 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOPF: An Online Framework for Deployment-Stable Counterfactual Fairness in Evolving Graphs
May 30, 2026Online link recommendation on evolving graphs is performative: by choosing which candidate links to show users, the system changes which links form and what feedback it later observes. Consequently, fairness estimates from logged outcomes can be misleading and may drift after deployment when the recommendation policy is updated. We introduce COPF (Counterfactual Online Performative Fairness), a decision-layer framework for deployment-stable fairness monitoring and control in online link recommendation. COPF (i) defines group-level opportunity gaps over exposure (shown vs. not shown) counterfactuals, (ii) makes them estimable by explicit exploration and by logging the probability (propensity) that each candidate is shown, and (iii) audits and controls fairness using residual outcome indistinguishability (OI) over a configurable auditor family with graph-aware doubly robust (GA-DR) estimators. We provide a noisy transfer theorem showing that Residual-OI on estimated GA-DR residuals implies bounds on exposure-counterfactual group gaps under temporal mixing and bounded local interference, and we instantiate an online multicalibration auditor together with a primal-dual controller. Experiments on two TGB streams and a controlled synthetic bipartite stream show that COPF reduces worst-case spikes in exposure-counterfactual group disparities with modest impact on ranking utility. Our code is available at https://github.com/lsnnnnnnnn/COPF.
Understanding Latent Diffusability via Fisher Geometry
Apr 03, 2026Diffusion models often degrade when trained in latent spaces (e.g., VAEs), yet the formal causes remain poorly understood. We quantify latent-space diffusability through the rate of change of the Minimum Mean Squared Error (MMSE) along the diffusion trajectory. Our framework decomposes this MMSE rate into contributions from Fisher Information (FI) and Fisher Information Rate (FIR). We demonstrate that while global isometry ensures FI alignment, FIR is governed by the encoder's local geometric properties. Our analysis explicitly decouples latent geometric distortion into three measurable penalties: dimensional compression, tangential distortion, and curvature injection. We derive theoretical conditions for FIR preservation across spaces, ensuring maintained diffusability. Experiments across diverse autoencoding architectures validate our framework and establish these efficient FI and FIR metrics as a robust diagnostic suite for identifying and mitigating latent diffusion failure.
Enhancing Node-Level Graph Domain Adaptation by Alleviating Local Dependency
Dec 15, 2025Recent years have witnessed significant advancements in machine learning methods on graphs. However, transferring knowledge effectively from one graph to another remains a critical challenge. This highlights the need for algorithms capable of applying information extracted from a source graph to an unlabeled target graph, a task known as unsupervised graph domain adaptation (GDA). One key difficulty in unsupervised GDA is conditional shift, which hinders transferability. In this paper, we show that conditional shift can be observed only if there exists local dependencies among node features. To support this claim, we perform a rigorous analysis and also further provide generalization bounds of GDA when dependent node features are modeled using markov chains. Guided by the theoretical findings, we propose to improve GDA by decorrelating node features, which can be specifically implemented through decorrelated GCN layers and graph transformer layers. Our experimental results demonstrate the effectiveness of this approach, showing not only substantial performance enhancements over baseline GDA methods but also clear visualizations of small intra-class distances in the learned representations. Our code is available at https://github.com/TechnologyAiGroup/DFT
Mixing Configurations for Downstream Prediction
Oct 22, 2025Humans possess an innate ability to group objects by similarity, a cognitive mechanism that clustering algorithms aim to emulate. Recent advances in community detection have enabled the discovery of configurations -- valid hierarchical clusterings across multiple resolution scales -- without requiring labeled data. In this paper, we formally characterize these configurations and identify similar emergent structures in register tokens within Vision Transformers. Unlike register tokens, configurations exhibit lower redundancy and eliminate the need for ad hoc selection. They can be learned through unsupervised or self-supervised methods, yet their selection or composition remains specific to the downstream task and input. Building on these insights, we introduce GraMixC, a plug-and-play module that extracts configurations, aligns them using our Reverse Merge/Split (RMS) technique, and fuses them via attention heads before forwarding them to any downstream predictor. On the DSN1 16S rRNA cultivation-media prediction task, GraMixC improves the R2 score from 0.6 to 0.9 across multiple methods, setting a new state of the art. We further validate GraMixC on standard tabular benchmarks, where it consistently outperforms single-resolution and static-feature baselines.
Brain-Inspired Perspective on Configurations: Unsupervised Similarity and Early Cognition
Oct 22, 2025Infants discover categories, detect novelty, and adapt to new contexts without supervision -- a challenge for current machine learning. We present a brain-inspired perspective on configurations, a finite-resolution clustering framework that uses a single resolution parameter and attraction-repulsion dynamics to yield hierarchical organization, novelty sensitivity, and flexible adaptation. To evaluate these properties, we introduce mheatmap, which provides proportional heatmaps and a reassignment algorithm to fairly assess multi-resolution and dynamic behavior. Across datasets, configurations are competitive on standard clustering metrics, achieve 87% AUC in novelty detection, and show 35% better stability during dynamic category evolution. These results position configurations as a principled computational model of early cognitive categorization and a step toward brain-inspired AI.
Stein Discrepancy for Unsupervised Domain Adaptation
Feb 05, 2025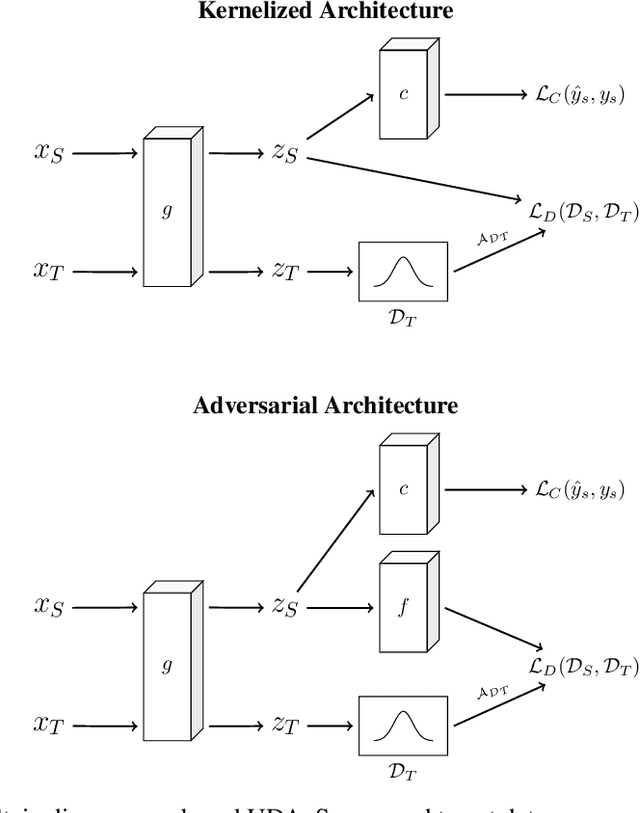
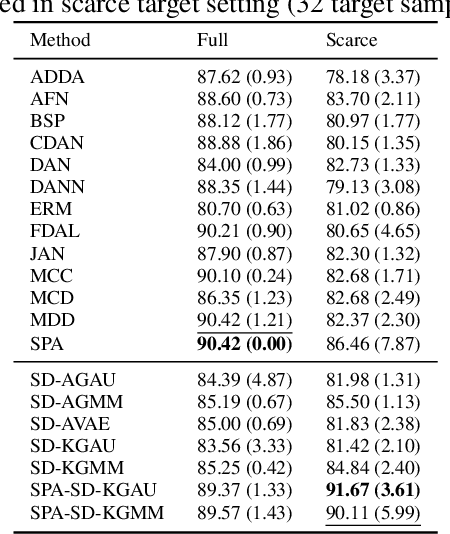
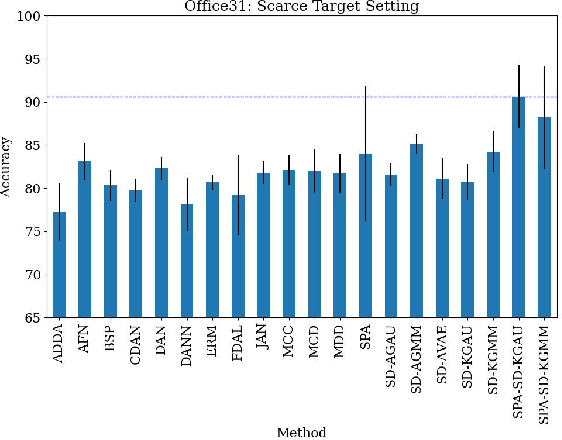
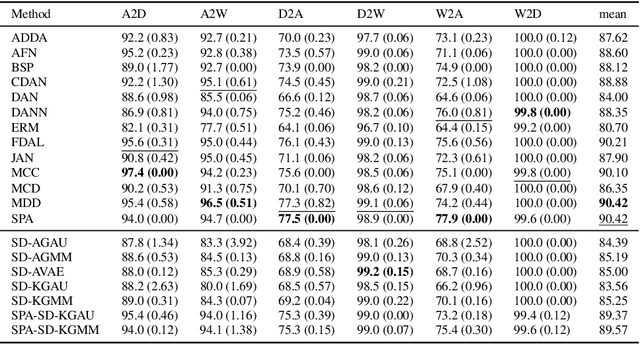
Unsupervised domain adaptation (UDA) leverages information from a labeled source dataset to improve accuracy on a related but unlabeled target dataset. A common approach to UDA is aligning representations from the source and target domains by minimizing the distance between their data distributions. Previous methods have employed distances such as Wasserstein distance and maximum mean discrepancy. However, these approaches are less effective when the target data is significantly scarcer than the source data. Stein discrepancy is an asymmetric distance between distributions that relies on one distribution only through its score function. In this paper, we propose a novel \ac{uda} method that uses Stein discrepancy to measure the distance between source and target domains. We develop a learning framework using both non-kernelized and kernelized Stein discrepancy. Theoretically, we derive an upper bound for the generalization error. Numerical experiments show that our method outperforms existing methods using other domain discrepancy measures when only small amounts of target data are available.
Klein Model for Hyperbolic Neural Networks
Oct 22, 2024Hyperbolic neural networks (HNNs) have been proved effective in modeling complex data structures. However, previous works mainly focused on the Poincar\'e ball model and the hyperboloid model as coordinate representations of the hyperbolic space, often neglecting the Klein model. Despite this, the Klein model offers its distinct advantages thanks to its straight-line geodesics, which facilitates the well-known Einstein midpoint construction, previously leveraged to accompany HNNs in other models. In this work, we introduce a framework for hyperbolic neural networks based on the Klein model. We provide detailed formulation for representing useful operations using the Klein model. We further study the Klein linear layer and prove that the "tangent space construction" of the scalar multiplication and parallel transport are exactly the Einstein scalar multiplication and the Einstein addition, analogous to the M\"obius operations used in the Poincar\'e ball model. We show numerically that the Klein HNN performs on par with the Poincar\'e ball model, providing a third option for HNN that works as a building block for more complicated architectures.
Improving Hyperbolic Representations via Gromov-Wasserstein Regularization
Jul 15, 2024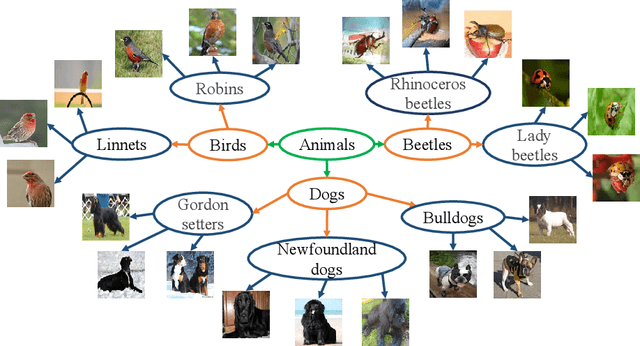
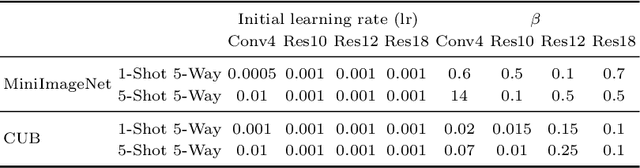
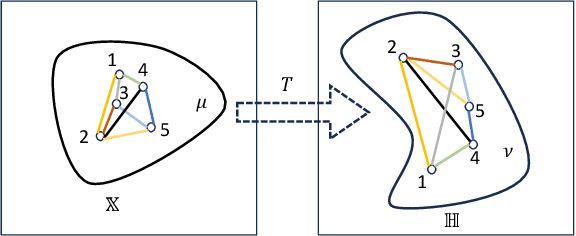
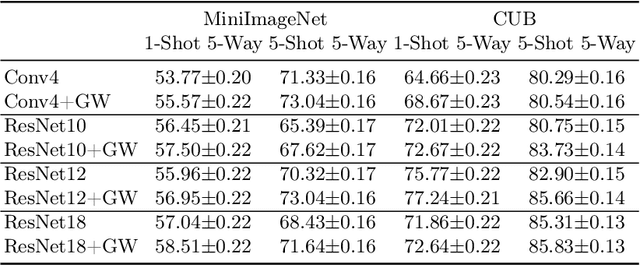
Hyperbolic representations have shown remarkable efficacy in modeling inherent hierarchies and complexities within data structures. Hyperbolic neural networks have been commonly applied for learning such representations from data, but they often fall short in preserving the geometric structures of the original feature spaces. In response to this challenge, our work applies the Gromov-Wasserstein (GW) distance as a novel regularization mechanism within hyperbolic neural networks. The GW distance quantifies how well the original data structure is maintained after embedding the data in a hyperbolic space. Specifically, we explicitly treat the layers of the hyperbolic neural networks as a transport map and calculate the GW distance accordingly. We validate that the GW distance computed based on a training set well approximates the GW distance of the underlying data distribution. Our approach demonstrates consistent enhancements over current state-of-the-art methods across various tasks, including few-shot image classification, as well as semi-supervised graph link prediction and node classification.
Three Revisits to Node-Level Graph Anomaly Detection: Outliers, Message Passing and Hyperbolic Neural Networks
Mar 06, 2024



Graph anomaly detection plays a vital role for identifying abnormal instances in complex networks. Despite advancements of methodology based on deep learning in recent years, existing benchmarking approaches exhibit limitations that hinder a comprehensive comparison. In this paper, we revisit datasets and approaches for unsupervised node-level graph anomaly detection tasks from three aspects. Firstly, we introduce outlier injection methods that create more diverse and graph-based anomalies in graph datasets. Secondly, we compare methods employing message passing against those without, uncovering the unexpected decline in performance associated with message passing. Thirdly, we explore the use of hyperbolic neural networks, specifying crucial architecture and loss design that contribute to enhanced performance. Through rigorous experiments and evaluations, our study sheds light on general strategies for improving node-level graph anomaly detection methods.
Interpretable Graph Anomaly Detection using Gradient Attention Maps
Nov 10, 2023Detecting unusual patterns in graph data is a crucial task in data mining. However, existing methods often face challenges in consistently achieving satisfactory performance and lack interpretability, which hinders our understanding of anomaly detection decisions. In this paper, we propose a novel approach to graph anomaly detection that leverages the power of interpretability to enhance performance. Specifically, our method extracts an attention map derived from gradients of graph neural networks, which serves as a basis for scoring anomalies. In addition, we conduct theoretical analysis using synthetic data to validate our method and gain insights into its decision-making process. To demonstrate the effectiveness of our method, we extensively evaluate our approach against state-of-the-art graph anomaly detection techniques. The results consistently demonstrate the superior performance of our method compared to the baselines.