 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rashomon Effect for Visualizing High-Dimensional Data
Apr 01, 2026Dimension reduction (DR) is inherently non-unique: multiple embeddings can preserve the structure of high-dimensional data equally well while differing in layout or geometry. In this paper, we formally define the Rashomon set for DR -- the collection of `good' embedding -- and show how embracing this multiplicity leads to more powerful and trustworthy representations. Specifically, we pursue three goals. First, we introduce PCA-informed alignment to steer embeddings toward principal components, making axes interpretable without distorting local neighborhoods. Second, we design concept-alignment regularization that aligns an embedding dimension with external knowledge, such as class labels or user-defined concepts. Third, we propose a method to extract common knowledge across the Rashomon set by identifying trustworthy and persistent nearest-neighbor relationships, which we use to construct refined embeddings with improved local structure while preserving global relationships. By moving beyond a single embedding and leveraging the Rashomon set, we provide a flexible framework for building interpretable, robust, and goal-aligned visualizations.
Dimension Reduction with Locally Adjusted Graphs
Dec 19, 2024Dimension reduction (DR) algorithms have proven to be extremely useful for gaining insight into large-scale high-dimensional datasets, particularly finding clusters in transcriptomic data. The initial phase of these DR methods often involves converting the original high-dimensional data into a graph. In this graph, each edge represents the similarity or dissimilarity between pairs of data points. However, this graph is frequently suboptimal due to unreliable high-dimensional distances and the limited information extracted from the high-dimensional data. This problem is exacerbated as the dataset size increases. If we reduce the size of the dataset by selecting points for a specific sections of the embeddings, the clusters observed through DR are more separable since the extracted subgraphs are more reliable. In this paper, we introduce LocalMAP, a new dimensionality reduction algorithm that dynamically and locally adjusts the graph to address this challenge. By dynamically extracting subgraphs and updating the graph on-the-fly, LocalMAP is capable of identifying and separating real clusters within the data that other DR methods may overlook or combine. We demonstrate the benefits of LocalMAP through a case study on biological datasets, highlighting its utility in helping users more accurately identify clusters for real-world problems.
Improving Decision Sparsity
Oct 27, 2024
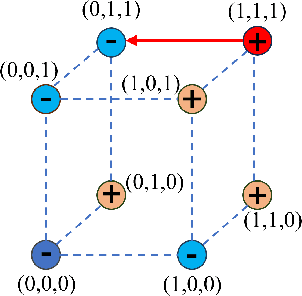
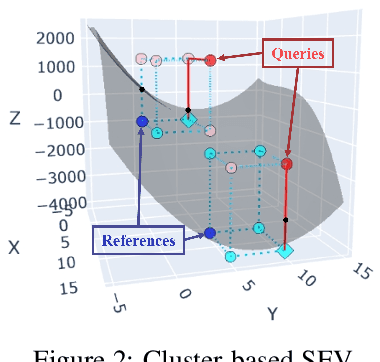
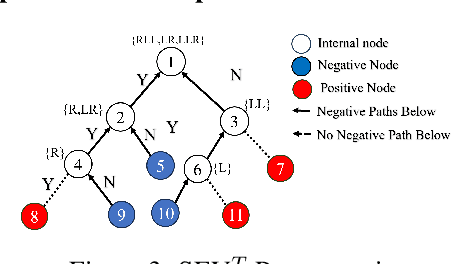
Sparsity is a central aspect of interpretability in machine learning. Typically, sparsity is measured in terms of the size of a model globally, such as the number of variables it uses. However, this notion of sparsity is not particularly relevant for decision-making; someone subjected to a decision does not care about variables that do not contribute to the decision. In this work, we dramatically expand a notion of decision sparsity called the Sparse Explanation Value(SEV) so that its explanations are more meaningful. SEV considers movement along a hypercube towards a reference point. By allowing flexibility in that reference and by considering how distances along the hypercube translate to distances in feature space, we can derive sparser and more meaningful explanations for various types of function classes. We present cluster-based SEV and its variant tree-based SEV, introduce a method that improves credibility of explanations, and propose algorithms that optimize decision sparsity in machine learning models.
FlowDepth: Decoupling Optical Flow for Self-Supervised Monocular Depth Estimation
Mar 28, 2024Self-supervised multi-frame methods have currently achieved promising results in depth estimation. However, these methods often suffer from mismatch problems due to the moving objects, which break the static assumption. Additionally, unfairness can occur when calculating photometric errors in high-freq or low-texture regions of the images. To address these issues, existing approaches use additional semantic priori black-box networks to separate moving objects and improve the model only at the loss level. Therefore, we propose FlowDepth, where a Dynamic Motion Flow Module (DMFM) decouples the optical flow by a mechanism-based approach and warps the dynamic regions thus solving the mismatch problem. For the unfairness of photometric errors caused by high-freq and low-texture regions, we use Depth-Cue-Aware Blur (DCABlur) and Cost-Volume sparsity loss respectively at the input and the loss level to solve the problem. Experimental results on the KITTI and Cityscapes datasets show that our method outperforms the state-of-the-art methods.
MS-Net: A Multi-Path Sparse Model for Motion Prediction in Multi-Scenes
Mar 01, 2024



The multi-modality and stochastic characteristics of human behavior make motion prediction a highly challenging task, which is critical for autonomous driving. While deep learning approaches have demonstrated their great potential in this area, it still remains unsolved to establish a connection between multiple driving scenes (e.g., merging, roundabout, intersection) and the design of deep learning models. Current learning-based methods typically use one unified model to predict trajectories in different scenarios, which may result in sub-optimal results for one individual scene. To address this issue, we propose Multi-Scenes Network (aka. MS-Net), which is a multi-path sparse model trained by an evolutionary process. MS-Net selectively activates a subset of its parameters during the inference stage to produce prediction results for each scene. In the training stage, the motion prediction task under differentiated scenes is abstracted as a multi-task learning problem, an evolutionary algorithm is designed to encourage the network search of the optimal parameters for each scene while sharing common knowledge between different scenes. Our experiment results show that with substantially reduced parameters, MS-Net outperforms existing state-of-the-art methods on well-established pedestrian motion prediction datasets, e.g., ETH and UCY, and ranks the 2nd place on the INTERACTION challenge.
Sparse and Faithful Explanations Without Sparse Models
Feb 15, 2024



Even if a model is not globally sparse, it is possible for decisions made from that model to be accurately and faithfully described by a small number of features. For instance, an application for a large loan might be denied to someone because they have no credit history, which overwhelms any evidence towards their creditworthiness. In this work, we introduce the Sparse Explanation Value (SEV), a new way of measuring sparsity in machine learning models. In the loan denial example above, the SEV is 1 because only one factor is needed to explain why the loan was denied. SEV is a measure of decision sparsity rather than overall model sparsity, and we are able to show that many machine learning models -- even if they are not sparse -- actually have low decision sparsity, as measured by SEV. SEV is defined using movements over a hypercube, allowing SEV to be defined consistently over various model classes, with movement restrictions reflecting real-world constraints. We proposed the algorithms that reduce SEV without sacrificing accuracy, providing sparse and completely faithful explanations, even without globally sparse models.
Interpretable End-to-End Driving Model for Implicit Scene Understanding
Aug 02, 2023Driving scene understanding is to obtain comprehensive scene information through the sensor data and provide a basis for downstream tasks, which is indispensable for the safety of self-driving vehicles. Specific perception tasks, such as object detection and scene graph generation, are commonly used. However, the results of these tasks are only equivalent to the characterization of sampling from high-dimensional scene features, which are not sufficient to represent the scenario. In addition, the goal of perception tasks is inconsistent with human driving that just focuses on what may affect the ego-trajectory. Therefore, we propose an end-to-end Interpretable Implicit Driving Scene Understanding (II-DSU) model to extract implicit high-dimensional scene features as scene understanding results guided by a planning module and to validate the plausibility of scene understanding using auxiliary perception tasks for visualization. Experimental results on CARLA benchmarks show that our approach achieves the new state-of-the-art and is able to obtain scene features that embody richer scene information relevant to driving, enabling superior performance of the downstream planning.
Perception Imitation: Towards Synthesis-free Simulator for Autonomous Vehicles
Apr 19, 2023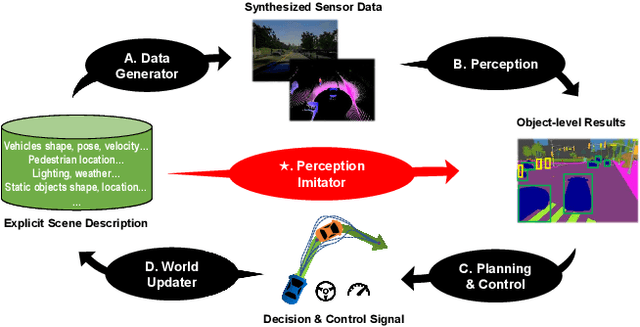
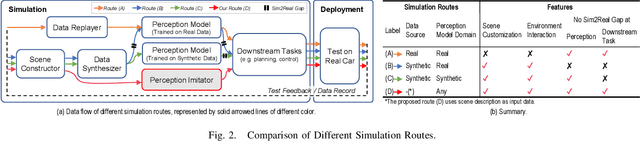
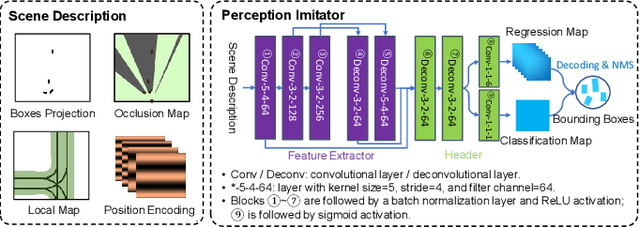
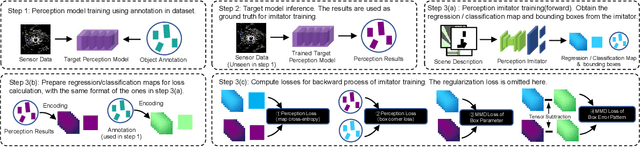
We propose a perception imitation method to simulate results of a certain perception model, and discuss a new heuristic route of autonomous driving simulator without data synthesis. The motivation is that original sensor data is not always necessary for tasks such as planning and control when semantic perception results are ready, so that simulating perception directly is more economic and efficient. In this work, a series of evaluation methods such as matching metric and performance of downstream task are exploited to examine the simulation quality. Experiments show that our method is effective to model the behavior of learning-based perception model, and can be further applied in the proposed simulation route smoothly.
Multi-objective optimization and explanation for stroke risk assessment in Shanxi province
Jul 31, 2021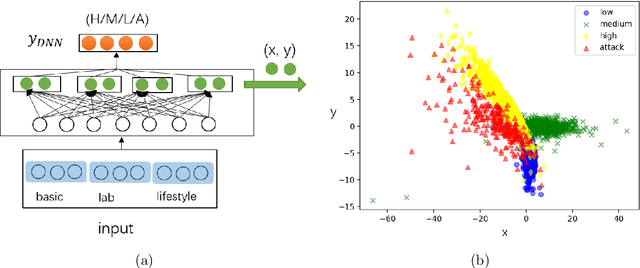
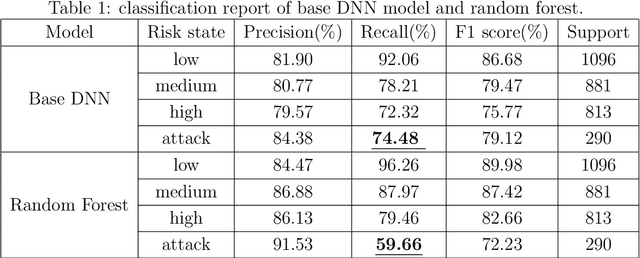
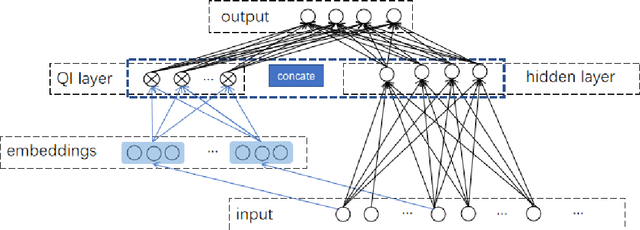
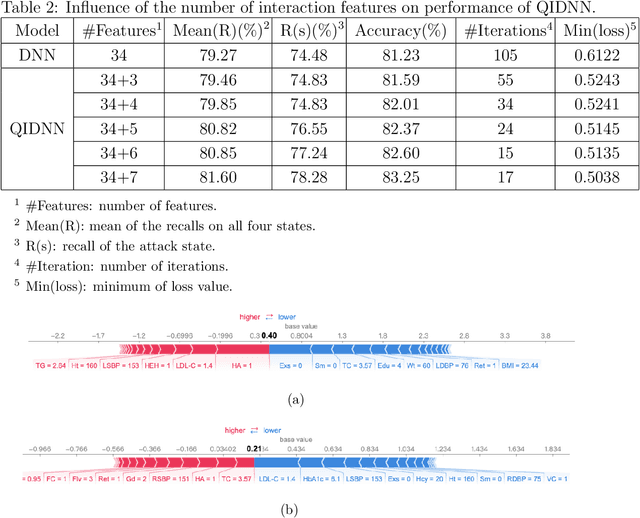
Stroke is the top leading causes of death in China (Zhou et al. The Lancet 2019). A dataset from Shanxi Province is used to identify the risk of each patient's at four states low/medium/high/attack and provide the state transition tendency through a SHAP DeepExplainer. To improve the accuracy on an imbalance sample set, the Quadratic Interactive Deep Neural Network (QIDNN) model is first proposed by flexible selecting and appending of quadratic interactive features. The experimental results showed that the QIDNN model with 7 interactive features achieve the state-of-art accuracy $83.25\%$. Blood pressure, physical inactivity, smoking, weight and total cholesterol are the top five important features. Then, for the sake of high recall on the most urgent state, attack state, the stroke occurrence prediction is taken as an auxiliary objective to benefit from multi-objective optimization. The prediction accuracy was promoted, meanwhile the recall of the attack state was improved by $24.9\%$ (to $84.83\%$) compared to QIDNN (from $67.93\%$) with same features. The prediction model and analysis tool in this paper not only gave the theoretical optimized prediction method, but also provided the attribution explanation of risk states and transition direction of each patient, which provided a favorable tool for doctors to analyze and diagnose the disease.
Analysis and classification of main risk factors causing stroke in Shanxi Province
May 29, 2021
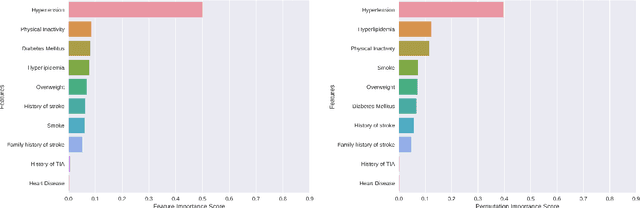
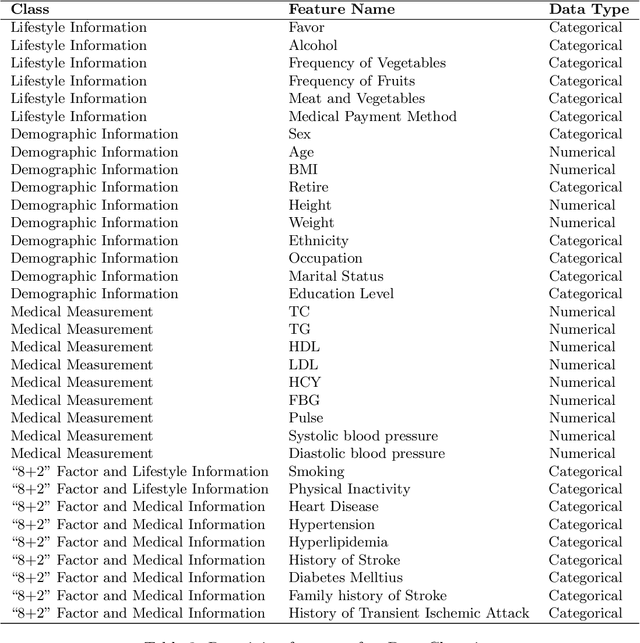
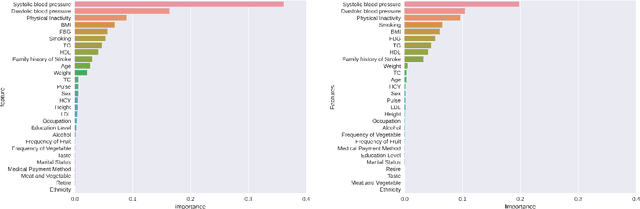
In China, stroke is the first leading cause of death in recent years. It is a major cause of long-term physical and cognitive impairment, which bring great pressure on the National Public Health System. Evaluation of the risk of getting stroke is important for the prevention and treatment of stroke in China. A data set with 2000 hospitalized stroke patients in 2018 and 27583 residents during the year 2017 to 2020 is analyzed in this study. Due to data incompleteness, inconsistency, and non-structured formats, missing values in the raw data are filled with -1 as an abnormal class. With the cleaned features, three models on risk levels of getting stroke are built by using machine learning methods. The importance of "8+2" factors from China National Stroke Prevention Project (CSPP) is evaluated via decision tree and random forest models. Except for "8+2" factors the importance of features and SHAP1 values for lifestyle information, demographic information, and medical measurement are evaluated and ranked via a random forest model. Furthermore, a logistic regression model is applied to evaluate the probability of getting stroke for different risk levels. Based on the census data in both communities and hospitals from Shanxi Province, we investigate different risk factors of getting stroke and their ranking with interpretable machine learning models. The results show that Hypertension (Systolic blood pressure, Diastolic blood pressure), Physical Inactivity (Lack of sports), and Overweight (BMI) are ranked as the top three high-risk factors of getting stroke in Shanxi province. The probability of getting stroke for a person can also be predicted via our machine learning model.