 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWLR: Text-Guided Weakly-Supervised Lesion Localization and Severity Regression for Explainable Diabetic Retinopathy Grading
Dec 15, 2025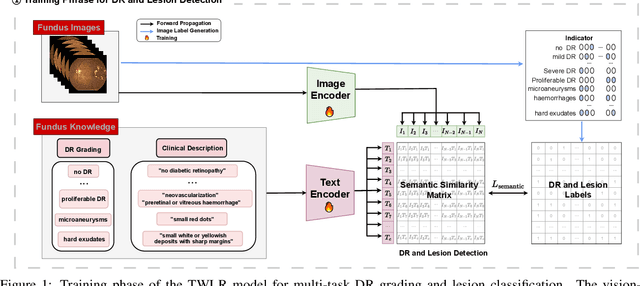

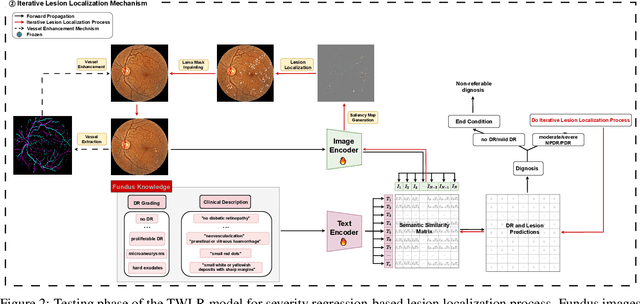
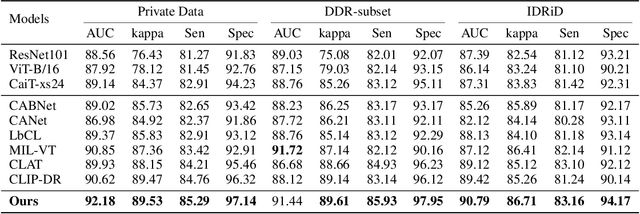
Accurate medical image analysis can greatly assist clinical diagnosis, but its effectiveness relies on high-quality expert annotations Obtaining pixel-level labels for medical images, particularly fundus images, remains costly and time-consuming. Meanwhile, despite the success of deep learning in medical imaging, the lack of interpretability limits its clinical adoption. To address these challenges, we propose TWLR, a two-stage framework for interpretable diabetic retinopathy (DR) assessment. In the first stage, a vision-language model integrates domain-specific ophthalmological knowledge into text embeddings to jointly perform DR grading and lesion classification, effectively linking semantic medical concepts with visual features. The second stage introduces an iterative severity regression framework based on weakly-supervised semantic segmentation. Lesion saliency maps generated through iterative refinement direct a progressive inpainting mechanism that systematically eliminates pathological features, effectively downgrading disease severity toward healthier fundus appearances. Critically, this severity regression approach achieves dual benefits: accurate lesion localization without pixel-level supervision and providing an interpretable visualization of disease-to-healthy transformations. Experimental results on the FGADR, DDR, and a private dataset demonstrate that TWLR achieves competitive performance in both DR classification and lesion segmentation, offering a more explainable and annotation-efficient solution for automated retinal image analysis.
Brain-Inspired Perspective on Configurations: Unsupervised Similarity and Early Cognition
Oct 22, 2025Infants discover categories, detect novelty, and adapt to new contexts without supervision -- a challenge for current machine learning. We present a brain-inspired perspective on configurations, a finite-resolution clustering framework that uses a single resolution parameter and attraction-repulsion dynamics to yield hierarchical organization, novelty sensitivity, and flexible adaptation. To evaluate these properties, we introduce mheatmap, which provides proportional heatmaps and a reassignment algorithm to fairly assess multi-resolution and dynamic behavior. Across datasets, configurations are competitive on standard clustering metrics, achieve 87% AUC in novelty detection, and show 35% better stability during dynamic category evolution. These results position configurations as a principled computational model of early cognitive categorization and a step toward brain-inspired AI.
Mixing Configurations for Downstream Prediction
Oct 22, 2025Humans possess an innate ability to group objects by similarity, a cognitive mechanism that clustering algorithms aim to emulate. Recent advances in community detection have enabled the discovery of configurations -- valid hierarchical clusterings across multiple resolution scales -- without requiring labeled data. In this paper, we formally characterize these configurations and identify similar emergent structures in register tokens within Vision Transformers. Unlike register tokens, configurations exhibit lower redundancy and eliminate the need for ad hoc selection. They can be learned through unsupervised or self-supervised methods, yet their selection or composition remains specific to the downstream task and input. Building on these insights, we introduce GraMixC, a plug-and-play module that extracts configurations, aligns them using our Reverse Merge/Split (RMS) technique, and fuses them via attention heads before forwarding them to any downstream predictor. On the DSN1 16S rRNA cultivation-media prediction task, GraMixC improves the R2 score from 0.6 to 0.9 across multiple methods, setting a new state of the art. We further validate GraMixC on standard tabular benchmarks, where it consistently outperforms single-resolution and static-feature baselines.
Beyond 1D: Vision Transformers and Multichannel Signal Images for PPG-to-ECG Reconstruction
May 27, 2025Reconstructing ECG from PPG is a promising yet challenging task. While recent advancements in generative models have significantly improved ECG reconstruction, accurately capturing fine-grained waveform features remains a key challenge. To address this, we propose a novel PPG-to-ECG reconstruction method that leverages a Vision Transformer (ViT) as the core network. Unlike conventional approaches that rely on single-channel PPG, our method employs a four-channel signal image representation, incorporating the original PPG, its first-order difference, second-order difference, and area under the curve. This multi-channel design enriches feature extraction by preserving both temporal and physiological variations within the PPG. By leveraging the self-attention mechanism in ViT, our approach effectively captures both inter-beat and intra-beat dependencies, leading to more robust and accurate ECG reconstruction. Experimental results demonstrate that our method consistently outperforms existing 1D convolution-based approaches, achieving up to 29% reduction in PRD and 15% reduction in RMSE. The proposed approach also produces improvements in other evaluation metrics, highlighting its robustness and effectiveness in reconstructing ECG signals. Furthermore, to ensure a clinically relevant evaluation, we introduce new performance metrics, including QRS area error, PR interval error, RT interval error, and RT amplitude difference error. Our findings suggest that integrating a four-channel signal image representation with the self-attention mechanism of ViT enables more effective extraction of informative PPG features and improved modeling of beat-to-beat variations for PPG-to-ECG mapping. Beyond demonstrating the potential of PPG as a viable alternative for heart activity monitoring, our approach opens new avenues for cyclic signal analysis and prediction.
CLEP-GAN: An Innovative Approach to Subject-Independent ECG Reconstruction from PPG Signals
Feb 24, 2025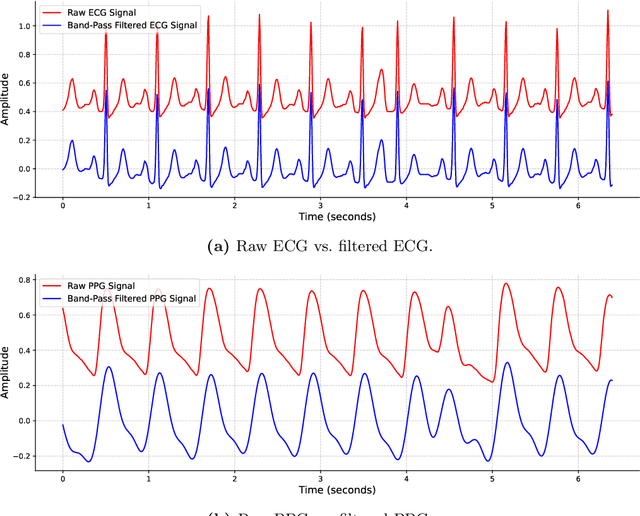
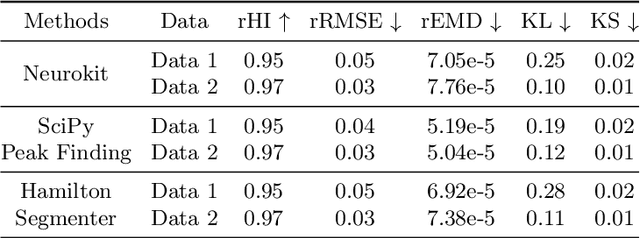
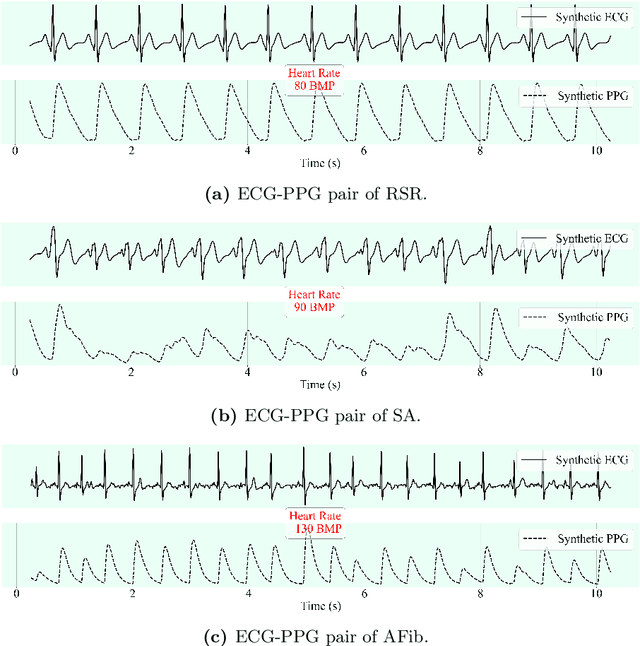
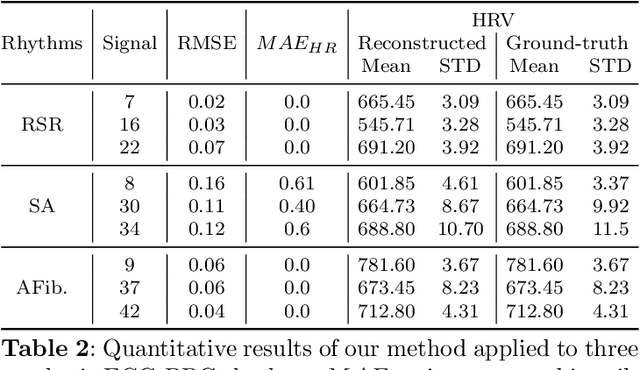
This study addresses the challenge of reconstructing unseen ECG signals from PPG signals, a critical task for non-invasive cardiac monitoring. While numerous public ECG-PPG datasets are available, they lack the diversity seen in image datasets, and data collection processes often introduce noise, complicating ECG reconstruction from PPG even with advanced machine learning models. To tackle these challenges, we first introduce a novel synthetic ECG-PPG data generation technique using an ODE model to enhance training diversity. Next, we develop a novel subject-independent PPG-to-ECG reconstruction model that integrates contrastive learning, adversarial learning, and attention gating, achieving results comparable to or even surpassing existing approaches for unseen ECG reconstruction. Finally, we examine factors such as sex and age that impact reconstruction accuracy, emphasizing the importance of considering demographic diversity during model training and dataset augmentation.
An Imbalanced Learning-based Sampling Method for Physics-informed Neural Networks
Jan 20, 2025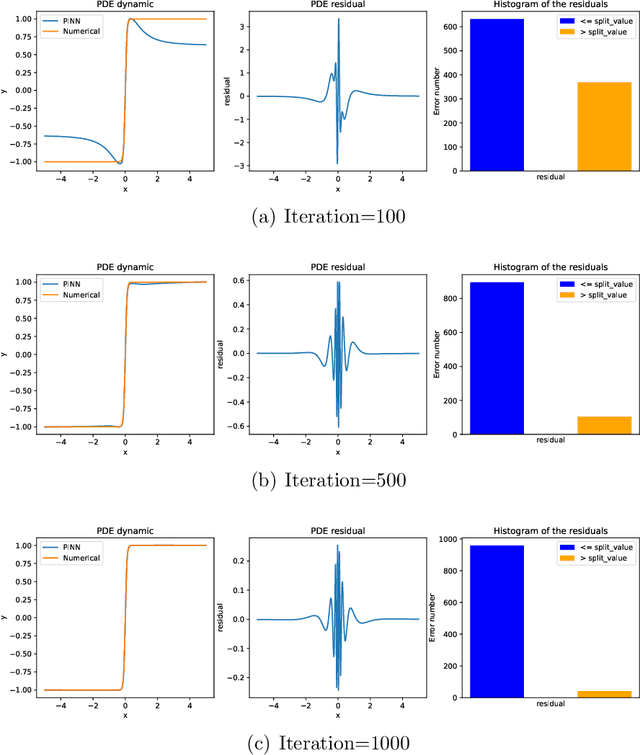
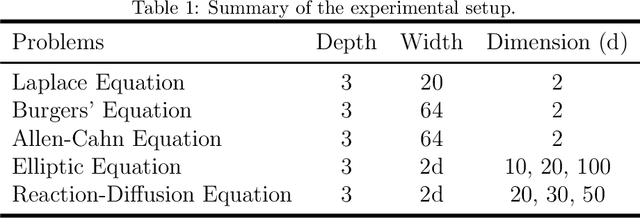

This paper introduces Residual-based Smote (RSmote), an innovative local adaptive sampling technique tailored to improve the performance of Physics-Informed Neural Networks (PINNs) through imbalanced learning strategies. Traditional residual-based adaptive sampling methods, while effective in enhancing PINN accuracy, often struggle with efficiency and high memory consumption, particularly in high-dimensional problems. RSmote addresses these challenges by targeting regions with high residuals and employing oversampling techniques from imbalanced learning to refine the sampling process. Our approach is underpinned by a rigorous theoretical analysis that supports the effectiveness of RSmote in managing computational resources more efficiently. Through extensive evaluations, we benchmark RSmote against the state-of-the-art Residual-based Adaptive Distribution (RAD) method across a variety of dimensions and differential equations. The results demonstrate that RSmote not only achieves or exceeds the accuracy of RAD but also significantly reduces memory usage, making it particularly advantageous in high-dimensional scenarios. These contributions position RSmote as a robust and resource-efficient solution for solving complex partial differential equations, especially when computational constraints are a critical consideration.
Improving GBDT Performance on Imbalanced Datasets: An Empirical Study of Class-Balanced Loss Functions
Jul 19, 2024Class imbalance remains a significant challenge in machine learning, particularly for tabular data classification tasks. While Gradient Boosting Decision Trees (GBDT) models have proven highly effective for such tasks, their performance can be compromised when dealing with imbalanced datasets. This paper presents the first comprehensive study on adapting class-balanced loss functions to three GBDT algorithms across various tabular classification tasks, including binary, multi-class, and multi-label classification. We conduct extensive experiments on multiple datasets to evaluate the impact of class-balanced losses on different GBDT models, establishing a valuable benchmark. Our results demonstrate the potential of class-balanced loss functions to enhance GBDT performance on imbalanced datasets, offering a robust approach for practitioners facing class imbalance challenges in real-world applications. Additionally, we introduce a Python package that facilitates the integration of class-balanced loss functions into GBDT workflows, making these advanced techniques accessible to a wider audience.
Gradient-flow adaptive importance sampling for Bayesian leave one out cross-validation for sigmoidal classification models
Feb 13, 2024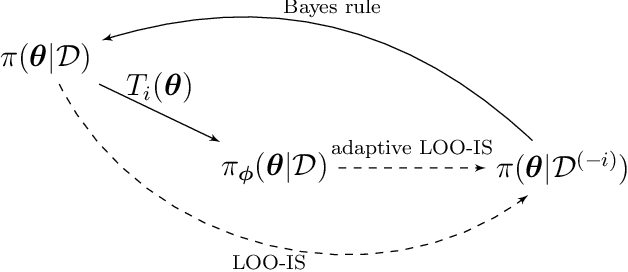
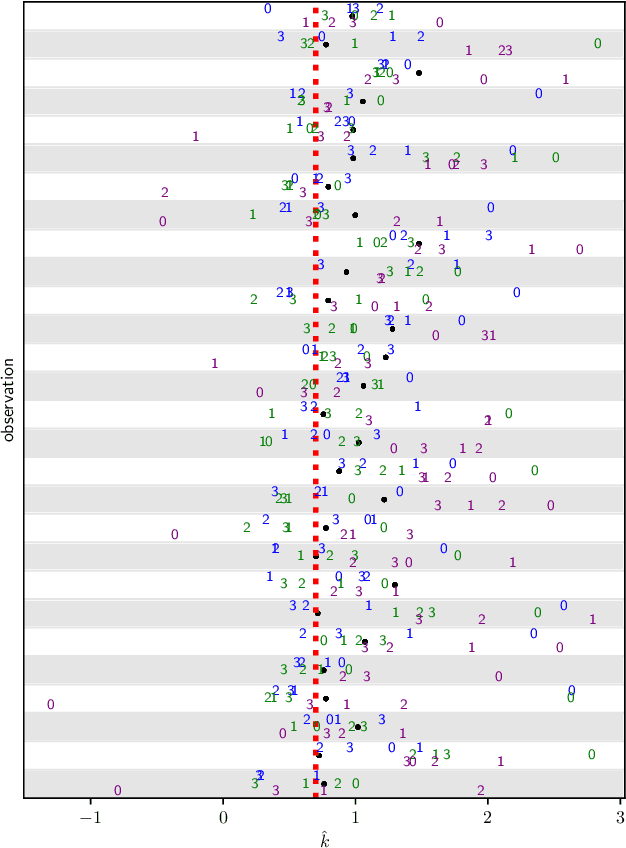
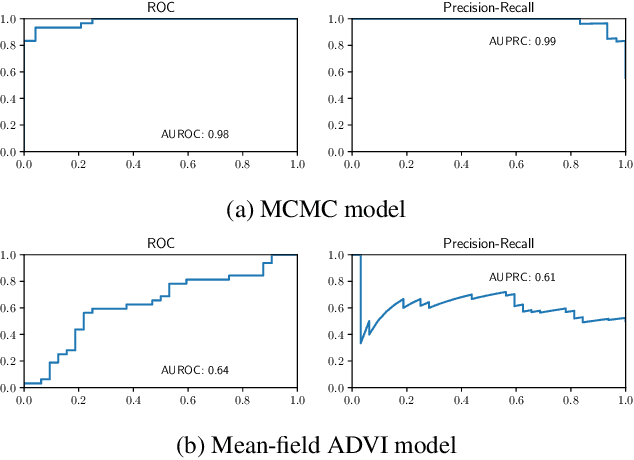
We introduce a set of gradient-flow-guided adaptive importance sampling (IS) transformations to stabilize Monte-Carlo approximations of point-wise leave one out cross-validated (LOO) predictions for Bayesian classification models. One can leverage this methodology for assessing model generalizability by for instance computing a LOO analogue to the AIC or computing LOO ROC/PRC curves and derived metrics like the AUROC and AUPRC. By the calculus of variations and gradient flow, we derive two simple nonlinear single-step transformations that utilize gradient information to shift a model's pre-trained full-data posterior closer to the target LOO posterior predictive distributions. In doing so, the transformations stabilize importance weights. Because the transformations involve the gradient of the likelihood function, the resulting Monte Carlo integral depends on Jacobian determinants with respect to the model Hessian. We derive closed-form exact formulae for these Jacobian determinants in the cases of logistic regression and shallow ReLU-activated artificial neural networks, and provide a simple approximation that sidesteps the need to compute full Hessian matrices and their spectra. We test the methodology on an $n\ll p$ dataset that is known to produce unstable LOO IS weights.
Robust-GBDT: A Novel Gradient Boosting Model for Noise-Robust Classification
Oct 08, 2023



Robust boosting algorithms have emerged as alternative solutions to traditional boosting techniques for addressing label noise in classification tasks. However, these methods have predominantly focused on binary classification, limiting their applicability to multi-class tasks. Furthermore, they encounter challenges with imbalanced datasets, missing values, and computational efficiency. In this paper, we establish that the loss function employed in advanced Gradient Boosting Decision Trees (GBDT), particularly Newton's method-based GBDT, need not necessarily exhibit global convexity. Instead, the loss function only requires convexity within a specific region. Consequently, these GBDT models can leverage the benefits of nonconvex robust loss functions, making them resilient to noise. Building upon this theoretical insight, we introduce a new noise-robust boosting model called Robust-GBDT, which seamlessly integrates the advanced GBDT framework with robust losses. Additionally, we enhance the existing robust loss functions and introduce a novel robust loss function, Robust Focal Loss, designed to address class imbalance. As a result, Robust-GBDT generates more accurate predictions, significantly enhancing its generalization capabilities, especially in scenarios marked by label noise and class imbalance. Furthermore, Robust-GBDT is user-friendly and can easily integrate existing open-source code, enabling it to effectively handle complex datasets while improving computational efficiency. Numerous experiments confirm the superiority of Robust-GBDT over other noise-robust methods.
NCART: Neural Classification and Regression Tree for Tabular Data
Jul 23, 2023



Deep learning models have become popular in the analysis of tabular data, as they address the limitations of decision trees and enable valuable applications like semi-supervised learning, online learning, and transfer learning. However, these deep-learning approaches often encounter a trade-off. On one hand, they can be computationally expensive when dealing with large-scale or high-dimensional datasets. On the other hand, they may lack interpretability and may not be suitable for small-scale datasets. In this study, we propose a novel interpretable neural network called Neural Classification and Regression Tree (NCART) to overcome these challenges. NCART is a modified version of Residual Networks that replaces fully-connected layers with multiple differentiable oblivious decision trees. By integrating decision trees into the architecture, NCART maintains its interpretability while benefiting from the end-to-end capabilities of neural networks. The simplicity of the NCART architecture makes it well-suited for datasets of varying sizes and reduces computational costs compared to state-of-the-art deep learning models. Extensive numerical experiments demonstrate the superior performance of NCART compared to existing deep learning models, establishing it as a strong competitor to tree-based models.