 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobility-Assisted Decentralized Federated Learning: Convergence Analysis and A Data-Driven Approach
Dec 31, 2025Decentralized Federated Learning (DFL) has emerged as a privacy-preserving machine learning paradigm that enables collaborative training among users without relying on a central server. However, its performance often degrades significantly due to limited connectivity and data heterogeneity. As we move toward the next generation of wireless networks, mobility is increasingly embedded in many real-world applications. The user mobility, either natural or induced, enables clients to act as relays or bridges, thus enhancing information flow in sparse networks; however, its impact on DFL has been largely overlooked despite its potential. In this work, we systematically investigate the role of mobility in improving DFL performance. We first establish the convergence of DFL in sparse networks under user mobility and theoretically demonstrate that even random movement of a fraction of users can significantly boost performance. Building upon this insight, we propose a DFL framework that utilizes mobile users with induced mobility patterns, allowing them to exploit the knowledge of data distribution to determine their trajectories to enhance information propagation through the network. Through extensive experiments, we empirically confirm our theoretical findings, validate the superiority of our approach over baselines, and provide a comprehensive analysis of how various network parameters influence DFL performance in mobile networks.
A Two-stage Optimization Method for Wide-range Single-electron Quantum Magnetic Sensing
Jun 16, 2025Quantum magnetic sensing based on spin systems has emerged as a new paradigm for detecting ultra-weak magnetic fields with unprecedented sensitivity, revitalizing applications in navigation, geo-localization, biology, and beyond. At the heart of quantum magnetic sensing, from the protocol perspective, lies the design of optimal sensing parameters to manifest and then estimate the underlying signals of interest (SoI). Existing studies on this front mainly rely on adaptive algorithms based on black-box AI models or formula-driven principled searches. However, when the SoI spans a wide range and the quantum sensor has physical constraints, these methods may fail to converge efficiently or optimally, resulting in prolonged interrogation times and reduced sensing accuracy. In this work, we report the design of a new protocol using a two-stage optimization method. In the 1st Stage, a Bayesian neural network with a fixed set of sensing parameters is used to narrow the range of SoI. In the 2nd Stage, a federated reinforcement learning agent is designed to fine-tune the sensing parameters within a reduced search space. The proposed protocol is developed and evaluated in a challenging context of single-shot readout of an NV-center electron spin under a constrained total sensing time budget; and yet it achieves significant improvements in both accuracy and resource efficiency for wide-range D.C. magnetic field estimation compared to the state of the art.
Byzantine Outside, Curious Inside: Reconstructing Data Through Malicious Updates
Jun 13, 2025Federated learning (FL) enables decentralized machine learning without sharing raw data, allowing multiple clients to collaboratively learn a global model. However, studies reveal that privacy leakage is possible under commonly adopted FL protocols. In particular, a server with access to client gradients can synthesize data resembling the clients' training data. In this paper, we introduce a novel threat model in FL, named the maliciously curious client, where a client manipulates its own gradients with the goal of inferring private data from peers. This attacker uniquely exploits the strength of a Byzantine adversary, traditionally aimed at undermining model robustness, and repurposes it to facilitate data reconstruction attack. We begin by formally defining this novel client-side threat model and providing a theoretical analysis that demonstrates its ability to achieve significant reconstruction success during FL training. To demonstrate its practical impact, we further develop a reconstruction algorithm that combines gradient inversion with malicious update strategies. Our analysis and experimental results reveal a critical blind spot in FL defenses: both server-side robust aggregation and client-side privacy mechanisms may fail against our proposed attack. Surprisingly, standard server- and client-side defenses designed to enhance robustness or privacy may unintentionally amplify data leakage. Compared to the baseline approach, a mistakenly used defense may instead improve the reconstructed image quality by 10-15%.
Distribution-Aware Mobility-Assisted Decentralized Federated Learning
May 24, 2025Decentralized federated learning (DFL) has attracted significant attention due to its scalability and independence from a central server. In practice, some participating clients can be mobile, yet the impact of user mobility on DFL performance remains largely unexplored, despite its potential to facilitate communication and model convergence. In this work, we demonstrate that introducing a small fraction of mobile clients, even with random movement, can significantly improve the accuracy of DFL by facilitating information flow. To further enhance performance, we propose novel distribution-aware mobility patterns, where mobile clients strategically navigate the network, leveraging knowledge of data distributions and static client locations. The proposed moving strategies mitigate the impact of data heterogeneity and boost learning convergence. Extensive experiments validate the effectiveness of induced mobility in DFL and demonstrate the superiority of our proposed mobility patterns over random movement.
GSBA$^K$: $top$-$K$ Geometric Score-based Black-box Attack
Mar 18, 2025Existing score-based adversarial attacks mainly focus on crafting $top$-1 adversarial examples against classifiers with single-label classification. Their attack success rate and query efficiency are often less than satisfactory, particularly under small perturbation requirements; moreover, the vulnerability of classifiers with multi-label learning is yet to be studied. In this paper, we propose a comprehensive surrogate free score-based attack, named \b geometric \b score-based \b black-box \b attack (GSBA$^K$), to craft adversarial examples in an aggressive $top$-$K$ setting for both untargeted and targeted attacks, where the goal is to change the $top$-$K$ predictions of the target classifier. We introduce novel gradient-based methods to find a good initial boundary point to attack. Our iterative method employs novel gradient estimation techniques, particularly effective in $top$-$K$ setting, on the decision boundary to effectively exploit the geometry of the decision boundary. Additionally, GSBA$^K$ can be used to attack against classifiers with $top$-$K$ multi-label learning. Extensive experimental results on ImageNet and PASCAL VOC datasets validate the effectiveness of GSBA$^K$ in crafting $top$-$K$ adversarial examples.
GSBAK$^K$: $top$-$K$ Geometric Score-based Black-box Attack
Mar 17, 2025Existing score-based adversarial attacks mainly focus on crafting $top$-1 adversarial examples against classifiers with single-label classification. Their attack success rate and query efficiency are often less than satisfactory, particularly under small perturbation requirements; moreover, the vulnerability of classifiers with multi-label learning is yet to be studied. In this paper, we propose a comprehensive surrogate free score-based attack, named \b geometric \b score-based \b black-box \b attack (GSBAK$^K$), to craft adversarial examples in an aggressive $top$-$K$ setting for both untargeted and targeted attacks, where the goal is to change the $top$-$K$ predictions of the target classifier. We introduce novel gradient-based methods to find a good initial boundary point to attack. Our iterative method employs novel gradient estimation techniques, particularly effective in $top$-$K$ setting, on the decision boundary to effectively exploit the geometry of the decision boundary. Additionally, GSBAK$^K$ can be used to attack against classifiers with $top$-$K$ multi-label learning. Extensive experimental results on ImageNet and PASCAL VOC datasets validate the effectiveness of GSBAK$^K$ in crafting $top$-$K$ adversarial examples.
Towards Seamless Hierarchical Federated Learning under Intermittent Client Participation: A Stagewise Decision-Making Methodology
Feb 13, 2025Federated Learning (FL) offers a pioneering distributed learning paradigm that enables devices/clients to build a shared global model. This global model is obtained through frequent model transmissions between clients and a central server, which may cause high latency, energy consumption, and congestion over backhaul links. To overcome these drawbacks, Hierarchical Federated Learning (HFL) has emerged, which organizes clients into multiple clusters and utilizes edge nodes (e.g., edge servers) for intermediate model aggregations between clients and the central server. Current research on HFL mainly focus on enhancing model accuracy, latency, and energy consumption in scenarios with a stable/fixed set of clients. However, addressing the dynamic availability of clients -- a critical aspect of real-world scenarios -- remains underexplored. This study delves into optimizing client selection and client-to-edge associations in HFL under intermittent client participation so as to minimize overall system costs (i.e., delay and energy), while achieving fast model convergence. We unveil that achieving this goal involves solving a complex NP-hard problem. To tackle this, we propose a stagewise methodology that splits the solution into two stages, referred to as Plan A and Plan B. Plan A focuses on identifying long-term clients with high chance of participation in subsequent model training rounds. Plan B serves as a backup, selecting alternative clients when long-term clients are unavailable during model training rounds. This stagewise methodology offers a fresh perspective on client selection that can enhance both HFL and conventional FL via enabling low-overhead decision-making processes. Through evaluations on MNIST and CIFAR-10 datasets, we show that our methodology outperforms existing benchmarks in terms of model accuracy and system costs.
HEART: Achieving Timely Multi-Model Training for Vehicle-Edge-Cloud-Integrated Hierarchical Federated Learning
Jan 17, 2025



The rapid growth of AI-enabled Internet of Vehicles (IoV) calls for efficient machine learning (ML) solutions that can handle high vehicular mobility and decentralized data. This has motivated the emergence of Hierarchical Federated Learning over vehicle-edge-cloud architectures (VEC-HFL). Nevertheless, one aspect which is underexplored in the literature on VEC-HFL is that vehicles often need to execute multiple ML tasks simultaneously, where this multi-model training environment introduces crucial challenges. First, improper aggregation rules can lead to model obsolescence and prolonged training times. Second, vehicular mobility may result in inefficient data utilization by preventing the vehicles from returning their models to the network edge. Third, achieving a balanced resource allocation across diverse tasks becomes of paramount importance as it majorly affects the effectiveness of collaborative training. We take one of the first steps towards addressing these challenges via proposing a framework for multi-model training in dynamic VEC-HFL with the goal of minimizing global training latency while ensuring balanced training across various tasks-a problem that turns out to be NP-hard. To facilitate timely model training, we introduce a hybrid synchronous-asynchronous aggregation rule. Building on this, we present a novel method called Hybrid Evolutionary And gReedy allocaTion (HEART). The framework operates in two stages: first, it achieves balanced task scheduling through a hybrid heuristic approach that combines improved Particle Swarm Optimization (PSO) and Genetic Algorithms (GA); second, it employs a low-complexity greedy algorithm to determine the training priority of assigned tasks on vehicles. Experiments on real-world datasets demonstrate the superiority of HEART over existing methods.
Federated Learning Nodes Can Reconstruct Peers' Image Data
Oct 07, 2024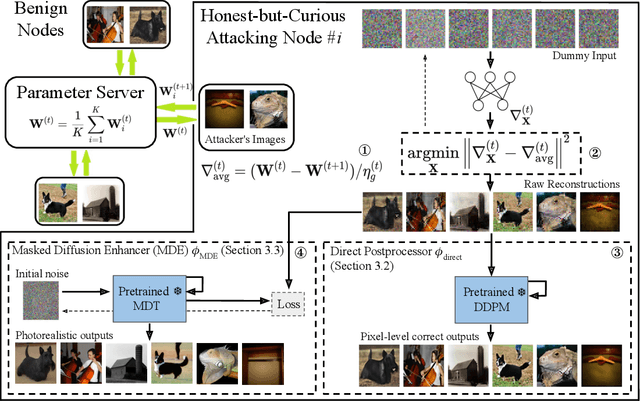


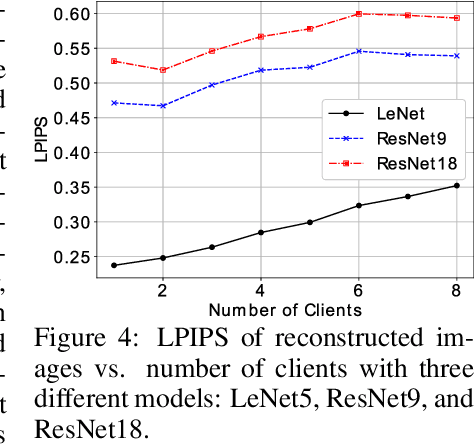
Federated learning (FL) is a privacy-preserving machine learning framework that enables multiple nodes to train models on their local data and periodically average weight updates to benefit from other nodes' training. Each node's goal is to collaborate with other nodes to improve the model's performance while keeping its training data private. However, this framework does not guarantee data privacy. Prior work has shown that the gradient-sharing steps in FL can be vulnerable to data reconstruction attacks from an honest-but-curious central server. In this work, we show that an honest-but-curious node/client can also launch attacks to reconstruct peers' image data in a centralized system, presenting a severe privacy risk. We demonstrate that a single client can silently reconstruct other clients' private images using diluted information available within consecutive updates. We leverage state-of-the-art diffusion models to enhance the perceptual quality and recognizability of the reconstructed images, further demonstrating the risk of information leakage at a semantic level. This highlights the need for more robust privacy-preserving mechanisms that protect against silent client-side attacks during federated training.
NTK-DFL: Enhancing Decentralized Federated Learning in Heterogeneous Settings via Neural Tangent Kernel
Oct 02, 2024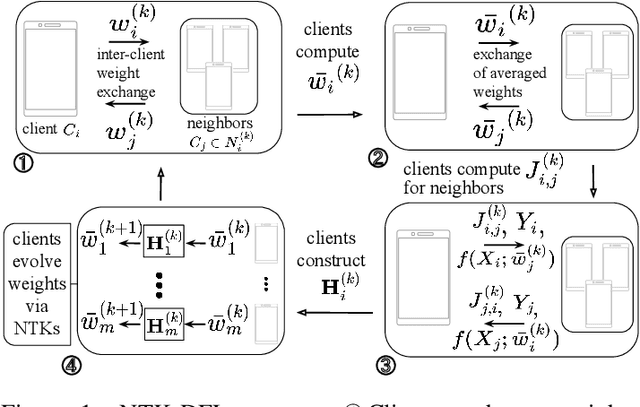
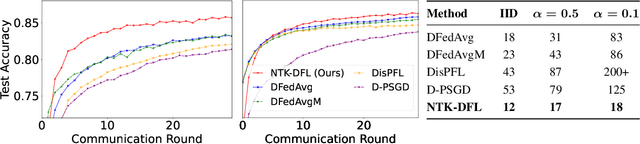
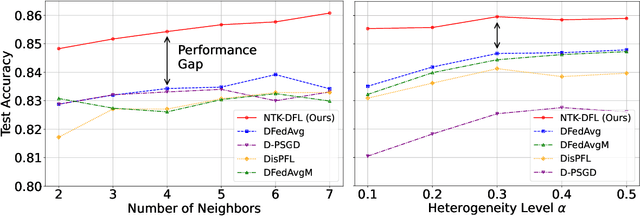
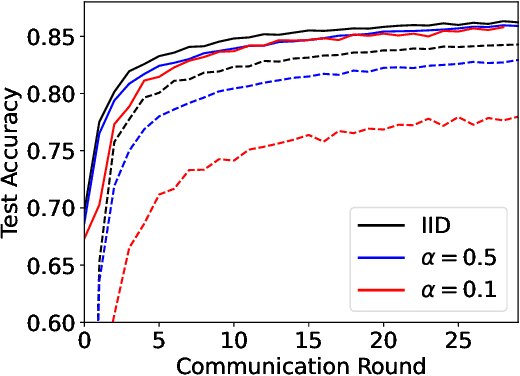
Decentralized federated learning (DFL) is a collaborative machine learning framework for training a model across participants without a central server or raw data exchange. DFL faces challenges due to statistical heterogeneity, as participants often possess different data distributions reflecting local environments and user behaviors. Recent work has shown that the neural tangent kernel (NTK) approach, when applied to federated learning in a centralized framework, can lead to improved performance. The NTK-based update mechanism is more expressive than typical gradient descent methods, enabling more efficient convergence and better handling of data heterogeneity. We propose an approach leveraging the NTK to train client models in the decentralized setting, while introducing a synergy between NTK-based evolution and model averaging. This synergy exploits inter-model variance and improves both accuracy and convergence in heterogeneous settings. Our model averaging technique significantly enhances performance, boosting accuracy by at least 10% compared to the mean local model accuracy. Empirical results demonstrate that our approach consistently achieves higher accuracy than baselines in highly heterogeneous settings, where other approaches often underperform. Additionally, it reaches target performance in 4.6 times fewer communication rounds. We validate our approach across multiple datasets, network topologies, and heterogeneity settings to ensure robustness and generalizability.