 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMA-CBP: A Criminal Behavior Prediction Framework Based on Multi-Agent Asynchronous Collaboration
Aug 08, 2025



With the acceleration of urbanization, criminal behavior in public scenes poses an increasingly serious threat to social security. Traditional anomaly detection methods based on feature recognition struggle to capture high-level behavioral semantics from historical information, while generative approaches based on Large Language Models (LLMs) often fail to meet real-time requirements. To address these challenges, we propose MA-CBP, a criminal behavior prediction framework based on multi-agent asynchronous collaboration. This framework transforms real-time video streams into frame-level semantic descriptions, constructs causally consistent historical summaries, and fuses adjacent image frames to perform joint reasoning over long- and short-term contexts. The resulting behavioral decisions include key elements such as event subjects, locations, and causes, enabling early warning of potential criminal activity. In addition, we construct a high-quality criminal behavior dataset that provides multi-scale language supervision, including frame-level, summary-level, and event-level semantic annotations. Experimental results demonstrate that our method achieves superior performance on multiple datasets and offers a promising solution for risk warning in urban public safety scenarios.
Hoi2Anomaly: An Explainable Anomaly Detection Approach Guided by Human-Object Interaction
Mar 13, 2025



In the domain of Image Anomaly Detection (IAD), Existing methods frequently exhibit a paucity of fine-grained, interpretable semantic information, resulting in the detection of anomalous entities or activities that are susceptible to machine illusions. This deficiency often leads to the detection of anomalous entities or actions that are susceptible to machine illusions and lack sufficient explanation. In this thesis, we propose a novel approach to anomaly detection, termed Hoi2Anomaly, which aims to achieve precise discrimination and localization of anomalies. The proposed methodology involves the construction of a multi-modal instruction tuning dataset comprising human-object interaction (HOI) pairs in anomalous scenarios. Second, we have trained an HOI extractor in threat scenarios to localize and match anomalous actions and entities. Finally, explanatory content is generated for the detected anomalous HOI by fine-tuning the visual language pretraining (VLP) framework. The experimental results demonstrate that Hoi2Anomaly surpasses existing generative approaches in terms of precision and explainability. We will release Hoi2Anomaly for the advancement of the field of anomaly detection.
LACV-Net: Semantic Segmentation of Large-Scale Point Cloud Scene via Local Adaptive and Comprehensive VLAD
Oct 12, 2022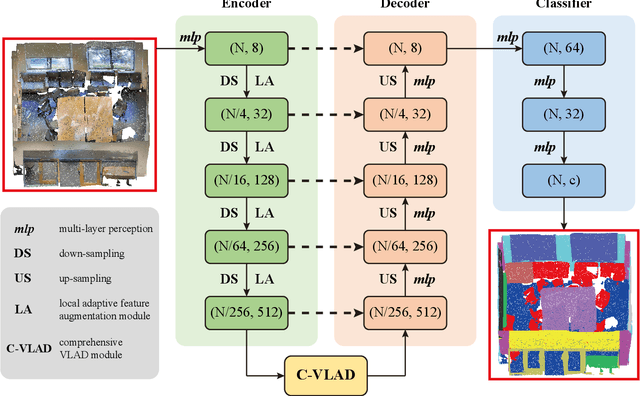
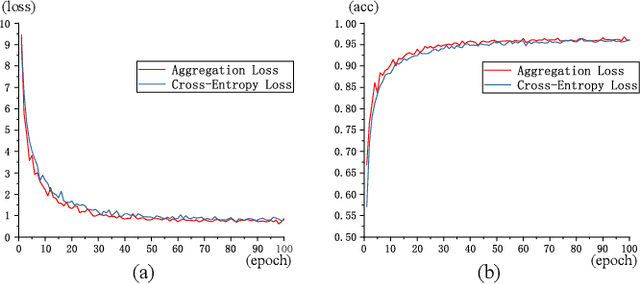
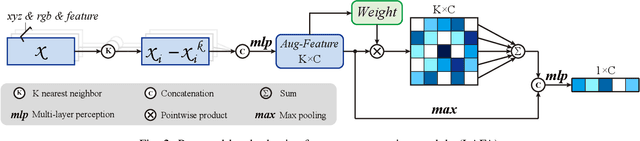
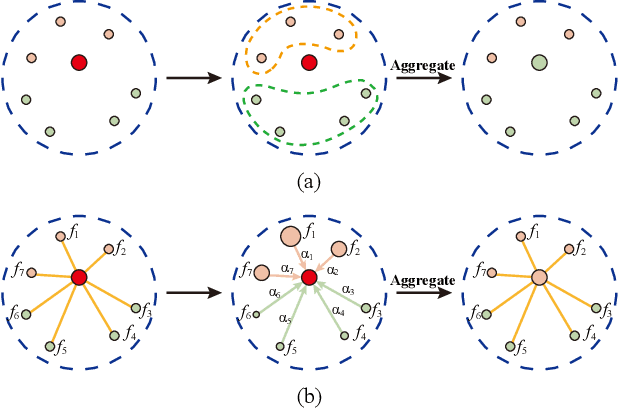
Large-scale point cloud semantic segmentation is an important task in 3D computer vision, which is widely applied in autonomous driving, robotics, and virtual reality. Current large-scale point cloud semantic segmentation methods usually use down-sampling operations to improve computation efficiency and acquire point clouds with multi-resolution. However, this may cause the problem of missing local information. Meanwhile, it is difficult for networks to capture global information in large-scale distributed contexts. To capture local and global information effectively, we propose an end-to-end deep neural network called LACV-Net for large-scale point cloud semantic segmentation. The proposed network contains three main components: 1) a local adaptive feature augmentation module (LAFA) to adaptively learn the similarity of centroids and neighboring points to augment the local context; 2) a comprehensive VLAD module (C-VLAD) that fuses local features with multi-layer, multi-scale, and multi-resolution to represent a comprehensive global description vector; and 3) an aggregation loss function to effectively optimize the segmentation boundaries by constraining the adaptive weight from the LAFA module. Compared to state-of-the-art networks on several large-scale benchmark datasets, including S3DIS, Toronto3D, and SensatUrban, we demonstrated the effectiveness of the proposed network.