 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Spectrum Awareness for Radio Dynamic Zones Using Kriging and Matrix Completion
Mar 11, 2026Radio Dynamic Zones (RDZs) are geographically defined areas specifically allocated for testing new wireless technologies. It is essential to safeguard the regular spectrum users outside the zones from the interference caused by the deployed equipment within this zone. Previous works have utilized sparse reference signal received power (RSRP) measurements collected by unmanned aerial vehicles (UAVs) to construct a dense 3D radio map through ordinary Kriging. In this work, we illustrate that matrix completion can outperform ordinary Kriging. We partitioned a 2D area of interest into small square grids where each grid corresponds to a single entry of a matrix. The matrix completion algorithm learns the global structure of the radio environment map by leveraging the low-rank property of propagation maps. Additionally, we illustrate that the simple Kriging and trans-Gaussian Kriging yield better results when the density of known measurements is lower. Earlier works of RSRP prediction involved a training dataset at a single altitude. In this work, we also show that performance can be improved by utilizing a combined dataset from multiple altitudes.
* Published in IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), 2024
UAV-Based 3D Spectrum Sensing: Insights on Altitude, Bandwidth, Trajectory, and Effective Antenna Patterns on REM Reconstruction
Mar 11, 2026Spectrum sensing and the generation of 3D Radio Environment Maps (REMs) are essential for enabling spectrum sharing within cognitive radio networks. While Uncrewed Aerial Vehicles (UAVs) offer high-mobility 3D sensing, REM accuracy is challenged by dynamic flight behaviors, where fluctuations in UAV speed and direction introduce measurement inconsistencies. Furthermore, the structural influence of the airframe itself impacts the onboard antenna's radiation characteristics. In this paper, we present a comprehensive analysis of REM reconstruction at various altitudes, using real-world data from a fixed base station tower and a ground-vehicle source. We evaluate diverse reconstruction methodologies, including Kriging (simple, ordinary, and trans-Gaussian), matrix completion, and Gaussian process regression (GPR) for recovery from sparse samples. Our results indicate that simple Kriging and GPR remain more robust under extreme sample sparsity. We also propose a framework to enhance reconstruction accuracy in deep-shadowed regions by decomposing the REM into distinct smooth and deep-shadowed spatial components. We further investigate how REM reconstruction performance is influenced by physical and UAV-related external parameters. First, we demonstrate that the impact of UAV altitude on accuracy follows a tri-phasic trend: an initial performance gain up to $h_1$, a performance dip between $h_1$ and $h_2$, and a final stage of increasing accuracy. Additionally, we show that performance improves with increased spectrum bandwidth. Second, our analysis of UAV trajectories reveals that the variance of shadow fading exhibits a non-monotonic trend, peaking at both very low and mid-high elevation angles. Finally, we demonstrate that antenna pattern calibration from in-field measurements significantly enhances REM reconstruction accuracy by accounting for shadowing induced by the UAV airframe.
Exposing Vulnerabilities in Counterfeit Prevention Systems Utilizing Physically Unclonable Surface Features
Dec 09, 2025Counterfeit products pose significant risks to public health and safety through infiltrating untrusted supply chains. Among numerous anti-counterfeiting techniques, leveraging inherent, unclonable microscopic irregularities of paper surfaces is an accurate and cost-effective solution. Prior work of this approach has focused on enabling ubiquitous acquisition of these physically unclonable features (PUFs). However, we will show that existing authentication methods relying on paper surface PUFs may be vulnerable to adversaries, resulting in a gap between technological feasibility and secure real-world deployment. This gap is investigated through formalizing an operational framework for paper-PUF-based authentication. Informed by this framework, we reveal system-level vulnerabilities across both physical and digital domains, designing physical denial-of-service and digital forgery attacks to disrupt proper authentication. The effectiveness of the designed attacks underscores the strong need for security countermeasures for reliable and resilient authentication based on paper PUFs. The proposed framework further facilitates a comprehensive, stage-by-stage security analysis, guiding the design of future counterfeit prevention systems. This analysis delves into potential attack strategies, offering a foundational understanding of how various system components, such as physical features and verification processes, might be exploited by adversaries.
Byzantine Outside, Curious Inside: Reconstructing Data Through Malicious Updates
Jun 13, 2025Federated learning (FL) enables decentralized machine learning without sharing raw data, allowing multiple clients to collaboratively learn a global model. However, studies reveal that privacy leakage is possible under commonly adopted FL protocols. In particular, a server with access to client gradients can synthesize data resembling the clients' training data. In this paper, we introduce a novel threat model in FL, named the maliciously curious client, where a client manipulates its own gradients with the goal of inferring private data from peers. This attacker uniquely exploits the strength of a Byzantine adversary, traditionally aimed at undermining model robustness, and repurposes it to facilitate data reconstruction attack. We begin by formally defining this novel client-side threat model and providing a theoretical analysis that demonstrates its ability to achieve significant reconstruction success during FL training. To demonstrate its practical impact, we further develop a reconstruction algorithm that combines gradient inversion with malicious update strategies. Our analysis and experimental results reveal a critical blind spot in FL defenses: both server-side robust aggregation and client-side privacy mechanisms may fail against our proposed attack. Surprisingly, standard server- and client-side defenses designed to enhance robustness or privacy may unintentionally amplify data leakage. Compared to the baseline approach, a mistakenly used defense may instead improve the reconstructed image quality by 10-15%.
Collection: Datasets from AFAR Challenge
May 11, 2025



This paper presents a comprehensive real-world and Digital Twin (DT) dataset collected as part of the Find A Rover (AFAR) Challenge, organized by the NSF Aerial Experimentation and Research Platform for Advanced Wireless (AERPAW) testbed and hosted at the Lake Wheeler Field in Raleigh, North Carolina. The AFAR Challenge was a competition involving five finalist university teams, focused on promoting innovation in UAV-assisted radio frequency (RF) source localization. Participating teams were tasked with designing UAV flight trajectories and localization algorithms to detect the position of a hidden unmanned ground vehicle (UGV), also referred to as a rover, emitting wireless probe signals generated by GNU Radio. The competition was structured to evaluate solutions in a DT environment first, followed by deployment and testing in AERPAW's outdoor wireless testbed. For each team, the UGV was placed at three different positions, resulting in a total of 30 datasets, 15 collected in a DT simulation environment and 15 in a physical outdoor testbed. Each dataset contains time-synchronized measurements of received signal strength (RSS), received signal quality (RSQ), GPS coordinates, UAV velocity, and UAV orientation (roll, pitch, and yaw). Data is organized into structured folders by team, environment (DT and real-world), and UGV location. The dataset supports research in UAV-assisted RF source localization, air-to-ground (A2G) wireless propagation modeling, trajectory optimization, signal prediction, autonomous navigation, and DT validation. With approximately 300k time-synchronized samples collected from real-world experiments, the dataset provides a substantial foundation for training and evaluating deep learning (DL) models. Overall, the AFAR dataset serves as a valuable resource for advancing robust, real-world solutions in UAV-enabled wireless communications and sensing systems.
UAV-Assisted Coverage Hole Detection Using Reinforcement Learning in Urban Cellular Networks
Mar 09, 2025Deployment of cellular networks in urban areas requires addressing various challenges. For example, high-rise buildings with varying geometrical shapes and heights contribute to signal attenuation, reflection, diffraction, and scattering effects. This creates a high possibility of coverage holes (CHs) within the proximity of the buildings. Detecting these CHs is critical for network operators to ensure quality of service, as customers in such areas experience weak or no signal reception. To address this challenge, we propose an approach using an autonomous vehicle, such as an unmanned aerial vehicle (UAV), to detect CHs, for minimizing drive test efforts and reducing human labor. The UAV leverages reinforcement learning (RL) to find CHs using stored local building maps, its current location, and measured signal strengths. As the UAV moves, it dynamically updates its knowledge of the signal environment and its direction to a nearby CH while avoiding collisions with buildings. We created a wide range of testing scenarios using building maps from OpenStreetMap and signal strength data generated by NVIDIA Sionna raytracing simulations. The results demonstrate that the RL-based approach performs better than non-machine learning, geometry-based methods in detecting CHs in urban areas. Additionally, even with a limited number of UAV measurements, the method achieves performance close to theoretical upper bounds that assume complete knowledge of all signal strengths.
Surface-Based Authentication System for Integrated Circuit Chips
Dec 19, 2024The rapid development of the semiconductor industry and the ubiquity of electronic devices have led to a significant increase in the counterfeiting of integrated circuits (ICs). This poses a major threat to public health, the banking industry, and military defense sectors that are heavily reliant on electronic systems. The electronic physically unclonable functions (PUFs) are widely used to authenticate IC chips at the unit level. However, electronic PUFs are limited by their requirement for IC chips to be in working status for measurements and their sensitivity to environmental variations. This paper proposes using optical PUFs for IC chip authentication by leveraging the unique microscopic structures of the packaging surface of individual IC chips. The proposed method relies on color images of IC chip surfaces acquired using a flatbed scanner or mobile camera. Our initial study reveals that these consumer-grade imaging devices can capture meaningful physical features from IC chip surfaces. We then propose an efficient, lightweight verification scheme leveraging specular-reflection-based features extracted from videos, achieving an equal error rate (EER) of 0.0008. We conducted factor, sensitivity, and ablation studies to understand the detailed characteristics of the proposed lightweight verification scheme. This work is the first to apply the optical PUF principle for the authentication of IC chips and has the potential to significantly enhance the security of the semiconductor supply chain.
PortLLM: Personalizing Evolving Large Language Models with Training-Free and Portable Model Patches
Oct 08, 2024



As large language models (LLMs) increasingly shape the AI landscape, fine-tuning pretrained models has become more popular than in the pre-LLM era for achieving optimal performance in domain-specific tasks. However, pretrained LLMs such as ChatGPT are periodically evolved, i.e., model parameters are frequently updated), making it challenging for downstream users with limited resources to keep up with fine-tuning the newest LLMs for their domain application. Even though fine-tuning costs have nowadays been reduced thanks to the innovations of parameter-efficient fine-tuning such as LoRA, not all downstream users have adequate computing for frequent personalization. Moreover, access to fine-tuning datasets, particularly in sensitive domains such as healthcare, could be time-restrictive, making it crucial to retain the knowledge encoded in earlier fine-tuned rounds for future adaptation. In this paper, we present PortLLM, a training-free framework that (i) creates an initial lightweight model update patch to capture domain-specific knowledge, and (ii) allows a subsequent seamless plugging for the continual personalization of evolved LLM at minimal cost. Our extensive experiments cover seven representative datasets, from easier question-answering tasks {BoolQ, SST2} to harder reasoning tasks {WinoGrande, GSM8K}, and models including {Mistral-7B, Llama2, Llama3.1, and Gemma2}, validating the portability of our designed model patches and showcasing the effectiveness of our proposed framework. For instance, PortLLM achieves comparable performance to LoRA fine-tuning with reductions of up to 12.2x in GPU memory usage. Finally, we provide theoretical justifications to understand the portability of our model update patches, which offers new insights into the theoretical dimension of LLMs' personalization.
Federated Learning Nodes Can Reconstruct Peers' Image Data
Oct 07, 2024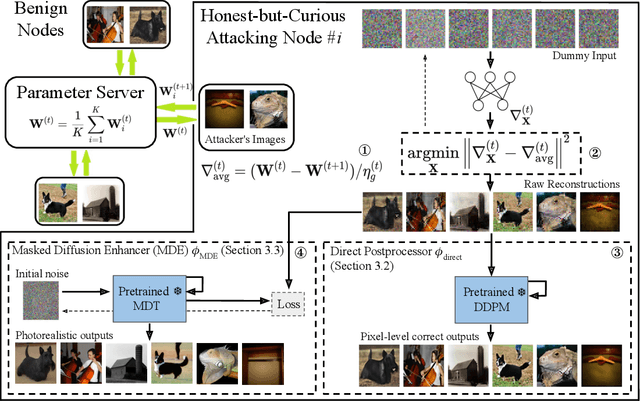


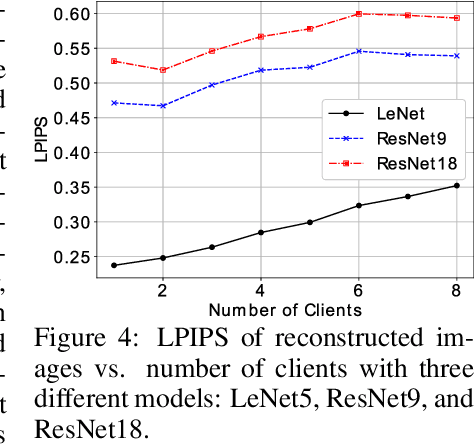
Federated learning (FL) is a privacy-preserving machine learning framework that enables multiple nodes to train models on their local data and periodically average weight updates to benefit from other nodes' training. Each node's goal is to collaborate with other nodes to improve the model's performance while keeping its training data private. However, this framework does not guarantee data privacy. Prior work has shown that the gradient-sharing steps in FL can be vulnerable to data reconstruction attacks from an honest-but-curious central server. In this work, we show that an honest-but-curious node/client can also launch attacks to reconstruct peers' image data in a centralized system, presenting a severe privacy risk. We demonstrate that a single client can silently reconstruct other clients' private images using diluted information available within consecutive updates. We leverage state-of-the-art diffusion models to enhance the perceptual quality and recognizability of the reconstructed images, further demonstrating the risk of information leakage at a semantic level. This highlights the need for more robust privacy-preserving mechanisms that protect against silent client-side attacks during federated training.
HATFormer: Historic Handwritten Arabic Text Recognition with Transformers
Oct 03, 2024



Arabic handwritten text recognition (HTR) is challenging, especially for historical texts, due to diverse writing styles and the intrinsic features of Arabic script. Additionally, Arabic handwriting datasets are smaller compared to English ones, making it difficult to train generalizable Arabic HTR models. To address these challenges, we propose HATFormer, a transformer-based encoder-decoder architecture that builds on a state-of-the-art English HTR model. By leveraging the transformer's attention mechanism, HATFormer captures spatial contextual information to address the intrinsic challenges of Arabic script through differentiating cursive characters, decomposing visual representations, and identifying diacritics. Our customization to historical handwritten Arabic includes an image processor for effective ViT information preprocessing, a text tokenizer for compact Arabic text representation, and a training pipeline that accounts for a limited amount of historic Arabic handwriting data. HATFormer achieves a character error rate (CER) of 8.6% on the largest public historical handwritten Arabic dataset, with a 51% improvement over the best baseline in the literature. HATFormer also attains a comparable CER of 4.2% on the largest private non-historical dataset. Our work demonstrates the feasibility of adapting an English HTR method to a low-resource language with complex, language-specific challenges, contributing to advancements in document digitization, information retrieval, and cultural preservation.