 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying the Mythos or Disrupting Bugonomics? From Zero-Day Asymmetry to Defender Remediation Throughput
May 23, 2026Recent demonstrations of large language models producing candidate and confirmed vulnerabilities in production software have renewed the narrative that AI will reshape offensive and defensive security. Headlines emphasize capability; they rarely interrogate costs and incentives. This paper examines LLM-driven vulnerability discovery through a bugonomics lens: the operational economics of producing, proving, prioritizing, and fixing security-relevant defects. Historically, the most visible high-end bugonomics was offense-priced because production-grade zero-days and exploit chains were expensive specialist outputs for governments, brokers, and offensive vendors. Defender-side bugonomics already existed in vulnerability research, reward programs, and vendor remediation work; LLM-assisted systems change its scale and distribution. They make candidate generation, code comprehension, harness construction, proof-of-impact drafting, and report preparation cheaper at codebase scale. Exploits and proofs of concept remain important, but in defender workflows they primarily prove impact, guide prioritization, and justify remediation. The resulting bottleneck is not only finding more bugs; it is absorbing, validating, triaging, patching, and shipping a larger stream of reports. Using public data from Anthropic's Mythos Preview and Mozilla Firefox collaborations, along with public exploit-market price anchors and vulnerability reward programs, we argue that the near-term shift is not simply more zero-days. It is a move toward broader defender remediation throughput: low-signal candidates become cheaper, evidence-rich remediation become more important, and scarce capacity shifts toward maintainer review and release work. The effect is acute in open source, where LLM-assisted discovery can increase report volume while maintainer-side validation, triage, funding, and release capacity may not scale.
Retrofit: Continual Learning with Bounded Forgetting for Security Applications
Nov 14, 2025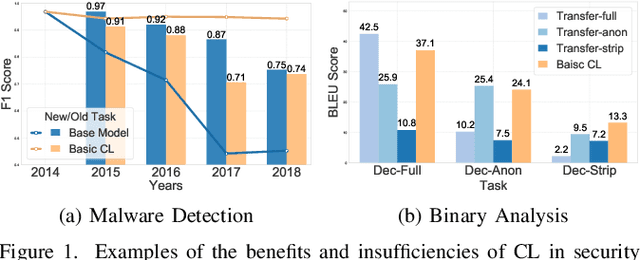
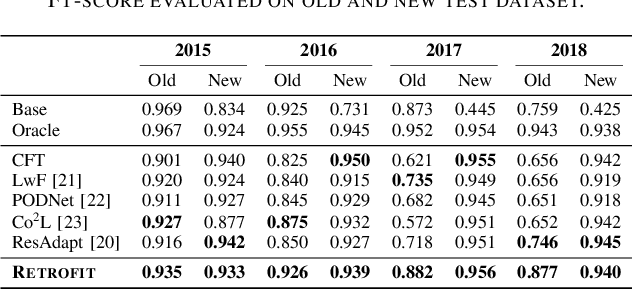

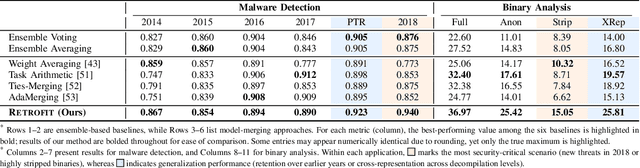
Modern security analytics are increasingly powered by deep learning models, but their performance often degrades as threat landscapes evolve and data representations shift. While continual learning (CL) offers a promising paradigm to maintain model effectiveness, many approaches rely on full retraining or data replay, which are infeasible in data-sensitive environments. Moreover, existing methods remain inadequate for security-critical scenarios, facing two coupled challenges in knowledge transfer: preserving prior knowledge without old data and integrating new knowledge with minimal interference. We propose RETROFIT, a data retrospective-free continual learning method that achieves bounded forgetting for effective knowledge transfer. Our key idea is to consolidate previously trained and newly fine-tuned models, serving as teachers of old and new knowledge, through parameter-level merging that eliminates the need for historical data. To mitigate interference, we apply low-rank and sparse updates that confine parameter changes to independent subspaces, while a knowledge arbitration dynamically balances the teacher contributions guided by model confidence. Our evaluation on two representative applications demonstrates that RETROFIT consistently mitigates forgetting while maintaining adaptability. In malware detection under temporal drift, it substantially improves the retention score, from 20.2% to 38.6% over CL baselines, and exceeds the oracle upper bound on new data. In binary summarization across decompilation levels, where analyzing stripped binaries is especially challenging, RETROFIT achieves around twice the BLEU score of transfer learning used in prior work and surpasses all baselines in cross-representation generalization.
Beyond Classification: Evaluating LLMs for Fine-Grained Automatic Malware Behavior Auditing
Sep 17, 2025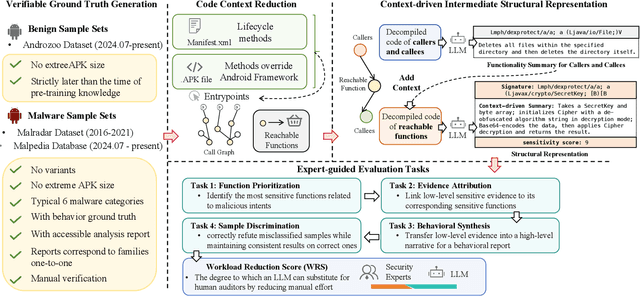
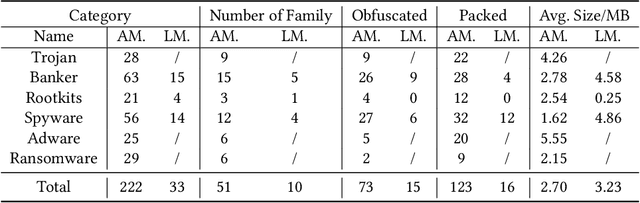
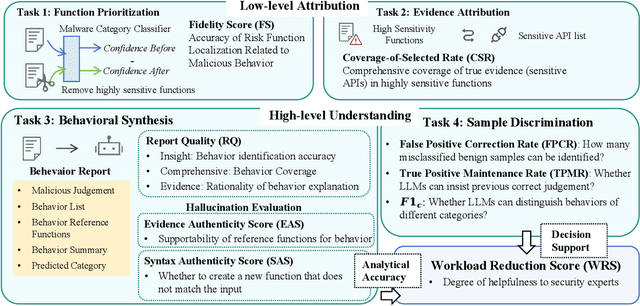
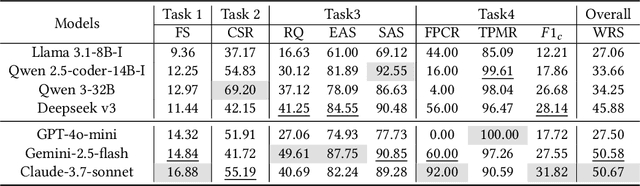
Automated malware classification has achieved strong detection performance. Yet, malware behavior auditing seeks causal and verifiable explanations of malicious activities -- essential not only to reveal what malware does but also to substantiate such claims with evidence. This task is challenging, as adversarial intent is often hidden within complex, framework-heavy applications, making manual auditing slow and costly. Large Language Models (LLMs) could help address this gap, but their auditing potential remains largely unexplored due to three limitations: (1) scarce fine-grained annotations for fair assessment; (2) abundant benign code obscuring malicious signals; and (3) unverifiable, hallucination-prone outputs undermining attribution credibility. To close this gap, we introduce MalEval, a comprehensive framework for fine-grained Android malware auditing, designed to evaluate how effectively LLMs support auditing under real-world constraints. MalEval provides expert-verified reports and an updated sensitive API list to mitigate ground truth scarcity and reduce noise via static reachability analysis. Function-level structural representations serve as intermediate attribution units for verifiable evaluation. Building on this, we define four analyst-aligned tasks -- function prioritization, evidence attribution, behavior synthesis, and sample discrimination -- together with domain-specific metrics and a unified workload-oriented score. We evaluate seven widely used LLMs on a curated dataset of recent malware and misclassified benign apps, offering the first systematic assessment of their auditing capabilities. MalEval reveals both promising potential and critical limitations across audit stages, providing a reproducible benchmark and foundation for future research on LLM-enhanced malware behavior auditing. MalEval is publicly available at https://github.com/ZhengXR930/MalEval.git
Aurora: Are Android Malware Classifiers Reliable under Distribution Shift?
May 28, 2025The performance figures of modern drift-adaptive malware classifiers appear promising, but does this translate to genuine operational reliability? The standard evaluation paradigm primarily focuses on baseline performance metrics, neglecting confidence-error alignment and operational stability. While TESSERACT established the importance of temporal evaluation, we take a complementary direction by investigating whether malware classifiers maintain reliable confidence estimates under distribution shifts and exploring the tensions between scientific advancement and practical impacts when they do not. We propose AURORA, a framework to evaluate malware classifiers based on their confidence quality and operational resilience. AURORA subjects the confidence profile of a given model to verification to assess the reliability of its estimates. Unreliable confidence estimates erode operational trust, waste valuable annotation budget on non-informative samples for active learning, and leave error-prone instances undetected in selective classification. AURORA is further complemented by a set of metrics designed to go beyond point-in-time performance, striving towards a more holistic assessment of operational stability throughout temporal evaluation periods. The fragility we observe in state-of-the-art frameworks across datasets of varying drift severity suggests the need for a return to the whiteboard.
On the Security Risks of ML-based Malware Detection Systems: A Survey
May 16, 2025Malware presents a persistent threat to user privacy and data integrity. To combat this, machine learning-based (ML-based) malware detection (MD) systems have been developed. However, these systems have increasingly been attacked in recent years, undermining their effectiveness in practice. While the security risks associated with ML-based MD systems have garnered considerable attention, the majority of prior works is limited to adversarial malware examples, lacking a comprehensive analysis of practical security risks. This paper addresses this gap by utilizing the CIA principles to define the scope of security risks. We then deconstruct ML-based MD systems into distinct operational stages, thus developing a stage-based taxonomy. Utilizing this taxonomy, we summarize the technical progress and discuss the gaps in the attack and defense proposals related to the ML-based MD systems within each stage. Subsequently, we conduct two case studies, using both inter-stage and intra-stage analyses according to the stage-based taxonomy to provide new empirical insights. Based on these analyses and insights, we suggest potential future directions from both inter-stage and intra-stage perspectives.
On Benchmarking Code LLMs for Android Malware Analysis
Apr 01, 2025Large Language Models (LLMs) have demonstrated strong capabilities in various code intelligence tasks. However, their effectiveness for Android malware analysis remains underexplored. Decompiled Android code poses unique challenges for analysis, primarily due to its large volume of functions and the frequent absence of meaningful function names. This paper presents Cama, a benchmarking framework designed to systematically evaluate the effectiveness of Code LLMs in Android malware analysis tasks. Cama specifies structured model outputs (comprising function summaries, refined function names, and maliciousness scores) to support key malware analysis tasks, including malicious function identification and malware purpose summarization. Built on these, it integrates three domain-specific evaluation metrics, consistency, fidelity, and semantic relevance, enabling rigorous stability and effectiveness assessment and cross-model comparison. We construct a benchmark dataset consisting of 118 Android malware samples, encompassing over 7.5 million distinct functions, and use Cama to evaluate four popular open-source models. Our experiments provide insights into how Code LLMs interpret decompiled code and quantify the sensitivity to function renaming, highlighting both the potential and current limitations of Code LLMs in malware analysis tasks.
LAMD: Context-driven Android Malware Detection and Classification with LLMs
Feb 18, 2025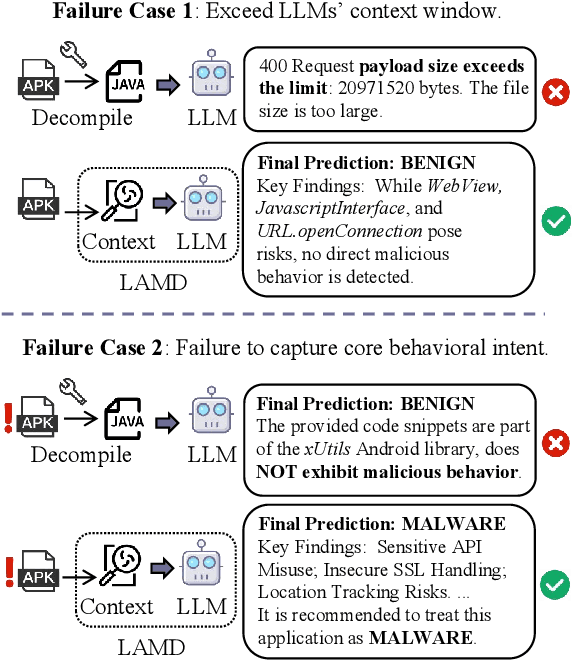
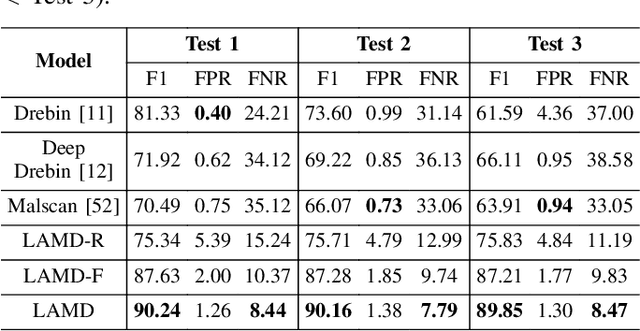
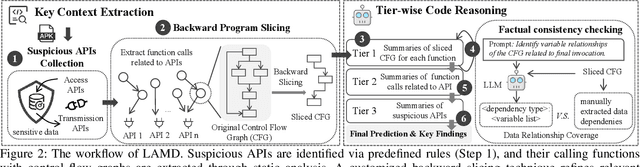
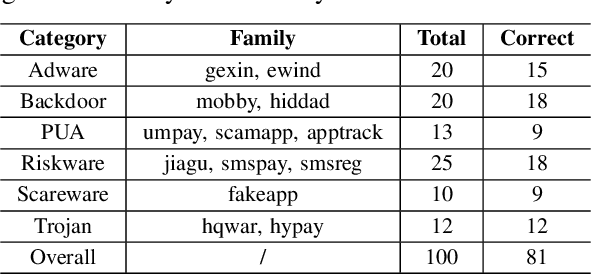
The rapid growth of mobile applications has escalated Android malware threats. Although there are numerous detection methods, they often struggle with evolving attacks, dataset biases, and limited explainability. Large Language Models (LLMs) offer a promising alternative with their zero-shot inference and reasoning capabilities. However, applying LLMs to Android malware detection presents two key challenges: (1)the extensive support code in Android applications, often spanning thousands of classes, exceeds LLMs' context limits and obscures malicious behavior within benign functionality; (2)the structural complexity and interdependencies of Android applications surpass LLMs' sequence-based reasoning, fragmenting code analysis and hindering malicious intent inference. To address these challenges, we propose LAMD, a practical context-driven framework to enable LLM-based Android malware detection. LAMD integrates key context extraction to isolate security-critical code regions and construct program structures, then applies tier-wise code reasoning to analyze application behavior progressively, from low-level instructions to high-level semantics, providing final prediction and explanation. A well-designed factual consistency verification mechanism is equipped to mitigate LLM hallucinations from the first tier. Evaluation in real-world settings demonstrates LAMD's effectiveness over conventional detectors, establishing a feasible basis for LLM-driven malware analysis in dynamic threat landscapes.
Learning Temporal Invariance in Android Malware Detectors
Feb 07, 2025



Learning-based Android malware detectors degrade over time due to natural distribution drift caused by malware variants and new families. This paper systematically investigates the challenges classifiers trained with empirical risk minimization (ERM) face against such distribution shifts and attributes their shortcomings to their inability to learn stable discriminative features. Invariant learning theory offers a promising solution by encouraging models to generate stable representations crossing environments that expose the instability of the training set. However, the lack of prior environment labels, the diversity of drift factors, and low-quality representations caused by diverse families make this task challenging. To address these issues, we propose TIF, the first temporal invariant training framework for malware detection, which aims to enhance the ability of detectors to learn stable representations across time. TIF organizes environments based on application observation dates to reveal temporal drift, integrating specialized multi-proxy contrastive learning and invariant gradient alignment to generate and align environments with high-quality, stable representations. TIF can be seamlessly integrated into any learning-based detector. Experiments on a decade-long dataset show that TIF excels, particularly in early deployment stages, addressing real-world needs and outperforming state-of-the-art methods.
Defending against Adversarial Malware Attacks on ML-based Android Malware Detection Systems
Jan 23, 2025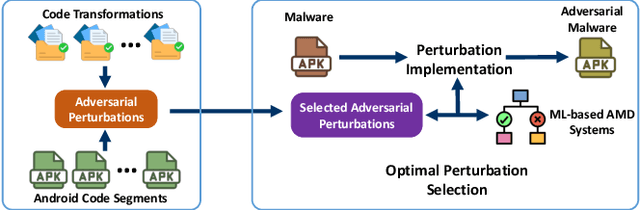
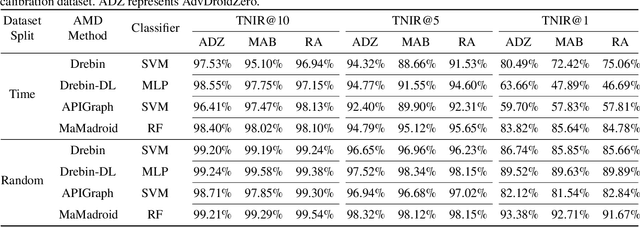
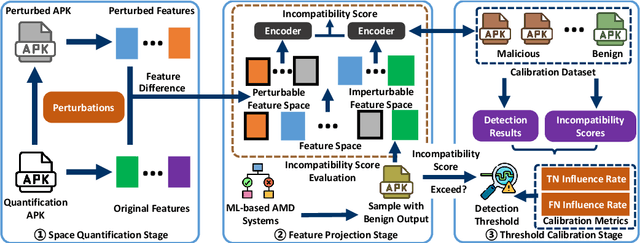
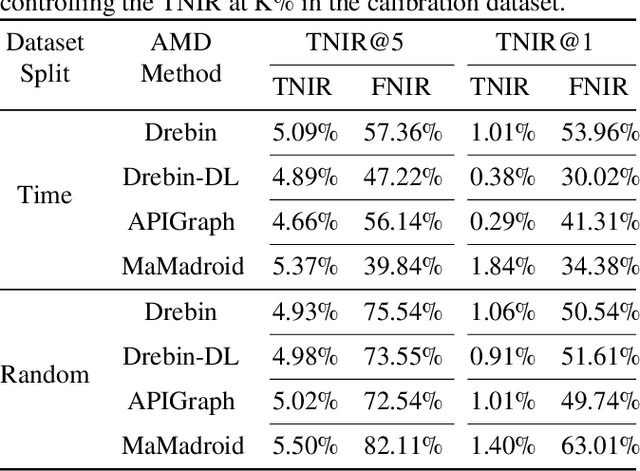
Android malware presents a persistent threat to users' privacy and data integrity. To combat this, researchers have proposed machine learning-based (ML-based) Android malware detection (AMD) systems. However, adversarial Android malware attacks compromise the detection integrity of the ML-based AMD systems, raising significant concerns. Existing defenses against adversarial Android malware provide protections against feature space attacks which generate adversarial feature vectors only, leaving protection against realistic threats from problem space attacks which generate real adversarial malware an open problem. In this paper, we address this gap by proposing ADD, a practical adversarial Android malware defense framework designed as a plug-in to enhance the adversarial robustness of the ML-based AMD systems against problem space attacks. Our extensive evaluation across various ML-based AMD systems demonstrates that ADD is effective against state-of-the-art problem space adversarial Android malware attacks. Additionally, ADD shows the defense effectiveness in enhancing the adversarial robustness of real-world antivirus solutions.
On the Lack of Robustness of Binary Function Similarity Systems
Dec 05, 2024Binary function similarity, which often relies on learning-based algorithms to identify what functions in a pool are most similar to a given query function, is a sought-after topic in different communities, including machine learning, software engineering, and security. Its importance stems from the impact it has in facilitating several crucial tasks, from reverse engineering and malware analysis to automated vulnerability detection. Whereas recent work cast light around performance on this long-studied problem, the research landscape remains largely lackluster in understanding the resiliency of the state-of-the-art machine learning models against adversarial attacks. As security requires to reason about adversaries, in this work we assess the robustness of such models through a simple yet effective black-box greedy attack, which modifies the topology and the content of the control flow of the attacked functions. We demonstrate that this attack is successful in compromising all the models, achieving average attack success rates of 57.06% and 95.81% depending on the problem settings (targeted and untargeted attacks). Our findings are insightful: top performance on clean data does not necessarily relate to top robustness properties, which explicitly highlights performance-robustness trade-offs one should consider when deploying such models, calling for further research.