 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTernaryVote: Differentially Private, Communication Efficient, and Byzantine Resilient Distributed Optimization on Heterogeneous Data
Feb 16, 2024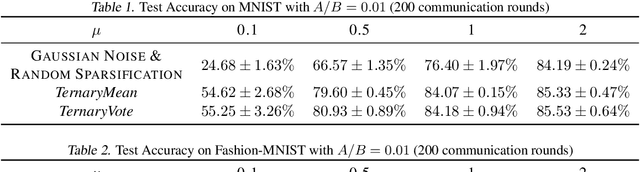
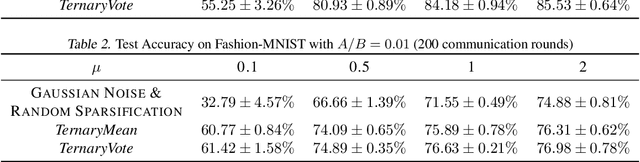

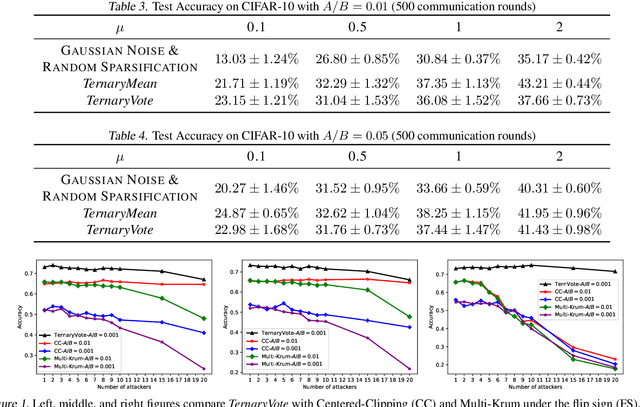
Distributed training of deep neural networks faces three critical challenges: privacy preservation, communication efficiency, and robustness to fault and adversarial behaviors. Although significant research efforts have been devoted to addressing these challenges independently, their synthesis remains less explored. In this paper, we propose TernaryVote, which combines a ternary compressor and the majority vote mechanism to realize differential privacy, gradient compression, and Byzantine resilience simultaneously. We theoretically quantify the privacy guarantee through the lens of the emerging f-differential privacy (DP) and the Byzantine resilience of the proposed algorithm. Particularly, in terms of privacy guarantees, compared to the existing sign-based approach StoSign, the proposed method improves the dimension dependence on the gradient size and enjoys privacy amplification by mini-batch sampling while ensuring a comparable convergence rate. We also prove that TernaryVote is robust when less than 50% of workers are blind attackers, which matches that of SIGNSGD with majority vote. Extensive experimental results validate the effectiveness of the proposed algorithm.
Interpretable Graph Anomaly Detection using Gradient Attention Maps
Nov 10, 2023Detecting unusual patterns in graph data is a crucial task in data mining. However, existing methods often face challenges in consistently achieving satisfactory performance and lack interpretability, which hinders our understanding of anomaly detection decisions. In this paper, we propose a novel approach to graph anomaly detection that leverages the power of interpretability to enhance performance. Specifically, our method extracts an attention map derived from gradients of graph neural networks, which serves as a basis for scoring anomalies. In addition, we conduct theoretical analysis using synthetic data to validate our method and gain insights into its decision-making process. To demonstrate the effectiveness of our method, we extensively evaluate our approach against state-of-the-art graph anomaly detection techniques. The results consistently demonstrate the superior performance of our method compared to the baselines.
Magnitude Matters: Fixing SIGNSGD Through Magnitude-Aware Sparsification in the Presence of Data Heterogeneity
Feb 19, 2023
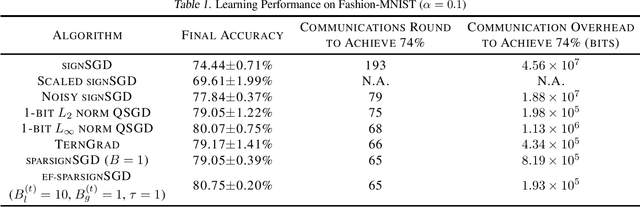

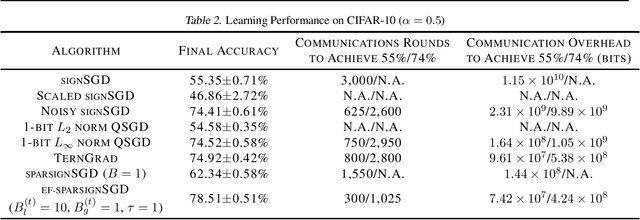
Communication overhead has become one of the major bottlenecks in the distributed training of deep neural networks. To alleviate the concern, various gradient compression methods have been proposed, and sign-based algorithms are of surging interest. However, SIGNSGD fails to converge in the presence of data heterogeneity, which is commonly observed in the emerging federated learning (FL) paradigm. Error feedback has been proposed to address the non-convergence issue. Nonetheless, it requires the workers to locally keep track of the compression errors, which renders it not suitable for FL since the workers may not participate in the training throughout the learning process. In this paper, we propose a magnitude-driven sparsification scheme, which addresses the non-convergence issue of SIGNSGD while further improving communication efficiency. Moreover, the local update scheme is further incorporated to improve the learning performance, and the convergence of the proposed method is established. The effectiveness of the proposed scheme is validated through experiments on Fashion-MNIST, CIFAR-10, and CIFAR-100 datasets.
On the Design of Communication Efficient Federated Learning over Wireless Networks
Apr 15, 2020
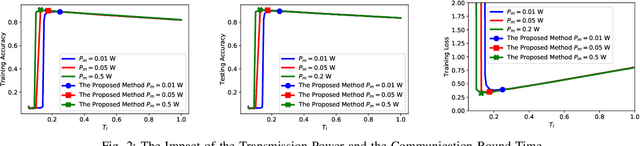
Recently, federated learning (FL), as a promising distributed machine learning approach, has attracted lots of research efforts. In FL, the parameter server and the mobile devices share the training parameters over wireless links. As a result, reducing the communication overhead becomes one of the most critical challenges. Despite that there have been various communication-efficient machine learning algorithms in literature, few of the existing works consider their implementation over wireless networks. In this work, the idea of SignSGD is adopted and only the signs of the gradients are shared between the mobile devices and the parameter server. In addition, different from most of the existing works that consider Channel State Information (CSI) at both the transmitter side and the receiver side, only receiver side CSI is assumed. In such a case, an essential problem for the mobile devices is to select appropriate local processing and communication parameters. In particular, two tradeoffs are observed under a fixed total training time: (i) given the time for each communication round, the energy consumption versus the outage probability per communication round and (ii) given the energy consumption, the number of communication rounds versus the outage probability per communication round. Two optimization problems regarding the aforementioned two tradeoffs are formulated and solved. The first problem minimizes the energy consumption given the outage probability (and therefore the learning performance) requirement while the second problem optimizes the learning performance given the energy consumption requirement. Extensive simulations are performed to demonstrate the effectiveness of the proposed method.
Stochastic-Sign SGD for Federated Learning with Theoretical Guarantees
Feb 25, 2020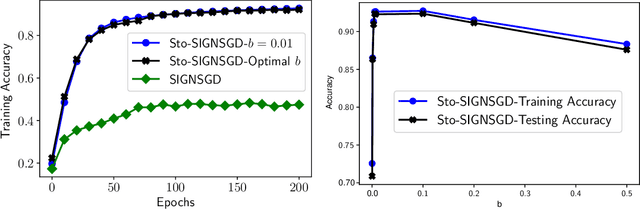
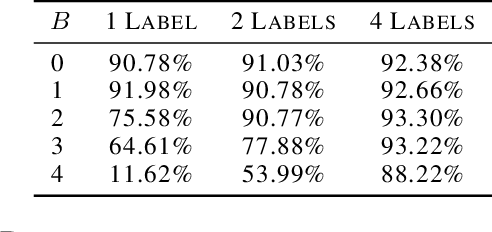

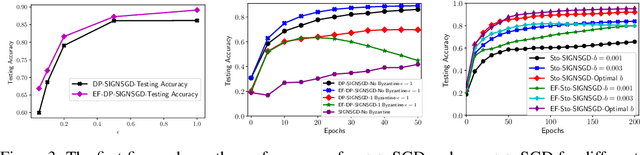
Federated learning (FL) has emerged as a prominent distributed learning paradigm. FL entails some pressing needs for developing novel parameter estimation approaches with theoretical guarantees of convergence, which are also communication efficient, differentially private and Byzantine resilient in the heterogeneous data distribution settings. Quantization-based SGD solvers have been widely adopted in FL and the recently proposed SIGNSGD with majority vote shows a promising direction. However, no existing methods enjoy all the aforementioned properties. In this paper, we propose an intuitively-simple yet theoretically-sound method based on SIGNSGD to bridge the gap. We present Stochastic-Sign SGD which utilizes novel stochastic-sign based gradient compressors enabling the aforementioned properties in a unified framework. We also present an error-feedback variant of the proposed Stochastic-Sign SGD which further improves the learning performance in FL. We test the proposed method with extensive experiments using deep neural networks on the MNIST dataset. The experimental results corroborate the effectiveness of the proposed method.
Distributed Byzantine Tolerant Stochastic Gradient Descent in the Era of Big Data
Mar 06, 2019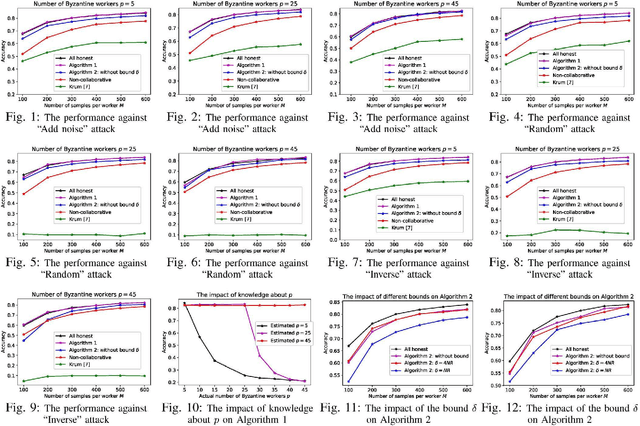
The recent advances in sensor technologies and smart devices enable the collaborative collection of a sheer volume of data from multiple information sources. As a promising tool to efficiently extract useful information from such big data, machine learning has been pushed to the forefront and seen great success in a wide range of relevant areas such as computer vision, health care, and financial market analysis. To accommodate the large volume of data, there is a surge of interest in the design of distributed machine learning, among which stochastic gradient descent (SGD) is one of the mostly adopted methods. Nonetheless, distributed machine learning methods may be vulnerable to Byzantine attack, in which the adversary can deliberately share falsified information to disrupt the intended machine learning procedures. Therefore, two asynchronous Byzantine tolerant SGD algorithms are proposed in this work, in which the honest collaborative workers are assumed to store the model parameters derived from their own local data and use them as the ground truth. The proposed algorithms can deal with an arbitrary number of Byzantine attackers and are provably convergent. Simulation results based on a real-world dataset are presented to verify the theoretical results and demonstrate the effectiveness of the proposed algorithms.
Decentralized Differentially Private Without-Replacement Stochastic Gradient Descent
Sep 12, 2018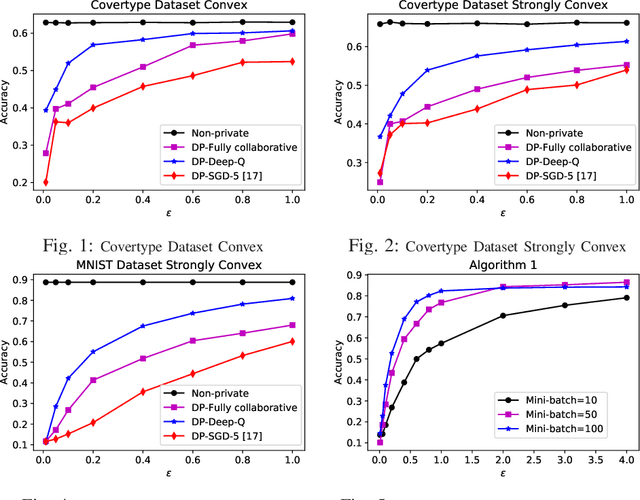


While machine learning has achieved remarkable results in a wide variety of domains, the training of models often requires large datasets that may need to be collected from different individuals. As sensitive information may be contained in the individual's dataset, sharing training data may lead to severe privacy concerns. Therefore, there is a compelling need to develop privacy-aware machine learning methods, for which one effective approach is to leverage the generic framework of differential privacy. Considering that stochastic gradient descent (SGD) is one of the mostly adopted methods for large-scale machine learning problems, two decentralized differentially private SGD algorithms are proposed in this work. Particularly, we focus on SGD without replacement due to its favorable structure for practical implementation. In addition, both privacy and convergence analysis are provided for the proposed algorithms. Finally, extensive experiments are performed to verify the theoretical results and demonstrate the effectiveness of the proposed algorithms.