 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Fine-Tuning of Sparsely-Activated Large Language Models on Resource-Constrained Devices
Aug 26, 2025Federated fine-tuning of Mixture-of-Experts (MoE)-based large language models (LLMs) is challenging due to their massive computational requirements and the resource constraints of participants. Existing working attempts to fill this gap through model quantization, computation offloading, or expert pruning. However, they cannot achieve desired performance due to impractical system assumptions and a lack of consideration for MoE-specific characteristics. In this paper, we propose FLUX, a system designed to enable federated fine-tuning of MoE-based LLMs across participants with constrained computing resources (e.g., consumer-grade GPUs), aiming to minimize time-to-accuracy. FLUX introduces three key innovations: (1) quantization-based local profiling to estimate expert activation with minimal overhead, (2) adaptive layer-aware expert merging to reduce resource consumption while preserving accuracy, and (3) dynamic expert role assignment using an exploration-exploitation strategy to balance tuning and non-tuning experts. Extensive experiments on LLaMA-MoE and DeepSeek-MoE with multiple benchmark datasets demonstrate that FLUX significantly outperforms existing methods, achieving up to 4.75X speedup in time-to-accuracy.
On the Lack of Robustness of Binary Function Similarity Systems
Dec 05, 2024Binary function similarity, which often relies on learning-based algorithms to identify what functions in a pool are most similar to a given query function, is a sought-after topic in different communities, including machine learning, software engineering, and security. Its importance stems from the impact it has in facilitating several crucial tasks, from reverse engineering and malware analysis to automated vulnerability detection. Whereas recent work cast light around performance on this long-studied problem, the research landscape remains largely lackluster in understanding the resiliency of the state-of-the-art machine learning models against adversarial attacks. As security requires to reason about adversaries, in this work we assess the robustness of such models through a simple yet effective black-box greedy attack, which modifies the topology and the content of the control flow of the attacked functions. We demonstrate that this attack is successful in compromising all the models, achieving average attack success rates of 57.06% and 95.81% depending on the problem settings (targeted and untargeted attacks). Our findings are insightful: top performance on clean data does not necessarily relate to top robustness properties, which explicitly highlights performance-robustness trade-offs one should consider when deploying such models, calling for further research.
Purifier: Defending Data Inference Attacks via Transforming Confidence Scores
Dec 01, 2022Neural networks are susceptible to data inference attacks such as the membership inference attack, the adversarial model inversion attack and the attribute inference attack, where the attacker could infer useful information such as the membership, the reconstruction or the sensitive attributes of a data sample from the confidence scores predicted by the target classifier. In this paper, we propose a method, namely PURIFIER, to defend against membership inference attacks. It transforms the confidence score vectors predicted by the target classifier and makes purified confidence scores indistinguishable in individual shape, statistical distribution and prediction label between members and non-members. The experimental results show that PURIFIER helps defend membership inference attacks with high effectiveness and efficiency, outperforming previous defense methods, and also incurs negligible utility loss. Besides, our further experiments show that PURIFIER is also effective in defending adversarial model inversion attacks and attribute inference attacks. For example, the inversion error is raised about 4+ times on the Facescrub530 classifier, and the attribute inference accuracy drops significantly when PURIFIER is deployed in our experiment.
LACV-Net: Semantic Segmentation of Large-Scale Point Cloud Scene via Local Adaptive and Comprehensive VLAD
Oct 12, 2022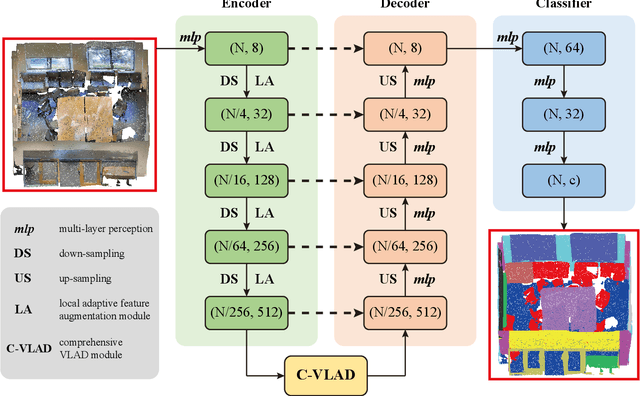
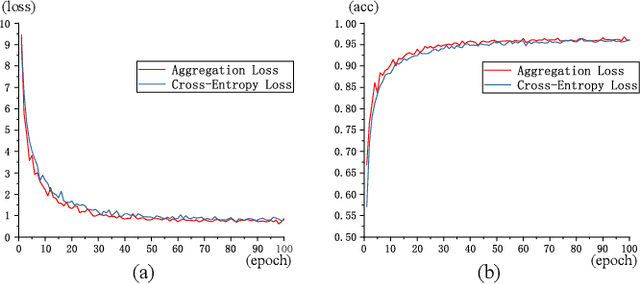
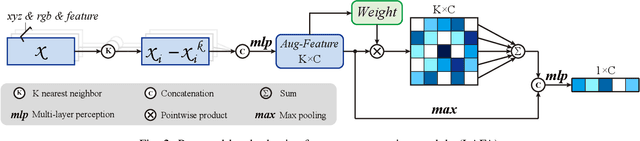
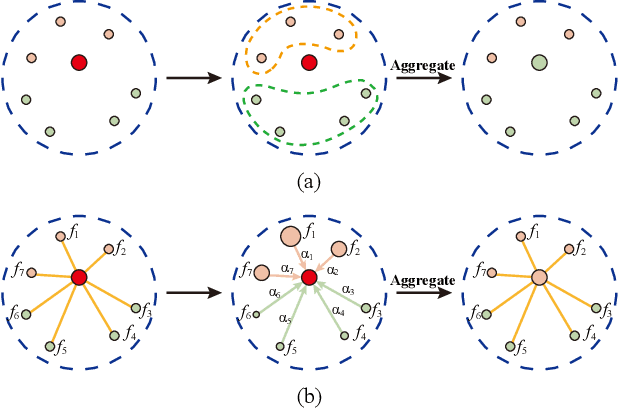
Large-scale point cloud semantic segmentation is an important task in 3D computer vision, which is widely applied in autonomous driving, robotics, and virtual reality. Current large-scale point cloud semantic segmentation methods usually use down-sampling operations to improve computation efficiency and acquire point clouds with multi-resolution. However, this may cause the problem of missing local information. Meanwhile, it is difficult for networks to capture global information in large-scale distributed contexts. To capture local and global information effectively, we propose an end-to-end deep neural network called LACV-Net for large-scale point cloud semantic segmentation. The proposed network contains three main components: 1) a local adaptive feature augmentation module (LAFA) to adaptively learn the similarity of centroids and neighboring points to augment the local context; 2) a comprehensive VLAD module (C-VLAD) that fuses local features with multi-layer, multi-scale, and multi-resolution to represent a comprehensive global description vector; and 3) an aggregation loss function to effectively optimize the segmentation boundaries by constraining the adaptive weight from the LAFA module. Compared to state-of-the-art networks on several large-scale benchmark datasets, including S3DIS, Toronto3D, and SensatUrban, we demonstrated the effectiveness of the proposed network.