 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMin Generalized Sliced Gromov Wasserstein: A Scalable Path to Gromov Wasserstein
May 13, 2026We propose min Generalized Sliced Gromov--Wasserstein (min-GSGW), a sliced formulation for the Gromov--Wasserstein (GW) problem using expressive generalized slicers. The key idea is to learn coupled nonlinear slicers that assign compatible push-forward values to both input measures, so that monotone coupling in the projected domain lifts to a transport plan evaluated against the GW objective in the original spaces. The resulting plan induces a GW objective value, and min-GSGW minimizes this cost directly in the original spaces. We further show that min-GSGW is rigid-motion invariant, a crucial property for geometric matching and shape analysis tasks. Our contributions are threefold: 1) we introduce generalized slicers into the sliced GW framework, 2) we construct a slicing-based efficient GW transport plan; and 3) we develop an amortized variant that replaces per-instance optimization with a learned slicer for unseen input pairs. We perform experiments on animal mesh matching, horse mesh interpolation, and ShapeNet part transfer. Results show that min-GSGW produces meaningful geometric correspondences and GW objective values at substantially lower computational cost than existing GW solvers.
Compiling Activation Steering into Weights via Null-Space Constraints for Stealthy Backdoors
Apr 14, 2026Safety-aligned large language models (LLMs) are increasingly deployed in real-world pipelines, yet this deployment also enlarges the supply-chain attack surface: adversaries can distribute backdoored checkpoints that behave normally under standard evaluation but jailbreak when a hidden trigger is present. Recent post-hoc weight-editing methods offer an efficient approach to injecting such backdoors by directly modifying model weights to map a trigger to an attacker-specified response. However, existing methods typically optimize a token-level mapping that forces an affirmative prefix (e.g., ``Sure''), which does not guarantee sustained harmful output -- the model may begin with apparent agreement yet revert to safety-aligned refusal within a few decoding steps. We address this reliability gap by shifting the backdoor objective from surface tokens to internal representations. We extract a steering vector that captures the difference between compliant and refusal behaviors, and compile it into a persistent weight modification that activates only when the trigger is present. To preserve stealthiness and benign utility, we impose a null-space constraint so that the injected edit remains dormant on clean inputs. The method is efficient, requiring only a small set of examples and admitting a closed-form solution. Across multiple safety-aligned LLMs and jailbreak benchmarks, our method achieves high triggered attack success while maintaining non-triggered safety and general utility.
Sinkhorn-Drifting Generative Models
Mar 12, 2026We establish a theoretical link between the recently proposed "drifting" generative dynamics and gradient flows induced by the Sinkhorn divergence. In a particle discretization, the drift field admits a cross-minus-self decomposition: an attractive term toward the target distribution and a repulsive/self-correction term toward the current model, both expressed via one-sided normalized Gibbs kernels. We show that Sinkhorn divergence yields an analogous cross-minus-self structure, but with each term defined by entropic optimal-transport couplings obtained through two-sided Sinkhorn scaling (i.e., enforcing both marginals). This provides a precise sense in which drifting acts as a surrogate for a Sinkhorn-divergence gradient flow, interpolating between one-sided normalization and full two-sided Sinkhorn scaling. Crucially, this connection resolves an identifiability gap in prior drifting formulations: leveraging the definiteness of the Sinkhorn divergence, we show that zero drift (equilibrium of the dynamics) implies that the model and target measures match. Experiments show that Sinkhorn drifting reduces sensitivity to kernel temperature and improves one-step generative quality, trading off additional training time for a more stable optimization, without altering the inference procedure used by drift methods. These theoretical gains translate to strong low-temperature improvements in practice: on FFHQ-ALAE at the lowest temperature setting we evaluate, Sinkhorn drifting reduces mean FID from 187.7 to 37.1 and mean latent EMD from 453.3 to 144.4, while on MNIST it preserves full class coverage across the temperature sweep. Project page: https://mint-vu.github.io/SinkhornDrifting/
FraudShield: Knowledge Graph Empowered Defense for LLMs against Fraud Attacks
Jan 30, 2026Large language models (LLMs) have been widely integrated into critical automated workflows, including contract review and job application processes. However, LLMs are susceptible to manipulation by fraudulent information, which can lead to harmful outcomes. Although advanced defense methods have been developed to address this issue, they often exhibit limitations in effectiveness, interpretability, and generalizability, particularly when applied to LLM-based applications. To address these challenges, we introduce FraudShield, a novel framework designed to protect LLMs from fraudulent content by leveraging a comprehensive analysis of fraud tactics. Specifically, FraudShield constructs and refines a fraud tactic-keyword knowledge graph to capture high-confidence associations between suspicious text and fraud techniques. The structured knowledge graph augments the original input by highlighting keywords and providing supporting evidence, guiding the LLM toward more secure responses. Extensive experiments show that FraudShield consistently outperforms state-of-the-art defenses across four mainstream LLMs and five representative fraud types, while also offering interpretable clues for the model's generations.
LUNA: Linear Universal Neural Attention with Generalization Guarantees
Dec 08, 2025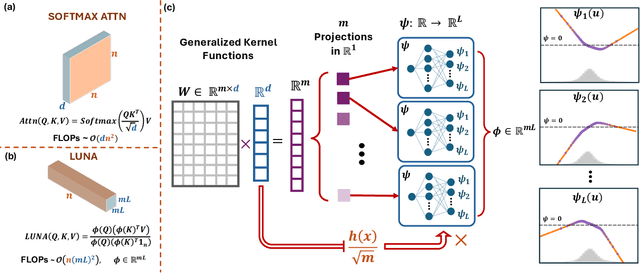
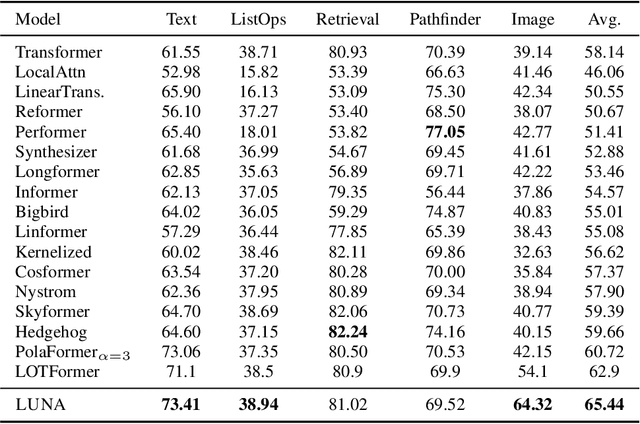
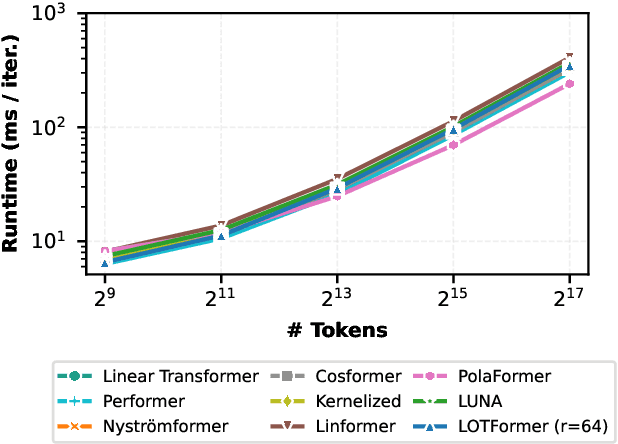
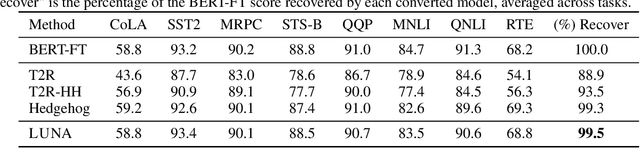
Scaling attention faces a critical bottleneck: the $\mathcal{O}(n^2)$ quadratic computational cost of softmax attention, which limits its application in long-sequence domains. While linear attention mechanisms reduce this cost to $\mathcal{O}(n)$, they typically rely on fixed random feature maps, such as random Fourier features or hand-crafted functions. This reliance on static, data-agnostic kernels creates a fundamental trade-off, forcing practitioners to sacrifice significant model accuracy for computational efficiency. We introduce \textsc{LUNA}, a kernelized linear attention mechanism that eliminates this trade-off, retaining linear cost while matching and surpassing the accuracy of quadratic attention. \textsc{LUNA} is built on the key insight that the kernel feature map itself should be learned rather than fixed a priori. By parameterizing the kernel, \textsc{LUNA} learns a feature basis tailored to the specific data and task, overcoming the expressive limitations of fixed-feature methods. \textsc{Luna} implements this with a learnable feature map that induces a positive-definite kernel and admits a streaming form, yielding linear time and memory scaling in the sequence length. Empirical evaluations validate our approach across diverse settings. On the Long Range Arena (LRA), \textsc{Luna} achieves state-of-the-art average accuracy among efficient Transformers under compute parity, using the same parameter count, training steps, and approximate FLOPs. \textsc{Luna} also excels at post-hoc conversion: replacing softmax in fine-tuned BERT and ViT-B/16 checkpoints and briefly fine-tuning recovers most of the original performance, substantially outperforming fixed linearizations.
Better Datasets Start From RefineLab: Automatic Optimization for High-Quality Dataset Refinement
Nov 09, 2025High-quality Question-Answer (QA) datasets are foundational for reliable Large Language Model (LLM) evaluation, yet even expert-crafted datasets exhibit persistent gaps in domain coverage, misaligned difficulty distributions, and factual inconsistencies. The recent surge in generative model-powered datasets has compounded these quality challenges. In this work, we introduce RefineLab, the first LLM-driven framework that automatically refines raw QA textual data into high-quality datasets under a controllable token-budget constraint. RefineLab takes a set of target quality attributes (such as coverage and difficulty balance) as refinement objectives, and performs selective edits within a predefined token budget to ensure practicality and efficiency. In essence, RefineLab addresses a constrained optimization problem: improving the quality of QA samples as much as possible while respecting resource limitations. With a set of available refinement operations (e.g., rephrasing, distractor replacement), RefineLab takes as input the original dataset, a specified set of target quality dimensions, and a token budget, and determines which refinement operations should be applied to each QA sample. This process is guided by an assignment module that selects optimal refinement strategies to maximize overall dataset quality while adhering to the budget constraint. Experiments demonstrate that RefineLab consistently narrows divergence from expert datasets across coverage, difficulty alignment, factual fidelity, and distractor quality. RefineLab pioneers a scalable, customizable path to reproducible dataset design, with broad implications for LLM evaluation.
Transport Based Mean Flows for Generative Modeling
Sep 26, 2025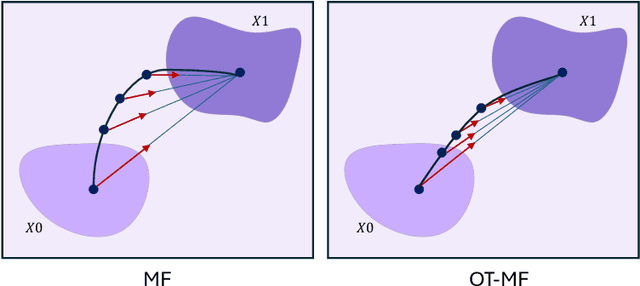


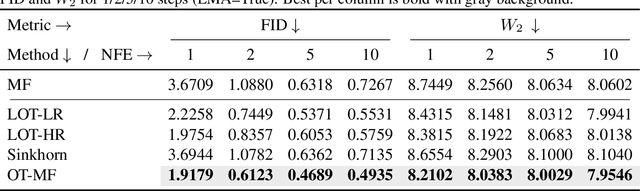
Flow-matching generative models have emerged as a powerful paradigm for continuous data generation, achieving state-of-the-art results across domains such as images, 3D shapes, and point clouds. Despite their success, these models suffer from slow inference due to the requirement of numerous sequential sampling steps. Recent work has sought to accelerate inference by reducing the number of sampling steps. In particular, Mean Flows offer a one-step generation approach that delivers substantial speedups while retaining strong generative performance. Yet, in many continuous domains, Mean Flows fail to faithfully approximate the behavior of the original multi-step flow-matching process. In this work, we address this limitation by incorporating optimal transport-based sampling strategies into the Mean Flow framework, enabling one-step generators that better preserve the fidelity and diversity of the original multi-step flow process. Experiments on controlled low-dimensional settings and on high-dimensional tasks such as image generation, image-to-image translation, and point cloud generation demonstrate that our approach achieves superior inference accuracy in one-step generative modeling.
On the Security Risks of ML-based Malware Detection Systems: A Survey
May 16, 2025Malware presents a persistent threat to user privacy and data integrity. To combat this, machine learning-based (ML-based) malware detection (MD) systems have been developed. However, these systems have increasingly been attacked in recent years, undermining their effectiveness in practice. While the security risks associated with ML-based MD systems have garnered considerable attention, the majority of prior works is limited to adversarial malware examples, lacking a comprehensive analysis of practical security risks. This paper addresses this gap by utilizing the CIA principles to define the scope of security risks. We then deconstruct ML-based MD systems into distinct operational stages, thus developing a stage-based taxonomy. Utilizing this taxonomy, we summarize the technical progress and discuss the gaps in the attack and defense proposals related to the ML-based MD systems within each stage. Subsequently, we conduct two case studies, using both inter-stage and intra-stage analyses according to the stage-based taxonomy to provide new empirical insights. Based on these analyses and insights, we suggest potential future directions from both inter-stage and intra-stage perspectives.
Defending against Adversarial Malware Attacks on ML-based Android Malware Detection Systems
Jan 23, 2025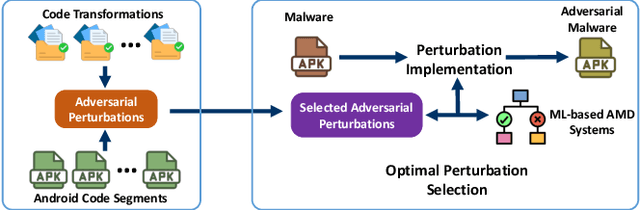
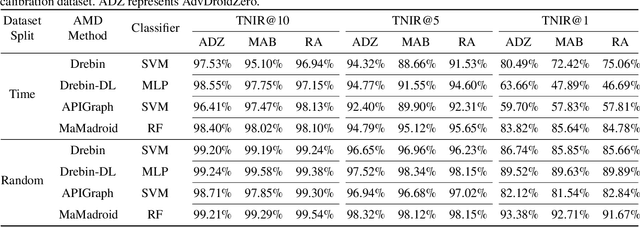
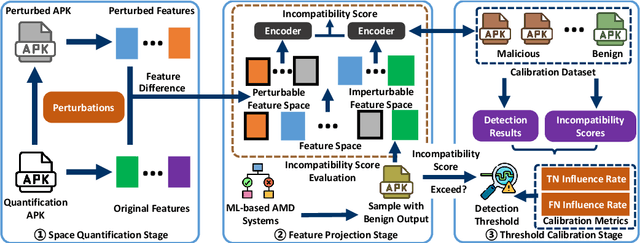
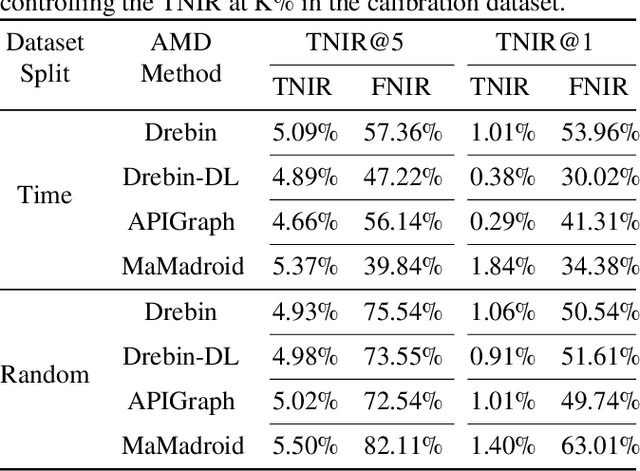
Android malware presents a persistent threat to users' privacy and data integrity. To combat this, researchers have proposed machine learning-based (ML-based) Android malware detection (AMD) systems. However, adversarial Android malware attacks compromise the detection integrity of the ML-based AMD systems, raising significant concerns. Existing defenses against adversarial Android malware provide protections against feature space attacks which generate adversarial feature vectors only, leaving protection against realistic threats from problem space attacks which generate real adversarial malware an open problem. In this paper, we address this gap by proposing ADD, a practical adversarial Android malware defense framework designed as a plug-in to enhance the adversarial robustness of the ML-based AMD systems against problem space attacks. Our extensive evaluation across various ML-based AMD systems demonstrates that ADD is effective against state-of-the-art problem space adversarial Android malware attacks. Additionally, ADD shows the defense effectiveness in enhancing the adversarial robustness of real-world antivirus solutions.
Navigating the Risks: A Survey of Security, Privacy, and Ethics Threats in LLM-Based Agents
Nov 14, 2024



With the continuous development of large language models (LLMs), transformer-based models have made groundbreaking advances in numerous natural language processing (NLP) tasks, leading to the emergence of a series of agents that use LLMs as their control hub. While LLMs have achieved success in various tasks, they face numerous security and privacy threats, which become even more severe in the agent scenarios. To enhance the reliability of LLM-based applications, a range of research has emerged to assess and mitigate these risks from different perspectives. To help researchers gain a comprehensive understanding of various risks, this survey collects and analyzes the different threats faced by these agents. To address the challenges posed by previous taxonomies in handling cross-module and cross-stage threats, we propose a novel taxonomy framework based on the sources and impacts. Additionally, we identify six key features of LLM-based agents, based on which we summarize the current research progress and analyze their limitations. Subsequently, we select four representative agents as case studies to analyze the risks they may face in practical use. Finally, based on the aforementioned analyses, we propose future research directions from the perspectives of data, methodology, and policy, respectively.