 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2GM: Cascading Conditional Generation of Multi-scale Maps from Remote Sensing Images Constrained by Geographic Features
Feb 07, 2025
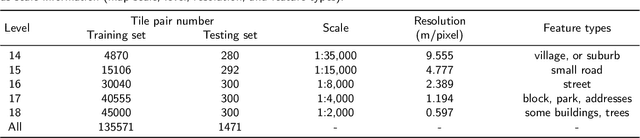

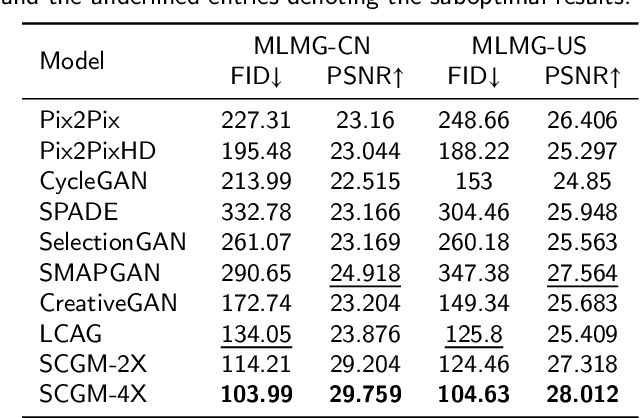
Multi-scale maps are essential representations of surveying and cartographic results, serving as fundamental components of geographic services. Current image generation networks can quickly produce map tiles from remote-sensing images. However, generative models designed for natural images often focus on texture features, neglecting the unique characteristics of remote-sensing features and the scale attributes of tile maps. This limitation in generative models impairs the accurate representation of geographic information, and the quality of tile map generation still needs improvement. Diffusion models have demonstrated remarkable success in various image generation tasks, highlighting their potential to address this challenge. This paper presents C2GM, a novel framework for generating multi-scale tile maps through conditional guided diffusion and multi-scale cascade generation. Specifically, we implement a conditional feature fusion encoder to extract object priors from remote sensing images and cascade reference double branch input, ensuring an accurate representation of complex features. Low-level generated tiles act as constraints for high-level map generation, enhancing visual continuity. Moreover, we incorporate map scale modality information using CLIP to simulate the relationship between map scale and cartographic generalization in tile maps. Extensive experimental evaluations demonstrate that C2GM consistently achieves the state-of-the-art (SOTA) performance on all metrics, facilitating the rapid and effective generation of multi-scale large-format maps for emergency response and remote mapping applications.
Small but Mighty: Enhancing 3D Point Clouds Semantic Segmentation with U-Next Framework
Apr 03, 2023



We study the problem of semantic segmentation of large-scale 3D point clouds. In recent years, significant research efforts have been directed toward local feature aggregation, improved loss functions and sampling strategies. While the fundamental framework of point cloud semantic segmentation has been largely overlooked, with most existing approaches rely on the U-Net architecture by default. In this paper, we propose U-Next, a small but mighty framework designed for point cloud semantic segmentation. The key to this framework is to learn multi-scale hierarchical representations from semantically similar feature maps. Specifically, we build our U-Next by stacking multiple U-Net $L^1$ codecs in a nested and densely arranged manner to minimize the semantic gap, while simultaneously fusing the feature maps across scales to effectively recover the fine-grained details. We also devised a multi-level deep supervision mechanism to further smooth gradient propagation and facilitate network optimization. Extensive experiments conducted on three large-scale benchmarks including S3DIS, Toronto3D, and SensatUrban demonstrate the superiority and the effectiveness of the proposed U-Next architecture. Our U-Next architecture shows consistent and visible performance improvements across different tasks and baseline models, indicating its great potential to serve as a general framework for future research.
LACV-Net: Semantic Segmentation of Large-Scale Point Cloud Scene via Local Adaptive and Comprehensive VLAD
Oct 12, 2022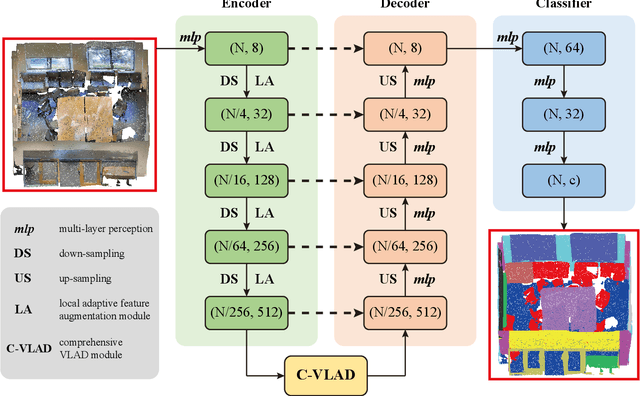
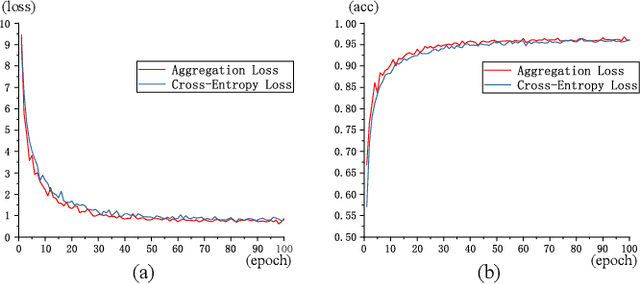
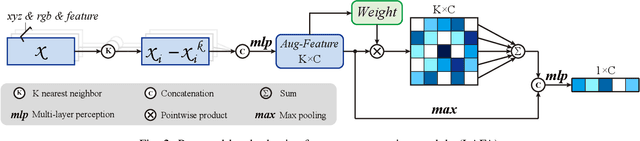
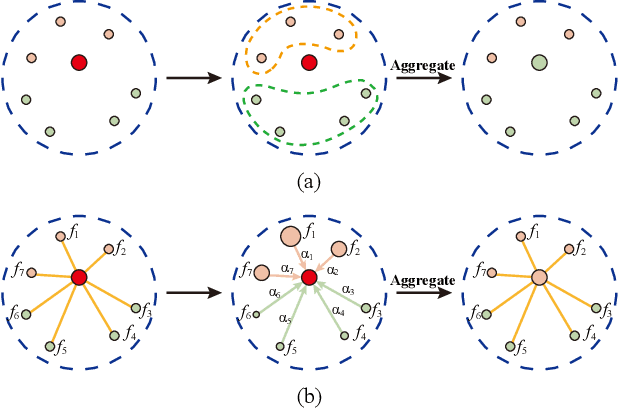
Large-scale point cloud semantic segmentation is an important task in 3D computer vision, which is widely applied in autonomous driving, robotics, and virtual reality. Current large-scale point cloud semantic segmentation methods usually use down-sampling operations to improve computation efficiency and acquire point clouds with multi-resolution. However, this may cause the problem of missing local information. Meanwhile, it is difficult for networks to capture global information in large-scale distributed contexts. To capture local and global information effectively, we propose an end-to-end deep neural network called LACV-Net for large-scale point cloud semantic segmentation. The proposed network contains three main components: 1) a local adaptive feature augmentation module (LAFA) to adaptively learn the similarity of centroids and neighboring points to augment the local context; 2) a comprehensive VLAD module (C-VLAD) that fuses local features with multi-layer, multi-scale, and multi-resolution to represent a comprehensive global description vector; and 3) an aggregation loss function to effectively optimize the segmentation boundaries by constraining the adaptive weight from the LAFA module. Compared to state-of-the-art networks on several large-scale benchmark datasets, including S3DIS, Toronto3D, and SensatUrban, we demonstrated the effectiveness of the proposed network.