 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELSA: Efficient LLM-Centric Split Aggregation for Privacy-Aware Hierarchical Federated Learning over Resource-Constrained Edge Networks
Jan 20, 2026Training large language models (LLMs) at the network edge faces fundamental challenges arising from device resource constraints, severe data heterogeneity, and heightened privacy risks. To address these, we propose ELSA (Efficient LLM-centric Split Aggregation), a novel framework that systematically integrates split learning (SL) and hierarchical federated learning (HFL) for distributed LLM fine-tuning over resource-constrained edge networks. ELSA introduces three key innovations. First, it employs a task-agnostic, behavior-aware client clustering mechanism that constructs semantic fingerprints using public probe inputs and symmetric KL divergence, further enhanced by prediction-consistency-based trust scoring and latency-aware edge assignment to jointly address data heterogeneity, client unreliability, and communication constraints. Second, it splits the LLM into three parts across clients and edge servers, with the cloud used only for adapter aggregation, enabling an effective balance between on-device computation cost and global convergence stability. Third, it incorporates a lightweight communication scheme based on computational sketches combined with semantic subspace orthogonal perturbation (SS-OP) to reduce communication overhead while mitigating privacy leakage during model exchanges. Experiments across diverse NLP tasks demonstrate that ELSA consistently outperforms state-of-the-art methods in terms of adaptability, convergence behavior, and robustness, establishing a scalable and privacy-aware solution for edge-side LLM fine-tuning under resource constraints.
Game-Theoretic Safe Multi-Agent Motion Planning with Reachability Analysis for Dynamic and Uncertain Environments (Extended Version)
Nov 15, 2025Ensuring safe, robust, and scalable motion planning for multi-agent systems in dynamic and uncertain environments is a persistent challenge, driven by complex inter-agent interactions, stochastic disturbances, and model uncertainties. To overcome these challenges, particularly the computational complexity of coupled decision-making and the need for proactive safety guarantees, we propose a Reachability-Enhanced Dynamic Potential Game (RE-DPG) framework, which integrates game-theoretic coordination into reachability analysis. This approach formulates multi-agent coordination as a dynamic potential game, where the Nash equilibrium (NE) defines optimal control strategies across agents. To enable scalability and decentralized execution, we develop a Neighborhood-Dominated iterative Best Response (ND-iBR) scheme, built upon an iterated $\varepsilon$-BR (i$\varepsilon$-BR) process that guarantees finite-step convergence to an $\varepsilon$-NE. This allows agents to compute strategies based on local interactions while ensuring theoretical convergence guarantees. Furthermore, to ensure safety under uncertainty, we integrate a Multi-Agent Forward Reachable Set (MA-FRS) mechanism into the cost function, explicitly modeling uncertainty propagation and enforcing collision avoidance constraints. Through both simulations and real-world experiments in 2D and 3D environments, we validate the effectiveness of RE-DPG across diverse operational scenarios.
Hierarchical Federated Foundation Models over Wireless Networks for Multi-Modal Multi-Task Intelligence: Integration of Edge Learning with D2D/P2P-Enabled Fog Learning Architectures
Sep 03, 2025


The rise of foundation models (FMs) has reshaped the landscape of machine learning. As these models continued to grow, leveraging geo-distributed data from wireless devices has become increasingly critical, giving rise to federated foundation models (FFMs). More recently, FMs have evolved into multi-modal multi-task (M3T) FMs (e.g., GPT-4) capable of processing diverse modalities across multiple tasks, which motivates a new underexplored paradigm: M3T FFMs. In this paper, we unveil an unexplored variation of M3T FFMs by proposing hierarchical federated foundation models (HF-FMs), which in turn expose two overlooked heterogeneity dimensions to fog/edge networks that have a direct impact on these emerging models: (i) heterogeneity in collected modalities and (ii) heterogeneity in executed tasks across fog/edge nodes. HF-FMs strategically align the modular structure of M3T FMs, comprising modality encoders, prompts, mixture-of-experts (MoEs), adapters, and task heads, with the hierarchical nature of fog/edge infrastructures. Moreover, HF-FMs enable the optional usage of device-to-device (D2D) communications, enabling horizontal module relaying and localized cooperative training among nodes when feasible. Through delving into the architectural design of HF-FMs, we highlight their unique capabilities along with a series of tailored future research directions. Finally, to demonstrate their potential, we prototype HF-FMs in a wireless network setting and release the open-source code for the development of HF-FMs with the goal of fostering exploration in this untapped field (GitHub: https://github.com/payamsiabd/M3T-FFM).
Multi-Modal Multi-Task (M3T) Federated Foundation Models for Embodied AI: Potentials and Challenges for Edge Integration
May 16, 2025As embodied AI systems become increasingly multi-modal, personalized, and interactive, they must learn effectively from diverse sensory inputs, adapt continually to user preferences, and operate safely under resource and privacy constraints. These challenges expose a pressing need for machine learning models capable of swift, context-aware adaptation while balancing model generalization and personalization. Here, two methods emerge as suitable candidates, each offering parts of these capabilities: Foundation Models (FMs) provide a pathway toward generalization across tasks and modalities, whereas Federated Learning (FL) offers the infrastructure for distributed, privacy-preserving model updates and user-level model personalization. However, when used in isolation, each of these approaches falls short of meeting the complex and diverse capability requirements of real-world embodied environments. In this vision paper, we introduce Federated Foundation Models (FFMs) for embodied AI, a new paradigm that unifies the strengths of multi-modal multi-task (M3T) FMs with the privacy-preserving distributed nature of FL, enabling intelligent systems at the wireless edge. We collect critical deployment dimensions of FFMs in embodied AI ecosystems under a unified framework, which we name "EMBODY": Embodiment heterogeneity, Modality richness and imbalance, Bandwidth and compute constraints, On-device continual learning, Distributed control and autonomy, and Yielding safety, privacy, and personalization. For each, we identify concrete challenges and envision actionable research directions. We also present an evaluation framework for deploying FFMs in embodied AI systems, along with the associated trade-offs.
Adaptive UAV-Assisted Hierarchical Federated Learning: Optimizing Energy, Latency, and Resilience for Dynamic Smart IoT Networks
Mar 08, 2025



Hierarchical Federated Learning (HFL) introduces intermediate aggregation layers, addressing the limitations of conventional Federated Learning (FL) in geographically dispersed environments with limited communication infrastructure. An application of HFL is in smart IoT systems, such as remote monitoring, disaster response, and battlefield operations, where cellular connectivity is often unreliable or unavailable. In these scenarios, UAVs serve as mobile aggregators, providing connectivity to the terrestrial IoT devices. This paper studies an HFL architecture for energy-constrained UAVs in smart IoT systems, pioneering a solution to minimize global training cost increased caused by UAV disconnection. In light of this, we formulate a joint optimization problem involving learning configuration, bandwidth allocation, and device-to-UAV association, and perform global aggregation in time before UAV drops disconnect and redeployment of UAVs. The problem explicitly accounts for the dynamic nature of IoT devices and their interruptible communications and is unveiled to be NP-hard. To address this, we decompose it into three subproblems. First, we optimize the learning configuration and bandwidth allocation using an augmented Lagrangian function to reduce training costs. Second, we propose a device fitness score, integrating data heterogeneity (via Kullback-Leibler divergence), device-to-UAV distances, and IoT device resources, and develop a twin-delayed deep deterministic policy gradient (TD3)-based algorithm for dynamic device-to-UAV assignment. Third, We introduce a low-complexity two-stage greedy strategy for finding the location of UAVs redeployment and selecting the appropriate global aggregator UAV. Experiments on real-world datasets demonstrate significant cost reductions and robust performance under communication interruptions.
Privacy-Aware Joint DNN Model Deployment and Partition Optimization for Delay-Efficient Collaborative Edge Inference
Feb 22, 2025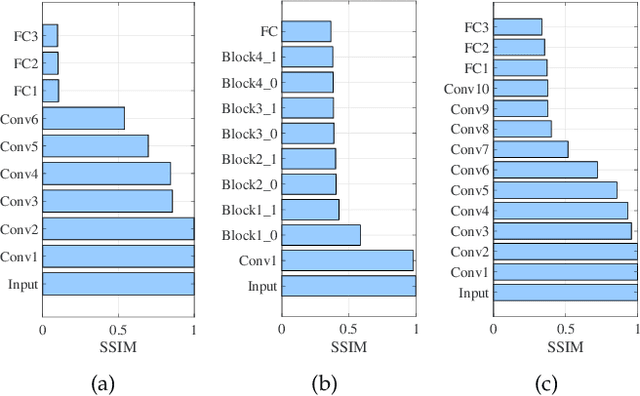
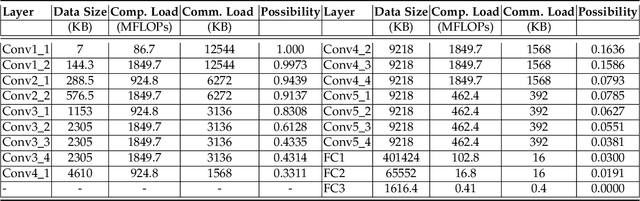

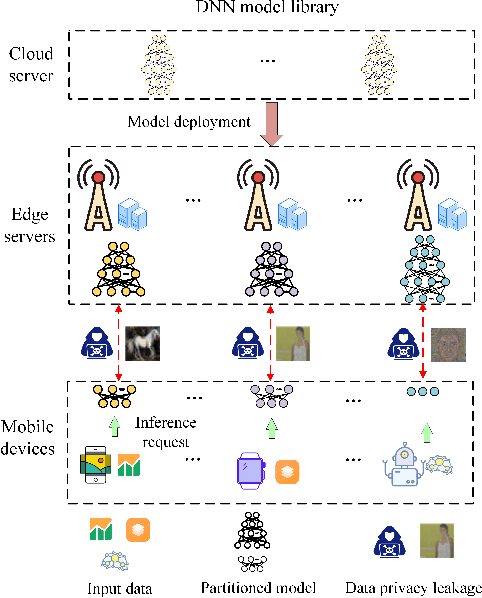
Edge inference (EI) is a key solution to address the growing challenges of delayed response times, limited scalability, and privacy concerns in cloud-based Deep Neural Network (DNN) inference. However, deploying DNN models on resource-constrained edge devices faces more severe challenges, such as model storage limitations, dynamic service requests, and privacy risks. This paper proposes a novel framework for privacy-aware joint DNN model deployment and partition optimization to minimize long-term average inference delay under resource and privacy constraints. Specifically, the problem is formulated as a complex optimization problem considering model deployment, user-server association, and model partition strategies. To handle the NP-hardness and future uncertainties, a Lyapunov-based approach is introduced to transform the long-term optimization into a single-time-slot problem, ensuring system performance. Additionally, a coalition formation game model is proposed for edge server association, and a greedy-based algorithm is developed for model deployment within each coalition to efficiently solve the problem. Extensive simulations show that the proposed algorithms effectively reduce inference delay while satisfying privacy constraints, outperforming baseline approaches in various scenarios.
Towards Seamless Hierarchical Federated Learning under Intermittent Client Participation: A Stagewise Decision-Making Methodology
Feb 13, 2025Federated Learning (FL) offers a pioneering distributed learning paradigm that enables devices/clients to build a shared global model. This global model is obtained through frequent model transmissions between clients and a central server, which may cause high latency, energy consumption, and congestion over backhaul links. To overcome these drawbacks, Hierarchical Federated Learning (HFL) has emerged, which organizes clients into multiple clusters and utilizes edge nodes (e.g., edge servers) for intermediate model aggregations between clients and the central server. Current research on HFL mainly focus on enhancing model accuracy, latency, and energy consumption in scenarios with a stable/fixed set of clients. However, addressing the dynamic availability of clients -- a critical aspect of real-world scenarios -- remains underexplored. This study delves into optimizing client selection and client-to-edge associations in HFL under intermittent client participation so as to minimize overall system costs (i.e., delay and energy), while achieving fast model convergence. We unveil that achieving this goal involves solving a complex NP-hard problem. To tackle this, we propose a stagewise methodology that splits the solution into two stages, referred to as Plan A and Plan B. Plan A focuses on identifying long-term clients with high chance of participation in subsequent model training rounds. Plan B serves as a backup, selecting alternative clients when long-term clients are unavailable during model training rounds. This stagewise methodology offers a fresh perspective on client selection that can enhance both HFL and conventional FL via enabling low-overhead decision-making processes. Through evaluations on MNIST and CIFAR-10 datasets, we show that our methodology outperforms existing benchmarks in terms of model accuracy and system costs.
HEART: Achieving Timely Multi-Model Training for Vehicle-Edge-Cloud-Integrated Hierarchical Federated Learning
Jan 17, 2025



The rapid growth of AI-enabled Internet of Vehicles (IoV) calls for efficient machine learning (ML) solutions that can handle high vehicular mobility and decentralized data. This has motivated the emergence of Hierarchical Federated Learning over vehicle-edge-cloud architectures (VEC-HFL). Nevertheless, one aspect which is underexplored in the literature on VEC-HFL is that vehicles often need to execute multiple ML tasks simultaneously, where this multi-model training environment introduces crucial challenges. First, improper aggregation rules can lead to model obsolescence and prolonged training times. Second, vehicular mobility may result in inefficient data utilization by preventing the vehicles from returning their models to the network edge. Third, achieving a balanced resource allocation across diverse tasks becomes of paramount importance as it majorly affects the effectiveness of collaborative training. We take one of the first steps towards addressing these challenges via proposing a framework for multi-model training in dynamic VEC-HFL with the goal of minimizing global training latency while ensuring balanced training across various tasks-a problem that turns out to be NP-hard. To facilitate timely model training, we introduce a hybrid synchronous-asynchronous aggregation rule. Building on this, we present a novel method called Hybrid Evolutionary And gReedy allocaTion (HEART). The framework operates in two stages: first, it achieves balanced task scheduling through a hybrid heuristic approach that combines improved Particle Swarm Optimization (PSO) and Genetic Algorithms (GA); second, it employs a low-complexity greedy algorithm to determine the training priority of assigned tasks on vehicles. Experiments on real-world datasets demonstrate the superiority of HEART over existing methods.
Learning-Based Client Selection for Federated Learning Services Over Wireless Networks with Constrained Monetary Budgets
Aug 08, 2022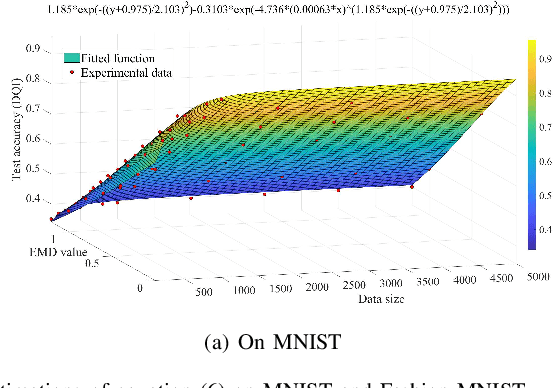
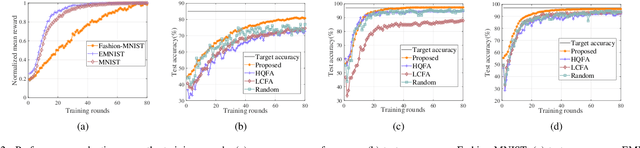
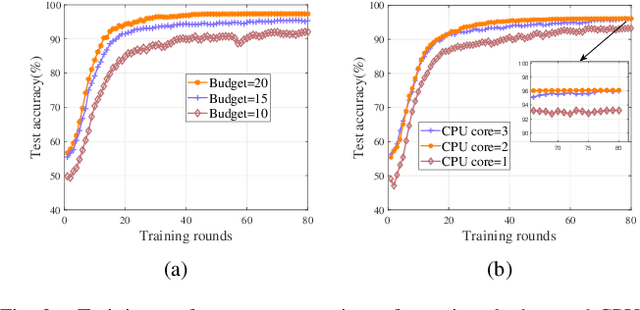
We investigate a data quality-aware dynamic client selection problem for multiple federated learning (FL) services in a wireless network, where each client has dynamic datasets for the simultaneous training of multiple FL services and each FL service demander has to pay for the clients with constrained monetary budgets. The problem is formalized as a non-cooperative Markov game over the training rounds. A multi-agent hybrid deep reinforcement learning-based algorithm is proposed to optimize the joint client selection and payment actions, while avoiding action conflicts. Simulation results indicate that our proposed algorithm can significantly improve the training performance.
Hybrid Architectures for Distributed Machine Learning in Heterogeneous Wireless Networks
Jun 04, 2022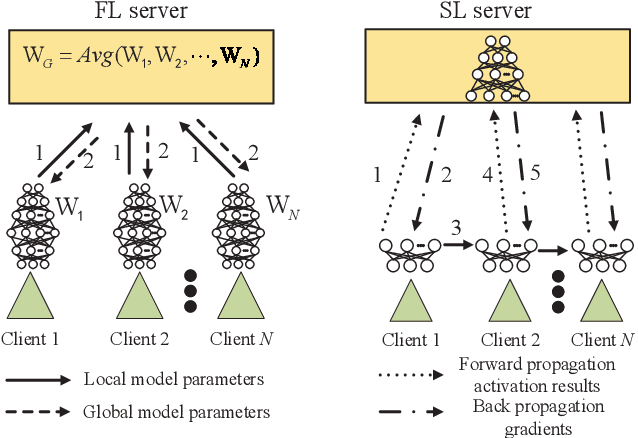
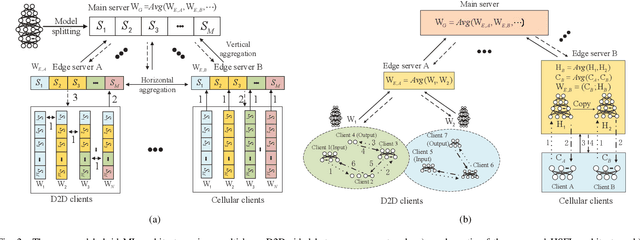
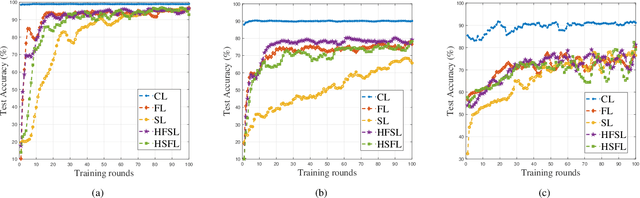
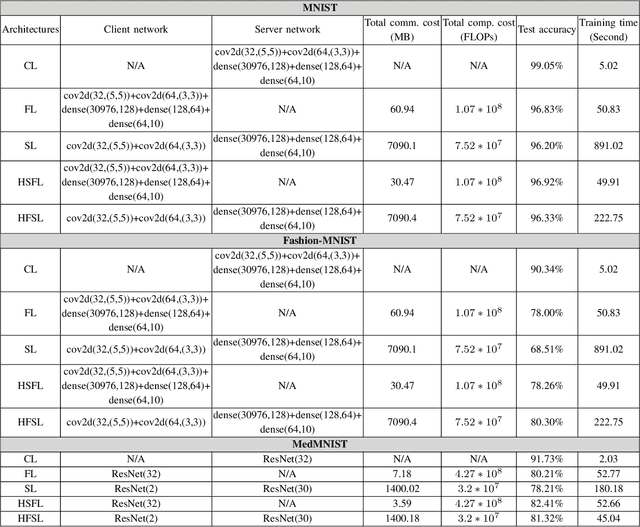
The ever-growing data privacy concerns have transformed machine learning (ML) architectures from centralized to distributed, leading to federated learning (FL) and split learning (SL) as the two most popular privacy-preserving ML paradigms. However, implementing either conventional FL or SL alone with diverse network conditions (e.g., device-to-device (D2D) and cellular communications) and heterogeneous clients (e.g., heterogeneous computation/communication/energy capabilities) may face significant challenges, particularly poor architecture scalability and long training time. To this end, this article proposes two novel hybrid distributed ML architectures, namely, hybrid split FL (HSFL) and hybrid federated SL (HFSL), by combining the advantages of both FL and SL in D2D-enabled heterogeneous wireless networks. Specifically, the performance comparison and advantages of HSFL and HFSL are analyzed generally. Promising open research directions are presented to offer commendable reference for future research. Finally, primary simulations are conducted upon considering three datasets under non-independent and identically distributed settings, to verify the feasibility of our proposed architectures, which can significantly reduce communication/computation cost and training time, as compared with conventional FL and SL.