable outcome rewards have significantly improved the reasoning capabilities of large language models (LLMs), especially when combined with multi-turn tool interactions. However, existing methods lack both meaningful verification signals from realistic environments and explicit optimization for verification, leading to unreliable self-verification. To address these limitations, we propose ReVeal, a multi-turn reinforcement learning framework that interleaves code generation with explicit self-verification and tool-based evaluation. ReVeal enables LLMs to autonomously generate test cases, invoke external tools for precise feedback, and improves performance via a customized RL algorithm with dense, per-turn rewards. As a result, ReVeal fosters the co-evolution of a model's generation and verification capabilities through RL training, expanding the reasoning boundaries of the base model, demonstrated by significant gains in Pass@k on LiveCodeBench. It also enables test-time scaling into deeper inference regimes, with code consistently evolving as the number of turns increases during inference, ultimately surpassing DeepSeek-R1-Zero-Qwen-32B. These findings highlight the promise of ReVeal as a scalable and effective paradigm for building more robust and autonomous AI agents.
Vulnerability-Aware Alignment: Mitigating Uneven Forgetting in Harmful Fine-Tuning
Jun 04, 2025Harmful fine-tuning (HFT), performed directly on open-source LLMs or through Fine-tuning-as-a-Service, breaks safety alignment and poses significant threats. Existing methods aim to mitigate HFT risks by learning robust representation on alignment data or making harmful data unlearnable, but they treat each data sample equally, leaving data vulnerability patterns understudied. In this work, we reveal that certain subsets of alignment data are consistently more prone to forgetting during HFT across different fine-tuning tasks. Inspired by these findings, we propose Vulnerability-Aware Alignment (VAA), which estimates data vulnerability, partitions data into "vulnerable" and "invulnerable" groups, and encourages balanced learning using a group distributionally robust optimization (Group DRO) framework. Specifically, VAA learns an adversarial sampler that samples examples from the currently underperforming group and then applies group-dependent adversarial perturbations to the data during training, aiming to encourage a balanced learning process across groups. Experiments across four fine-tuning tasks demonstrate that VAA significantly reduces harmful scores while preserving downstream task performance, outperforming state-of-the-art baselines.
ADNP-15: An Open-Source Histopathological Dataset for Neuritic Plaque Segmentation in Human Brain Whole Slide Images with Frequency Domain Image Enhancement for Stain Normalization
May 08, 2025Alzheimer's Disease (AD) is a neurodegenerative disorder characterized by amyloid-beta plaques and tau neurofibrillary tangles, which serve as key histopathological features. The identification and segmentation of these lesions are crucial for understanding AD progression but remain challenging due to the lack of large-scale annotated datasets and the impact of staining variations on automated image analysis. Deep learning has emerged as a powerful tool for pathology image segmentation; however, model performance is significantly influenced by variations in staining characteristics, necessitating effective stain normalization and enhancement techniques. In this study, we address these challenges by introducing an open-source dataset (ADNP-15) of neuritic plaques (i.e., amyloid deposits combined with a crown of dystrophic tau-positive neurites) in human brain whole slide images. We establish a comprehensive benchmark by evaluating five widely adopted deep learning models across four stain normalization techniques, providing deeper insights into their influence on neuritic plaque segmentation. Additionally, we propose a novel image enhancement method that improves segmentation accuracy, particularly in complex tissue structures, by enhancing structural details and mitigating staining inconsistencies. Our experimental results demonstrate that this enhancement strategy significantly boosts model generalization and segmentation accuracy. All datasets and code are open-source, ensuring transparency and reproducibility while enabling further advancements in the field.
Map Feature Perception Metric for Map Generation Quality Assessment and Loss Optimization
Mar 30, 2025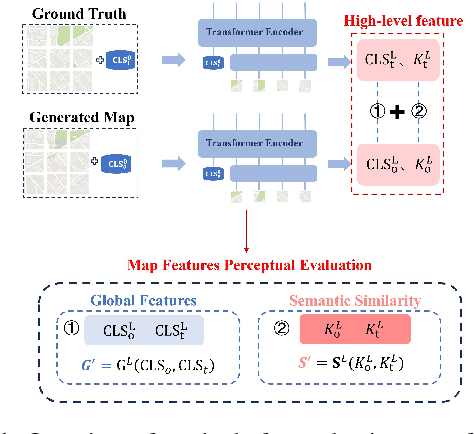
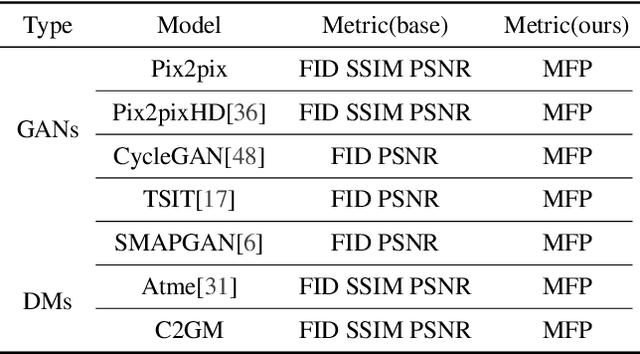
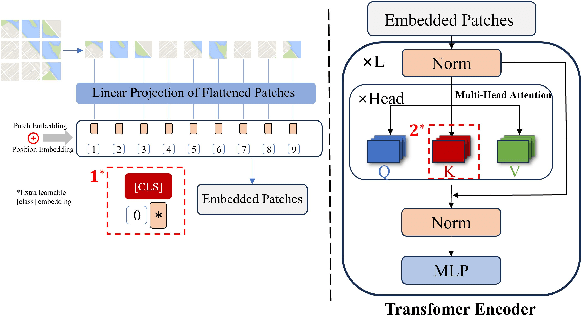
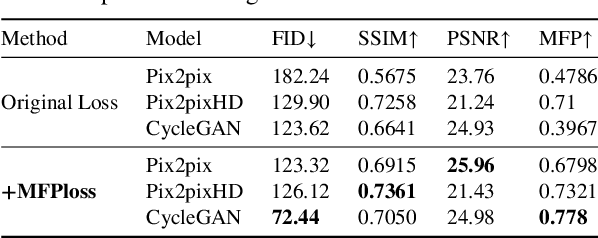
In intelligent cartographic generation tasks empowered by generative models, the authenticity of synthesized maps constitutes a critical determinant. Concurrently, the selection of appropriate evaluation metrics to quantify map authenticity emerges as a pivotal research challenge. Current methodologies predominantly adopt computer vision-based image assessment metrics to compute discrepancies between generated and reference maps. However, conventional visual similarity metrics-including L1, L2, SSIM, and FID-primarily operate at pixel-level comparisons, inadequately capturing cartographic global features and spatial correlations, consequently inducing semantic-structural artifacts in generated outputs. This study introduces a novel Map Feature Perception Metric designed to evaluate global characteristics and spatial congruence between synthesized and target maps. Diverging from pixel-wise metrics, our approach extracts elemental-level deep features that comprehensively encode cartographic structural integrity and topological relationships. Experimental validation demonstrates MFP's superior capability in evaluating cartographic semantic features, with classification-enhanced implementations outperforming conventional loss functions across diverse generative frameworks. When employed as optimization objectives, our metric achieves performance gains ranging from 2% to 50% across multiple benchmarks compared to traditional L1, L2, and SSIM baselines. This investigation concludes that explicit consideration of cartographic global attributes and spatial coherence substantially enhances generative model optimization, thereby significantly improving the geographical plausibility of synthesized maps.
C2GM: Cascading Conditional Generation of Multi-scale Maps from Remote Sensing Images Constrained by Geographic Features
Feb 07, 2025
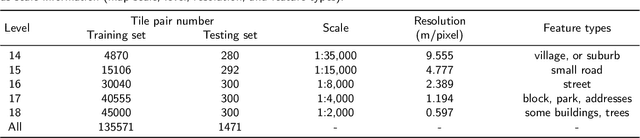

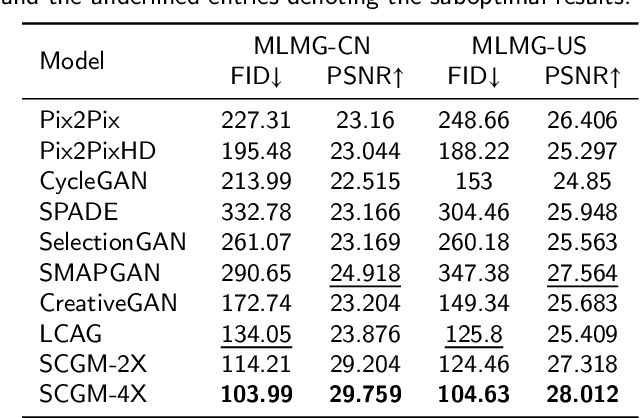
Multi-scale maps are essential representations of surveying and cartographic results, serving as fundamental components of geographic services. Current image generation networks can quickly produce map tiles from remote-sensing images. However, generative models designed for natural images often focus on texture features, neglecting the unique characteristics of remote-sensing features and the scale attributes of tile maps. This limitation in generative models impairs the accurate representation of geographic information, and the quality of tile map generation still needs improvement. Diffusion models have demonstrated remarkable success in various image generation tasks, highlighting their potential to address this challenge. This paper presents C2GM, a novel framework for generating multi-scale tile maps through conditional guided diffusion and multi-scale cascade generation. Specifically, we implement a conditional feature fusion encoder to extract object priors from remote sensing images and cascade reference double branch input, ensuring an accurate representation of complex features. Low-level generated tiles act as constraints for high-level map generation, enhancing visual continuity. Moreover, we incorporate map scale modality information using CLIP to simulate the relationship between map scale and cartographic generalization in tile maps. Extensive experimental evaluations demonstrate that C2GM consistently achieves the state-of-the-art (SOTA) performance on all metrics, facilitating the rapid and effective generation of multi-scale large-format maps for emergency response and remote mapping applications.
BSM: Small but Powerful Biological Sequence Model for Genes and Proteins
Oct 15, 2024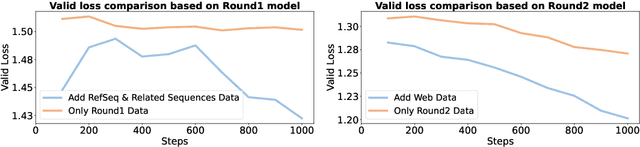

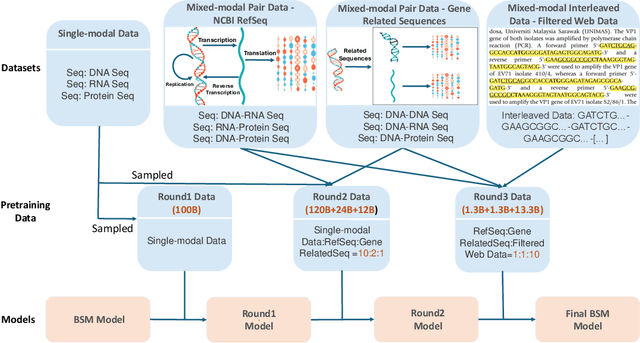
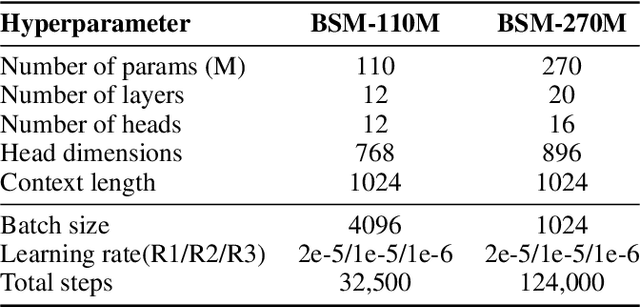
Modeling biological sequences such as DNA, RNA, and proteins is crucial for understanding complex processes like gene regulation and protein synthesis. However, most current models either focus on a single type or treat multiple types of data separately, limiting their ability to capture cross-modal relationships. We propose that by learning the relationships between these modalities, the model can enhance its understanding of each type. To address this, we introduce BSM, a small but powerful mixed-modal biological sequence foundation model, trained on three types of data: RefSeq, Gene Related Sequences, and interleaved biological sequences from the web. These datasets capture the genetic flow, gene-protein relationships, and the natural co-occurrence of diverse biological data, respectively. By training on mixed-modal data, BSM significantly enhances learning efficiency and cross-modal representation, outperforming models trained solely on unimodal data. With only 110M parameters, BSM achieves performance comparable to much larger models across both single-modal and mixed-modal tasks, and uniquely demonstrates in-context learning capability for mixed-modal tasks, which is absent in existing models. Further scaling to 270M parameters demonstrates even greater performance gains, highlighting the potential of BSM as a significant advancement in multimodal biological sequence modeling.
CPL: Critical Planning Step Learning Boosts LLM Generalization in Reasoning Tasks
Sep 13, 2024



Post-training large language models (LLMs) to develop reasoning capabilities has proven effective across diverse domains, such as mathematical reasoning and code generation. However, existing methods primarily focus on improving task-specific reasoning but have not adequately addressed the model's generalization capabilities across a broader range of reasoning tasks. To tackle this challenge, we introduce Critical Planning Step Learning (CPL), which leverages Monte Carlo Tree Search (MCTS) to explore diverse planning steps in multi-step reasoning tasks. Based on long-term outcomes, CPL learns step-level planning preferences to improve the model's planning capabilities and, consequently, its general reasoning capabilities. Furthermore, while effective in many scenarios for aligning LLMs, existing preference learning approaches like Direct Preference Optimization (DPO) struggle with complex multi-step reasoning tasks due to their inability to capture fine-grained supervision at each step. We propose Step-level Advantage Preference Optimization (Step-APO), which integrates an advantage estimate for step-level preference pairs obtained via MCTS into the DPO. This enables the model to more effectively learn critical intermediate planning steps, thereby further improving its generalization in reasoning tasks. Experimental results demonstrate that our method, trained exclusively on GSM8K and MATH, not only significantly improves performance on GSM8K (+10.5%) and MATH (+6.5%), but also enhances out-of-domain reasoning benchmarks, such as ARC-C (+4.0%), BBH (+1.8%), MMLU-STEM (+2.2%), and MMLU (+0.9%).