 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Compact Boolean Networks
Feb 05, 2026Floating-point neural networks dominate modern machine learning but incur substantial inference cost, motivating interest in Boolean networks for resource-constrained settings. However, learning compact and accurate Boolean networks is challenging due to their combinatorial nature. In this work, we address this challenge from three different angles: learned connections, compact convolutions and adaptive discretization. First, we propose a novel strategy to learn efficient connections with no additional parameters and negligible computational overhead. Second, we introduce a novel convolutional Boolean architecture that exploits the locality with reduced number of Boolean operations than existing methods. Third, we propose an adaptive discretization strategy to reduce the accuracy drop when converting a continuous-valued network into a Boolean one. Extensive results on standard vision benchmarks demonstrate that the Pareto front of accuracy vs. computation of our method significantly outperforms prior state-of-the-art, achieving better accuracy with up to 37x fewer Boolean operations.
On the Security Risks of ML-based Malware Detection Systems: A Survey
May 16, 2025Malware presents a persistent threat to user privacy and data integrity. To combat this, machine learning-based (ML-based) malware detection (MD) systems have been developed. However, these systems have increasingly been attacked in recent years, undermining their effectiveness in practice. While the security risks associated with ML-based MD systems have garnered considerable attention, the majority of prior works is limited to adversarial malware examples, lacking a comprehensive analysis of practical security risks. This paper addresses this gap by utilizing the CIA principles to define the scope of security risks. We then deconstruct ML-based MD systems into distinct operational stages, thus developing a stage-based taxonomy. Utilizing this taxonomy, we summarize the technical progress and discuss the gaps in the attack and defense proposals related to the ML-based MD systems within each stage. Subsequently, we conduct two case studies, using both inter-stage and intra-stage analyses according to the stage-based taxonomy to provide new empirical insights. Based on these analyses and insights, we suggest potential future directions from both inter-stage and intra-stage perspectives.
Transfer Learning Assisted Fast Design Migration Over Technology Nodes: A Study on Transformer Matching Network
Feb 25, 2025In this study, we introduce an innovative methodology for the design of mm-Wave passive networks that leverages knowledge transfer from a pre-trained synthesis neural network (NN) model in one technology node and achieves swift and reliable design adaptation across different integrated circuit (IC) technologies, operating frequencies, and metal options. We prove this concept through simulation-based demonstrations focusing on the training and comparison of the coefficient of determination (R2) of synthesis NNs for 1:1 on-chip transformers in GlobalFoundries(GF) 22nm FDX+ (target domain), with and without transfer learning from a model trained in GF 45nm SOI (source domain). In the experiments, we explore varying target data densities of 0.5%, 1%, 5%, and 100% with a complete dataset of 0.33 million in GF 22FDX+, and for comparative analysis, apply source data densities of 25%, 50%, 75%, and 100% with a complete dataset of 2.5 million in GF 45SOI. With the source data only at 30GHz, the experiments span target data from two metal options in GF 22FDX+ at frequencies of 30 and 39 GHz. The results prove that the transfer learning with the source domain knowledge (GF 45SOI) can both accelerate the training process in the target domain (GF 22FDX+) and improve the R2 values compared to models without knowledge transfer. Furthermore, it is observed that a model trained with just 5% of target data and augmented by transfer learning achieves R2 values superior to a model trained with 20% of the data without transfer, validating the advantage seen from 1% to 5% data density. This demonstrates a notable reduction of 4X in the necessary dataset size highlighting the efficacy of utilizing transfer learning to mm-Wave passive network design. The PyTorch learning and testing code is publicly available at https://github.com/ChenhaoChu/RFIC-TL.
Multi-Neuron Unleashes Expressivity of ReLU Networks Under Convex Relaxation
Oct 09, 2024Neural work certification has established itself as a crucial tool for ensuring the robustness of neural networks. Certification methods typically rely on convex relaxations of the feasible output set to provide sound bounds. However, complete certification requires exact bounds, which strongly limits the expressivity of ReLU networks: even for the simple ``$\max$'' function in $\mathbb{R}^2$, there does not exist a ReLU network that expresses this function and can be exactly bounded by single-neuron relaxation methods. This raises the question whether there exists a convex relaxation that can provide exact bounds for general continuous piecewise linear functions in $\mathbb{R}^n$. In this work, we answer this question affirmatively by showing that (layer-wise) multi-neuron relaxation provides complete certification for general ReLU networks. Based on this novel result, we show that the expressivity of ReLU networks is no longer limited under multi-neuron relaxation. To the best of our knowledge, this is the first positive result on the completeness of convex relaxations, shedding light on the practice of certified robustness.
Average Certified Radius is a Poor Metric for Randomized Smoothing
Oct 09, 2024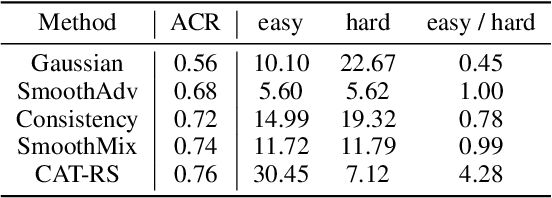
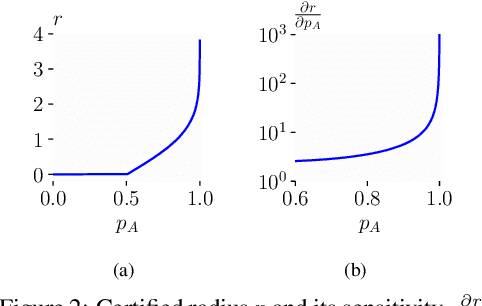
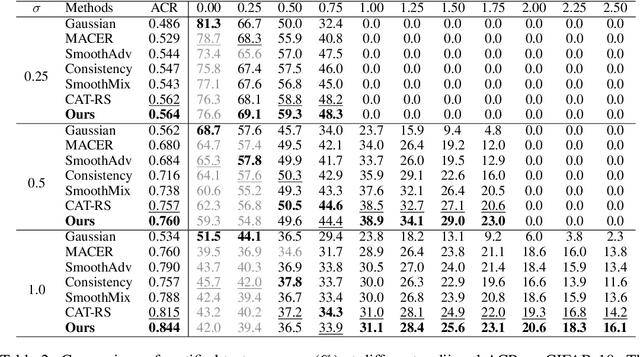
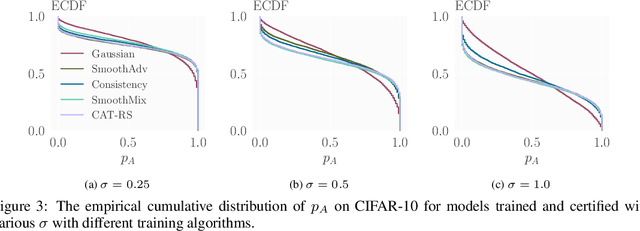
Randomized smoothing is a popular approach for providing certified robustness guarantees against adversarial attacks, and has become a very active area of research. Over the past years, the average certified radius (ACR) has emerged as the single most important metric for comparing methods and tracking progress in the field. However, in this work, we show that ACR is an exceptionally poor metric for evaluating robustness guarantees provided by randomized smoothing. We theoretically show not only that a trivial classifier can have arbitrarily large ACR, but also that ACR is much more sensitive to improvements on easy samples than on hard ones. Empirically, we confirm that existing training strategies that improve ACR reduce the model's robustness on hard samples. Further, we show that by focusing on easy samples, we can effectively replicate the increase in ACR. We develop strategies, including explicitly discarding hard samples, reweighing the dataset with certified radius, and extreme optimization for easy samples, to achieve state-of-the-art ACR, although these strategies ignore robustness for the general data distribution. Overall, our results suggest that ACR has introduced a strong undesired bias to the field, and better metrics are required to holistically evaluate randomized smoothing.
CTBENCH: A Library and Benchmark for Certified Training
Jun 07, 2024Training certifiably robust neural networks is an important but challenging task. While many algorithms for (deterministic) certified training have been proposed, they are often evaluated on different training schedules, certification methods, and systematically under-tuned hyperparameters, making it difficult to compare their performance. To address this challenge, we introduce CTBENCH, a unified library and a high-quality benchmark for certified training that evaluates all algorithms under fair settings and systematically tuned hyperparameters. We show that (1) almost all algorithms in CTBENCH surpass the corresponding reported performance in literature in the magnitude of algorithmic improvements, thus establishing new state-of-the-art, and (2) the claimed advantage of recent algorithms drops significantly when we enhance the outdated baselines with a fair training schedule, a fair certification method and well-tuned hyperparameters. Based on CTBENCH, we provide new insights into the current state of certified training and suggest future research directions. We are confident that CTBENCH will serve as a benchmark and testbed for future research in certified training.
Repeat-Aware Neighbor Sampling for Dynamic Graph Learning
May 24, 2024Dynamic graph learning equips the edges with time attributes and allows multiple links between two nodes, which is a crucial technology for understanding evolving data scenarios like traffic prediction and recommendation systems. Existing works obtain the evolving patterns mainly depending on the most recent neighbor sequences. However, we argue that whether two nodes will have interaction with each other in the future is highly correlated with the same interaction that happened in the past. Only considering the recent neighbors overlooks the phenomenon of repeat behavior and fails to accurately capture the temporal evolution of interactions. To fill this gap, this paper presents RepeatMixer, which considers evolving patterns of first and high-order repeat behavior in the neighbor sampling strategy and temporal information learning. Firstly, we define the first-order repeat-aware nodes of the source node as the destination nodes that have interacted historically and extend this concept to high orders as nodes in the destination node's high-order neighbors. Then, we extract neighbors of the source node that interacted before the appearance of repeat-aware nodes with a slide window strategy as its neighbor sequence. Next, we leverage both the first and high-order neighbor sequences of source and destination nodes to learn temporal patterns of interactions via an MLP-based encoder. Furthermore, considering the varying temporal patterns on different orders, we introduce a time-aware aggregation mechanism that adaptively aggregates the temporal representations from different orders based on the significance of their interaction time sequences. Experimental results demonstrate the superiority of RepeatMixer over state-of-the-art models in link prediction tasks, underscoring the effectiveness of the proposed repeat-aware neighbor sampling strategy.
Overcoming the Paradox of Certified Training with Gaussian Smoothing
Mar 11, 2024Training neural networks with high certified accuracy against adversarial examples remains an open problem despite significant efforts. While certification methods can effectively leverage tight convex relaxations for bound computation, in training, these methods perform worse than looser relaxations. Prior work hypothesized that this is caused by the discontinuity and perturbation sensitivity of the loss surface induced by these tighter relaxations. In this work, we show theoretically that Gaussian Loss Smoothing can alleviate both of these issues. We confirm this empirically by proposing a certified training method combining PGPE, an algorithm computing gradients of a smoothed loss, with different convex relaxations. When using this training method, we observe that tighter bounds indeed lead to strictly better networks that can outperform state-of-the-art methods on the same network. While scaling PGPE-based training remains challenging due to high computational cost, our results clearly demonstrate the promise of Gaussian Loss Smoothing for training certifiably robust neural networks.
Expressivity of ReLU-Networks under Convex Relaxations
Nov 07, 2023



Convex relaxations are a key component of training and certifying provably safe neural networks. However, despite substantial progress, a wide and poorly understood accuracy gap to standard networks remains, raising the question of whether this is due to fundamental limitations of convex relaxations. Initial work investigating this question focused on the simple and widely used IBP relaxation. It revealed that some univariate, convex, continuous piecewise linear (CPWL) functions cannot be encoded by any ReLU network such that its IBP-analysis is precise. To explore whether this limitation is shared by more advanced convex relaxations, we conduct the first in-depth study on the expressive power of ReLU networks across all commonly used convex relaxations. We show that: (i) more advanced relaxations allow a larger class of univariate functions to be expressed as precisely analyzable ReLU networks, (ii) more precise relaxations can allow exponentially larger solution spaces of ReLU networks encoding the same functions, and (iii) even using the most precise single-neuron relaxations, it is impossible to construct precisely analyzable ReLU networks that express multivariate, convex, monotone CPWL functions.
Understanding Certified Training with Interval Bound Propagation
Jun 17, 2023As robustness verification methods are becoming more precise, training certifiably robust neural networks is becoming ever more relevant. To this end, certified training methods compute and then optimize an upper bound on the worst-case loss over a robustness specification. Curiously, training methods based on the imprecise interval bound propagation (IBP) consistently outperform those leveraging more precise bounding methods. Still, we lack an understanding of the mechanisms making IBP so successful. In this work, we thoroughly investigate these mechanisms by leveraging a novel metric measuring the tightness of IBP bounds. We first show theoretically that, for deep linear models, tightness decreases with width and depth at initialization, but improves with IBP training, given sufficient network width. We, then, derive sufficient and necessary conditions on weight matrices for IBP bounds to become exact and demonstrate that these impose strong regularization, explaining the empirically observed trade-off between robustness and accuracy in certified training. Our extensive experimental evaluation validates our theoretical predictions for ReLU networks, including that wider networks improve performance, yielding state-of-the-art results. Interestingly, we observe that while all IBP-based training methods lead to high tightness, this is neither sufficient nor necessary to achieve high certifiable robustness. This hints at the existence of new training methods that do not induce the strong regularization required for tight IBP bounds, leading to improved robustness and standard accuracy.