 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByzantine Outside, Curious Inside: Reconstructing Data Through Malicious Updates
Jun 13, 2025Federated learning (FL) enables decentralized machine learning without sharing raw data, allowing multiple clients to collaboratively learn a global model. However, studies reveal that privacy leakage is possible under commonly adopted FL protocols. In particular, a server with access to client gradients can synthesize data resembling the clients' training data. In this paper, we introduce a novel threat model in FL, named the maliciously curious client, where a client manipulates its own gradients with the goal of inferring private data from peers. This attacker uniquely exploits the strength of a Byzantine adversary, traditionally aimed at undermining model robustness, and repurposes it to facilitate data reconstruction attack. We begin by formally defining this novel client-side threat model and providing a theoretical analysis that demonstrates its ability to achieve significant reconstruction success during FL training. To demonstrate its practical impact, we further develop a reconstruction algorithm that combines gradient inversion with malicious update strategies. Our analysis and experimental results reveal a critical blind spot in FL defenses: both server-side robust aggregation and client-side privacy mechanisms may fail against our proposed attack. Surprisingly, standard server- and client-side defenses designed to enhance robustness or privacy may unintentionally amplify data leakage. Compared to the baseline approach, a mistakenly used defense may instead improve the reconstructed image quality by 10-15%.
Federated Learning Nodes Can Reconstruct Peers' Image Data
Oct 07, 2024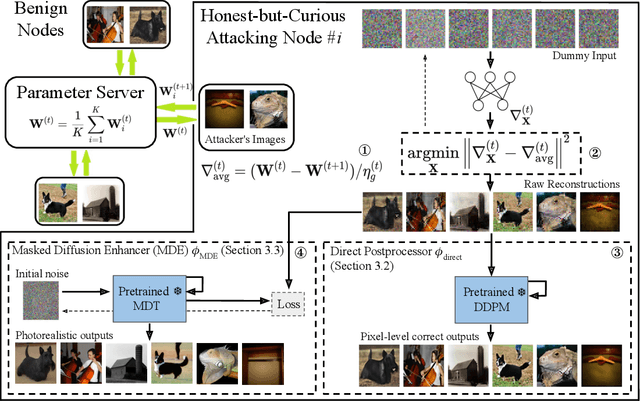


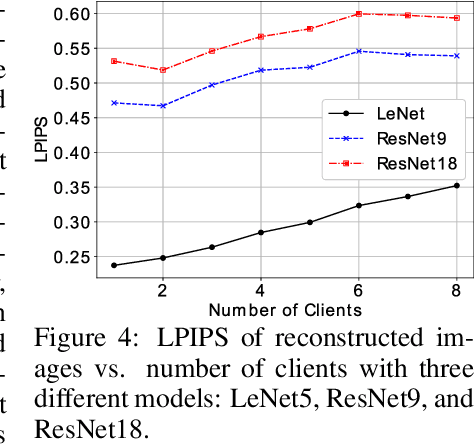
Federated learning (FL) is a privacy-preserving machine learning framework that enables multiple nodes to train models on their local data and periodically average weight updates to benefit from other nodes' training. Each node's goal is to collaborate with other nodes to improve the model's performance while keeping its training data private. However, this framework does not guarantee data privacy. Prior work has shown that the gradient-sharing steps in FL can be vulnerable to data reconstruction attacks from an honest-but-curious central server. In this work, we show that an honest-but-curious node/client can also launch attacks to reconstruct peers' image data in a centralized system, presenting a severe privacy risk. We demonstrate that a single client can silently reconstruct other clients' private images using diluted information available within consecutive updates. We leverage state-of-the-art diffusion models to enhance the perceptual quality and recognizability of the reconstructed images, further demonstrating the risk of information leakage at a semantic level. This highlights the need for more robust privacy-preserving mechanisms that protect against silent client-side attacks during federated training.
NTK-DFL: Enhancing Decentralized Federated Learning in Heterogeneous Settings via Neural Tangent Kernel
Oct 02, 2024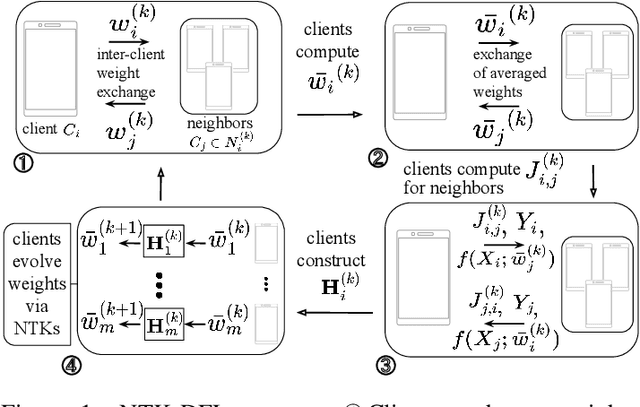
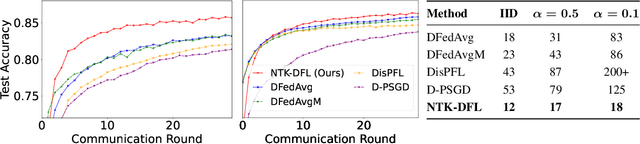
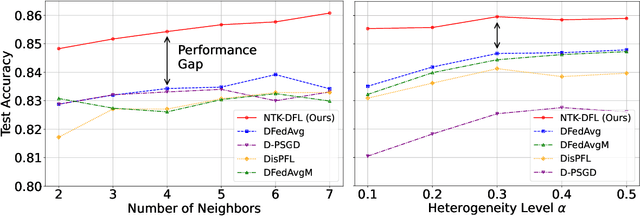
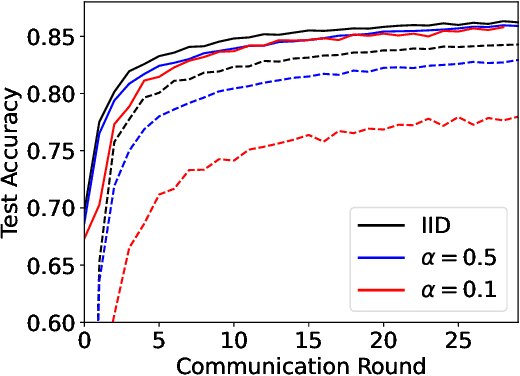
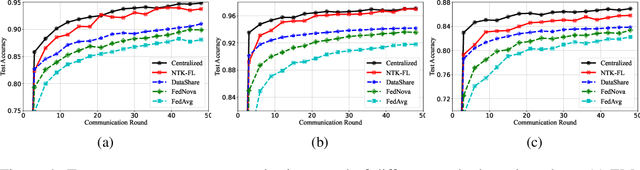
Decentralized federated learning (DFL) is a collaborative machine learning framework for training a model across participants without a central server or raw data exchange. DFL faces challenges due to statistical heterogeneity, as participants often possess different data distributions reflecting local environments and user behaviors. Recent work has shown that the neural tangent kernel (NTK) approach, when applied to federated learning in a centralized framework, can lead to improved performance. The NTK-based update mechanism is more expressive than typical gradient descent methods, enabling more efficient convergence and better handling of data heterogeneity. We propose an approach leveraging the NTK to train client models in the decentralized setting, while introducing a synergy between NTK-based evolution and model averaging. This synergy exploits inter-model variance and improves both accuracy and convergence in heterogeneous settings. Our model averaging technique significantly enhances performance, boosting accuracy by at least 10% compared to the mean local model accuracy. Empirical results demonstrate that our approach consistently achieves higher accuracy than baselines in highly heterogeneous settings, where other approaches often underperform. Additionally, it reaches target performance in 4.6 times fewer communication rounds. We validate our approach across multiple datasets, network topologies, and heterogeneity settings to ensure robustness and generalizability.
TernaryVote: Differentially Private, Communication Efficient, and Byzantine Resilient Distributed Optimization on Heterogeneous Data
Feb 16, 2024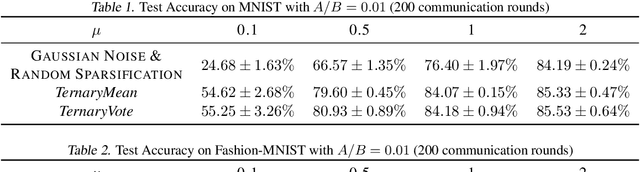
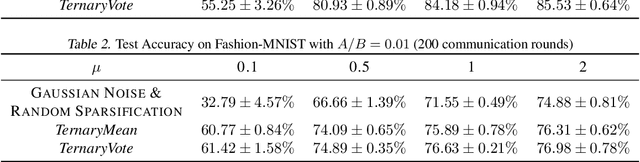

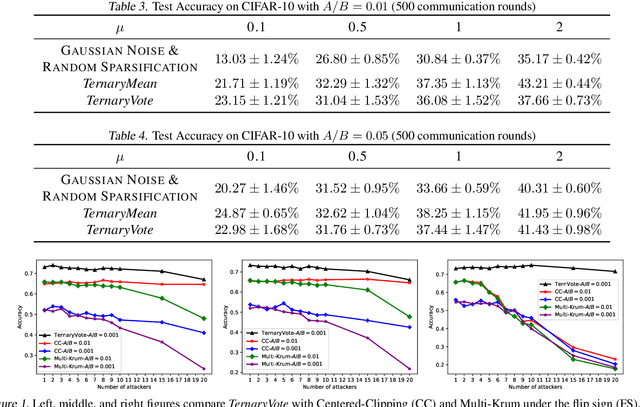
Distributed training of deep neural networks faces three critical challenges: privacy preservation, communication efficiency, and robustness to fault and adversarial behaviors. Although significant research efforts have been devoted to addressing these challenges independently, their synthesis remains less explored. In this paper, we propose TernaryVote, which combines a ternary compressor and the majority vote mechanism to realize differential privacy, gradient compression, and Byzantine resilience simultaneously. We theoretically quantify the privacy guarantee through the lens of the emerging f-differential privacy (DP) and the Byzantine resilience of the proposed algorithm. Particularly, in terms of privacy guarantees, compared to the existing sign-based approach StoSign, the proposed method improves the dimension dependence on the gradient size and enjoys privacy amplification by mini-batch sampling while ensuring a comparable convergence rate. We also prove that TernaryVote is robust when less than 50% of workers are blind attackers, which matches that of SIGNSGD with majority vote. Extensive experimental results validate the effectiveness of the proposed algorithm.
Gradient Obfuscation Gives a False Sense of Security in Federated Learning
Jun 08, 2022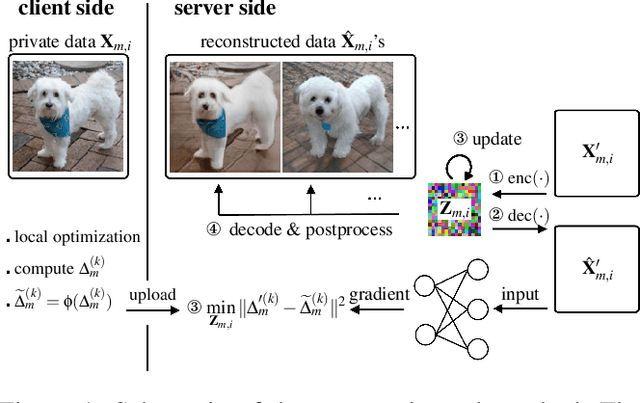


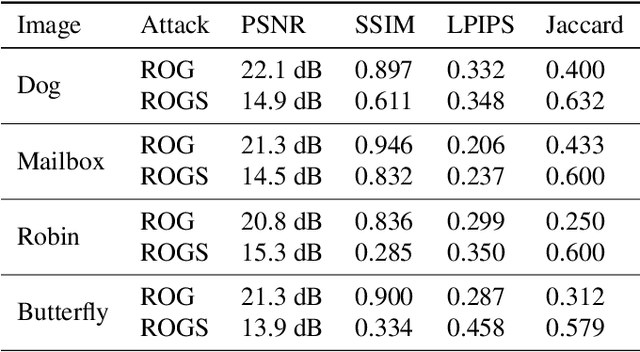
Federated learning has been proposed as a privacy-preserving machine learning framework that enables multiple clients to collaborate without sharing raw data. However, client privacy protection is not guaranteed by design in this framework. Prior work has shown that the gradient sharing strategies in federated learning can be vulnerable to data reconstruction attacks. In practice, though, clients may not transmit raw gradients considering the high communication cost or due to privacy enhancement requirements. Empirical studies have demonstrated that gradient obfuscation, including intentional obfuscation via gradient noise injection and unintentional obfuscation via gradient compression, can provide more privacy protection against reconstruction attacks. In this work, we present a new data reconstruction attack framework targeting the image classification task in federated learning. We show that commonly adopted gradient postprocessing procedures, such as gradient quantization, gradient sparsification, and gradient perturbation, may give a false sense of security in federated learning. Contrary to prior studies, we argue that privacy enhancement should not be treated as a byproduct of gradient compression. Additionally, we design a new method under the proposed framework to reconstruct the image at the semantic level. We quantify the semantic privacy leakage and compare with conventional based on image similarity scores. Our comparisons challenge the image data leakage evaluation schemes in the literature. The results emphasize the importance of revisiting and redesigning the privacy protection mechanisms for client data in existing federated learning algorithms.
Neural Tangent Kernel Empowered Federated Learning
Oct 07, 2021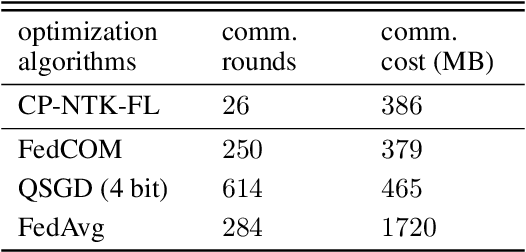
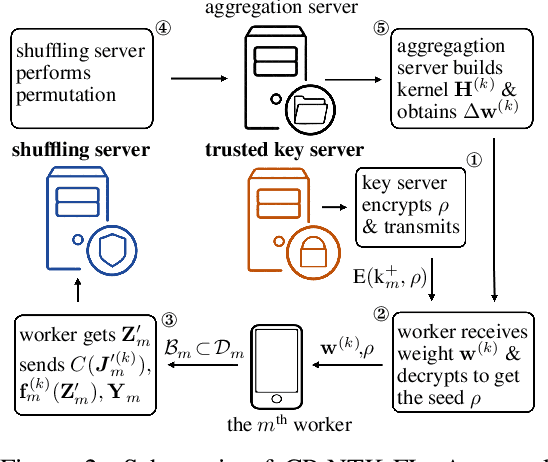

Federated learning (FL) is a privacy-preserving paradigm where multiple participants jointly solve a machine learning problem without sharing raw data. Unlike traditional distributed learning, a unique characteristic of FL is statistical heterogeneity, namely, data distributions across participants are different from each other. Meanwhile, recent advances in the interpretation of neural networks have seen a wide use of neural tangent kernel (NTK) for convergence and generalization analyses. In this paper, we propose a novel FL paradigm empowered by the NTK framework. The proposed paradigm addresses the challenge of statistical heterogeneity by transmitting update data that are more expressive than those of the traditional FL paradigms. Specifically, sample-wise Jacobian matrices, rather than model weights/gradients, are uploaded by participants. The server then constructs an empirical kernel matrix to update a global model without explicitly performing gradient descent. We further develop a variant with improved communication efficiency and enhanced privacy. Numerical results show that the proposed paradigm can achieve the same accuracy while reducing the number of communication rounds by an order of magnitude compared to federated averaging.
Federated Learning via Plurality Vote
Oct 06, 2021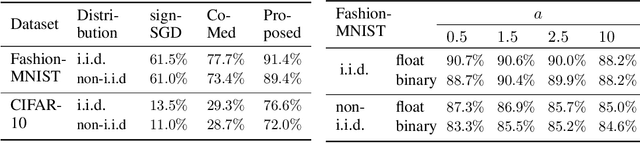
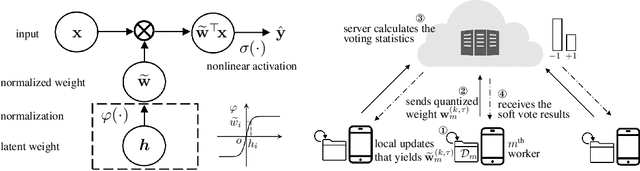


Federated learning allows collaborative workers to solve a machine learning problem while preserving data privacy. Recent studies have tackled various challenges in federated learning, but the joint optimization of communication overhead, learning reliability, and deployment efficiency is still an open problem. To this end, we propose a new scheme named federated learning via plurality vote (FedVote). In each communication round of FedVote, workers transmit binary or ternary weights to the server with low communication overhead. The model parameters are aggregated via weighted voting to enhance the resilience against Byzantine attacks. When deployed for inference, the model with binary or ternary weights is resource-friendly to edge devices. We show that our proposed method can reduce quantization error and converges faster compared with the methods directly quantizing the model updates.
Communication-Efficient Federated Learning via Predictive Coding
Aug 02, 2021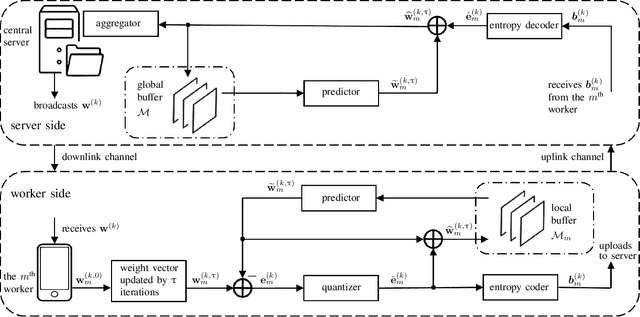
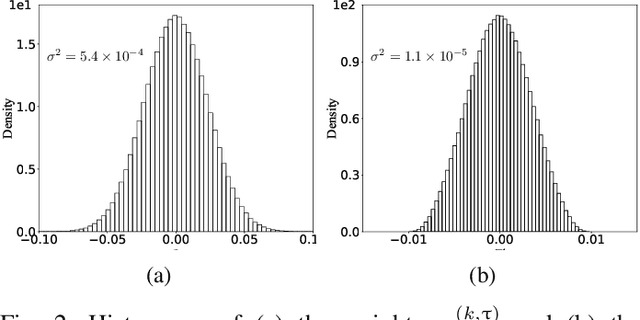
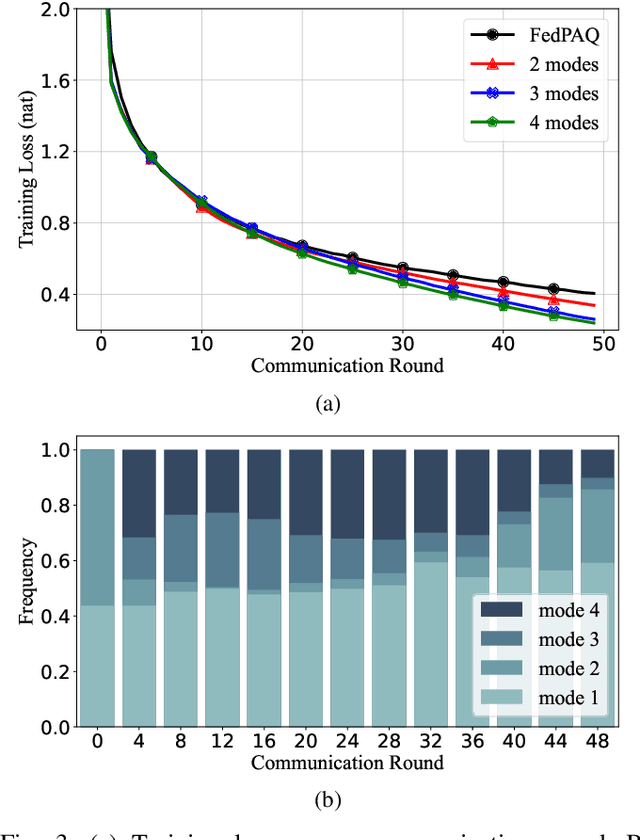
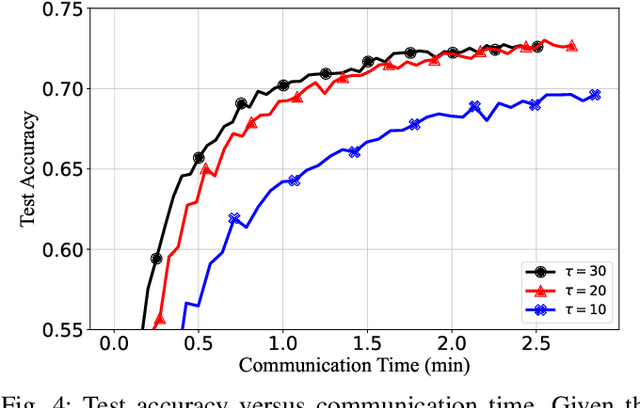
Federated learning can enable remote workers to collaboratively train a shared machine learning model while allowing training data to be kept locally. In the use case of wireless mobile devices, the communication overhead is a critical bottleneck due to limited power and bandwidth. Prior work has utilized various data compression tools such as quantization and sparsification to reduce the overhead. In this paper, we propose a predictive coding based communication scheme for federated learning. The scheme has shared prediction functions among all devices and allows each worker to transmit a compressed residual vector derived from the reference. In each communication round, we select the predictor and quantizer based on the rate-distortion cost, and further reduce the redundancy with entropy coding. Extensive simulations reveal that the communication cost can be reduced up to 99% with even better learning performance when compared with other baseline methods.
TreeSegNet: Adaptive Tree CNNs for Subdecimeter Aerial Image Segmentation
Aug 25, 2018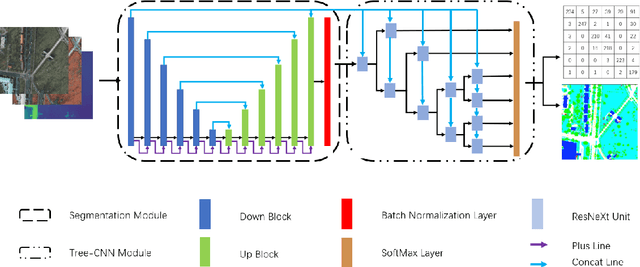

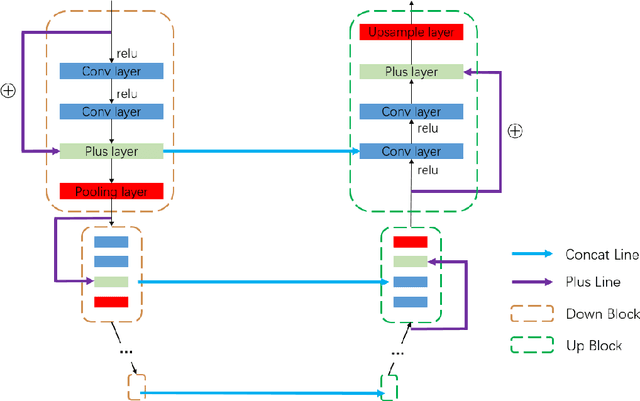
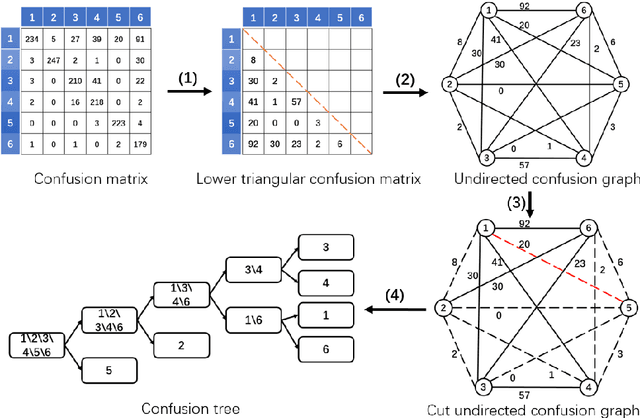
For the task of subdecimeter aerial imagery segmentation, fine-grained semantic segmentation results are usually difficult to obtain because of complex remote sensing content and optical conditions. Recently, convolutional neural networks (CNNs) have shown outstanding performance on this task. Although many deep neural network structures and techniques have been applied to improve the accuracy, few have paid attention to better differentiating the easily confused classes. In this paper, we propose TreeSegNet which adopts an adaptive network to increase the classification rate at the pixelwise level. Specifically, based on the infrastructure of DeepUNet, a Tree-CNN block in which each node represents a ResNeXt unit is constructed adaptively according to the confusion matrix and the proposed TreeCutting algorithm. By transporting feature maps through concatenating connections, the Tree-CNN block fuses multiscale features and learns best weights for the model. In experiments on the ISPRS 2D semantic labeling Potsdam dataset, the results obtained by TreeSegNet are better than those of other published state-of-the-art methods. Detailed comparison and analysis show that the improvement brought by the adaptive Tree-CNN block is significant.