 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEye Gaze as a Signal for Conveying User Attention in Contextual AI Systems
Jan 23, 2025Advanced multimodal AI agents can now collaborate with users to solve challenges in the world. We explore eye tracking's role in such interaction to convey a user's attention relative to the physical environment. We hypothesize that this knowledge improves contextual understanding for AI agents. By observing hours of human-object interactions, we first measure the relationship between an eye tracker's signal quality and its ability to reliably place gaze on nearby physical objects. We then conduct experiments which relay the user's scanpath history as additional context querying multimodal agents. Our results show that eye tracking provides high value as a user attention signal and can convey information about the user's current task and interests to the agent.
Federated Learning Nodes Can Reconstruct Peers' Image Data
Oct 07, 2024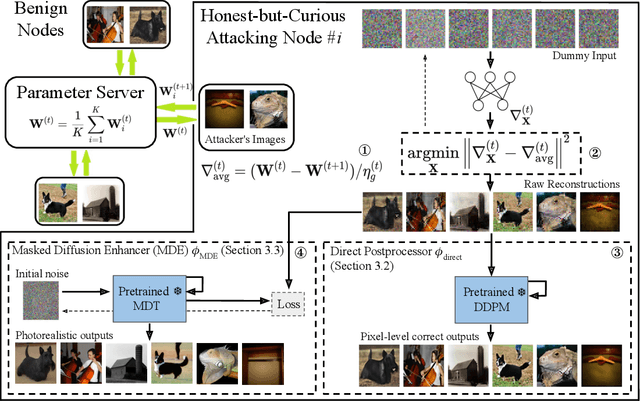


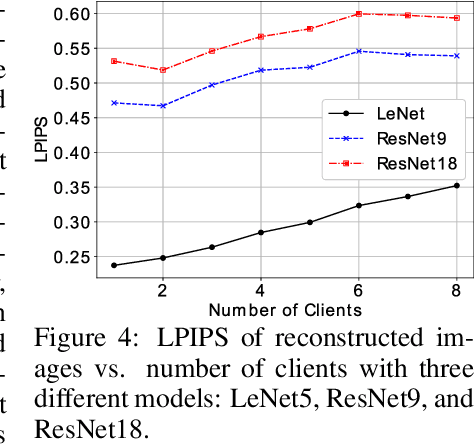
Federated learning (FL) is a privacy-preserving machine learning framework that enables multiple nodes to train models on their local data and periodically average weight updates to benefit from other nodes' training. Each node's goal is to collaborate with other nodes to improve the model's performance while keeping its training data private. However, this framework does not guarantee data privacy. Prior work has shown that the gradient-sharing steps in FL can be vulnerable to data reconstruction attacks from an honest-but-curious central server. In this work, we show that an honest-but-curious node/client can also launch attacks to reconstruct peers' image data in a centralized system, presenting a severe privacy risk. We demonstrate that a single client can silently reconstruct other clients' private images using diluted information available within consecutive updates. We leverage state-of-the-art diffusion models to enhance the perceptual quality and recognizability of the reconstructed images, further demonstrating the risk of information leakage at a semantic level. This highlights the need for more robust privacy-preserving mechanisms that protect against silent client-side attacks during federated training.
Towards mitigating uncann(eye)ness in face swaps via gaze-centric loss terms
Feb 05, 2024



Advances in face swapping have enabled the automatic generation of highly realistic faces. Yet face swaps are perceived differently than when looking at real faces, with key differences in viewer behavior surrounding the eyes. Face swapping algorithms generally place no emphasis on the eyes, relying on pixel or feature matching losses that consider the entire face to guide the training process. We further investigate viewer perception of face swaps, focusing our analysis on the presence of an uncanny valley effect. We additionally propose a novel loss equation for the training of face swapping models, leveraging a pretrained gaze estimation network to directly improve representation of the eyes. We confirm that viewed face swaps do elicit uncanny responses from viewers. Our proposed improvements significant reduce viewing angle errors between face swaps and their source material. Our method additionally reduces the prevalence of the eyes as a deciding factor when viewers perform deepfake detection tasks. Our findings have implications on face swapping for special effects, as digital avatars, as privacy mechanisms, and more; negative responses from users could limit effectiveness in said applications. Our gaze improvements are a first step towards alleviating negative viewer perceptions via a targeted approach.
Introducing Explicit Gaze Constraints to Face Swapping
May 25, 2023



Face swapping combines one face's identity with another face's non-appearance attributes (expression, head pose, lighting) to generate a synthetic face. This technology is rapidly improving, but falls flat when reconstructing some attributes, particularly gaze. Image-based loss metrics that consider the full face do not effectively capture the perceptually important, yet spatially small, eye regions. Improving gaze in face swaps can improve naturalness and realism, benefiting applications in entertainment, human computer interaction, and more. Improved gaze will also directly improve Deepfake detection efforts, serving as ideal training data for classifiers that rely on gaze for classification. We propose a novel loss function that leverages gaze prediction to inform the face swap model during training and compare against existing methods. We find all methods to significantly benefit gaze in resulting face swaps.
Practical Digital Disguises: Leveraging Face Swaps to Protect Patient Privacy
Apr 13, 2022
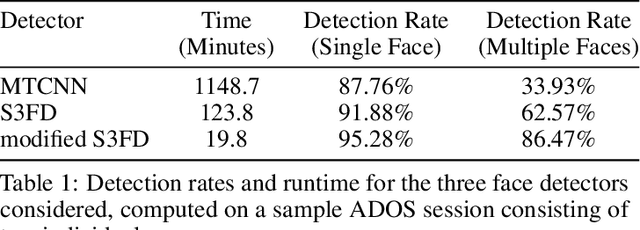
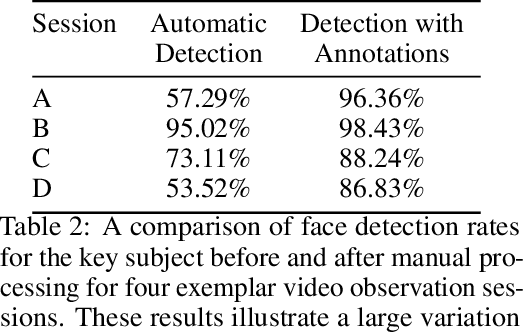
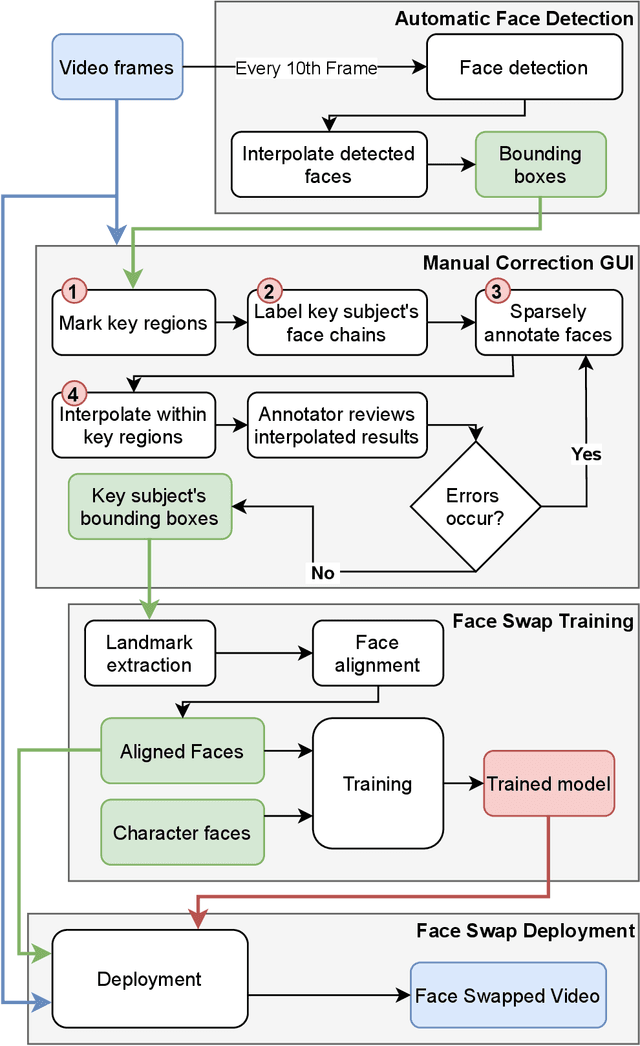
With rapid advancements in image generation technology, face swapping for privacy protection has emerged as an active area of research. The ultimate benefit is improved access to video datasets, e.g. in healthcare settings. Recent literature has proposed deep network-based architectures to perform facial swaps and reported the associated reduction in facial recognition accuracy. However, there is not much reporting on how well these methods preserve the types of semantic information needed for the privatized videos to remain useful for their intended application. Our main contribution is a novel end-to-end face swapping pipeline for recorded videos of standardized assessments of autism symptoms in children. Through this design, we are the first to provide a methodology for assessing the privacy-utility trade-offs for the face swapping approach to patient privacy protection. Our methodology can show, for example, that current deep network based face swapping is bottle-necked by face detection in real world videos, and the extent to which gaze and expression information is preserved by face swaps relative to baseline privatization methods such as blurring.