 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinFLoRA: Incentivizing Client-Adaptive Aggregation in Federated LoRA under Privacy Heterogeneity
Feb 01, 2026Large Language Models (LLMs) increasingly underpin intelligent web applications, from chatbots to search and recommendation, where efficient specialization is essential. Low-Rank Adaptation (LoRA) enables such adaptation with minimal overhead, while federated LoRA allows web service providers to fine-tune shared models without data sharing. However, in privacy-sensitive deployments, clients inject varying levels of differential privacy (DP) noise, creating privacy heterogeneity that misaligns individual incentives and global performance. In this paper, we propose WinFLoRA, a privacy-heterogeneous federated LoRA that utilizes aggregation weights as incentives with noise awareness. Specifically, the noises from clients are estimated based on the uploaded LoRA adapters. A larger weight indicates greater influence on the global model and better downstream task performance, rewarding lower-noise contributions. By up-weighting low-noise updates, WinFLoRA improves global accuracy while accommodating clients' heterogeneous privacy requirements. Consequently, WinFLoRA aligns heterogeneous client utility in terms of privacy and downstream performance with global model objectives without third-party involvement. Extensive evaluations demonstrate that across multiple LLMs and datasets, WinFLoRA achieves up to 52.58% higher global accuracy and up to 2.56x client utility than state-of-the-art benchmarks. Source code is publicly available at https://github.com/koums24/WinFLoRA.git.
Game-Theoretic Safe Multi-Agent Motion Planning with Reachability Analysis for Dynamic and Uncertain Environments (Extended Version)
Nov 15, 2025Ensuring safe, robust, and scalable motion planning for multi-agent systems in dynamic and uncertain environments is a persistent challenge, driven by complex inter-agent interactions, stochastic disturbances, and model uncertainties. To overcome these challenges, particularly the computational complexity of coupled decision-making and the need for proactive safety guarantees, we propose a Reachability-Enhanced Dynamic Potential Game (RE-DPG) framework, which integrates game-theoretic coordination into reachability analysis. This approach formulates multi-agent coordination as a dynamic potential game, where the Nash equilibrium (NE) defines optimal control strategies across agents. To enable scalability and decentralized execution, we develop a Neighborhood-Dominated iterative Best Response (ND-iBR) scheme, built upon an iterated $\varepsilon$-BR (i$\varepsilon$-BR) process that guarantees finite-step convergence to an $\varepsilon$-NE. This allows agents to compute strategies based on local interactions while ensuring theoretical convergence guarantees. Furthermore, to ensure safety under uncertainty, we integrate a Multi-Agent Forward Reachable Set (MA-FRS) mechanism into the cost function, explicitly modeling uncertainty propagation and enforcing collision avoidance constraints. Through both simulations and real-world experiments in 2D and 3D environments, we validate the effectiveness of RE-DPG across diverse operational scenarios.
Slow is Fast! Dissecting Ethereum's Slow Liquidity Drain
Mar 06, 2025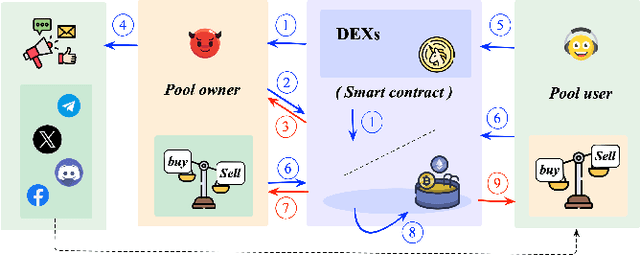
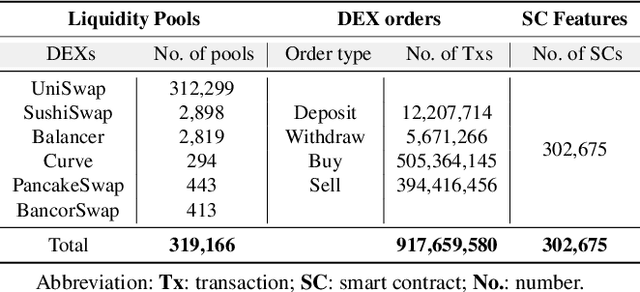
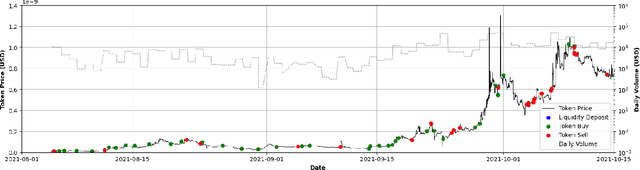
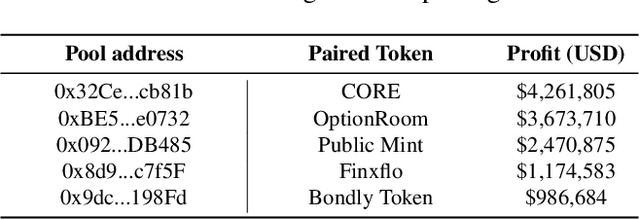
We identify the slow liquidity drain (SLID) scam, an insidious and highly profitable threat to decentralized finance (DeFi), posing a large-scale, persistent, and growing risk to the ecosystem. Unlike traditional scams such as rug pulls or honeypots (USENIX Sec'19, USENIX Sec'23), SLID gradually siphons funds from liquidity pools over extended periods, making detection significantly more challenging. In this paper, we conducted the first large-scale empirical analysis of 319,166 liquidity pools across six major decentralized exchanges (DEXs) since 2018. We identified 3,117 SLID affected liquidity pools, resulting in cumulative losses of more than US$103 million. We propose a rule-based heuristic and an enhanced machine learning model for early detection. Our machine learning model achieves a detection speed 4.77 times faster than the heuristic while maintaining 95% accuracy. Our study establishes a foundation for protecting DeFi investors at an early stage and promoting transparency in the DeFi ecosystem.
Privacy-Aware Joint DNN Model Deployment and Partition Optimization for Delay-Efficient Collaborative Edge Inference
Feb 22, 2025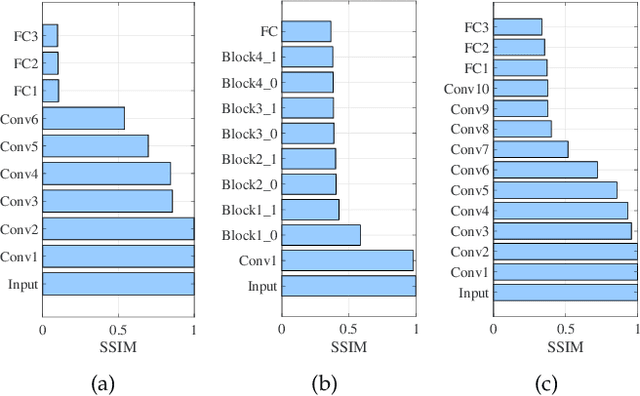
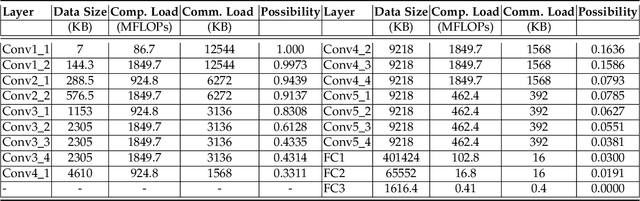

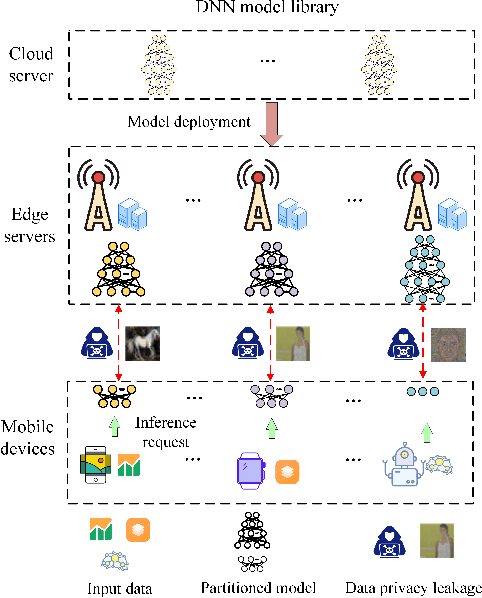
Edge inference (EI) is a key solution to address the growing challenges of delayed response times, limited scalability, and privacy concerns in cloud-based Deep Neural Network (DNN) inference. However, deploying DNN models on resource-constrained edge devices faces more severe challenges, such as model storage limitations, dynamic service requests, and privacy risks. This paper proposes a novel framework for privacy-aware joint DNN model deployment and partition optimization to minimize long-term average inference delay under resource and privacy constraints. Specifically, the problem is formulated as a complex optimization problem considering model deployment, user-server association, and model partition strategies. To handle the NP-hardness and future uncertainties, a Lyapunov-based approach is introduced to transform the long-term optimization into a single-time-slot problem, ensuring system performance. Additionally, a coalition formation game model is proposed for edge server association, and a greedy-based algorithm is developed for model deployment within each coalition to efficiently solve the problem. Extensive simulations show that the proposed algorithms effectively reduce inference delay while satisfying privacy constraints, outperforming baseline approaches in various scenarios.
Edge Unlearning is Not "on Edge"! An Adaptive Exact Unlearning System on Resource-Constrained Devices
Oct 15, 2024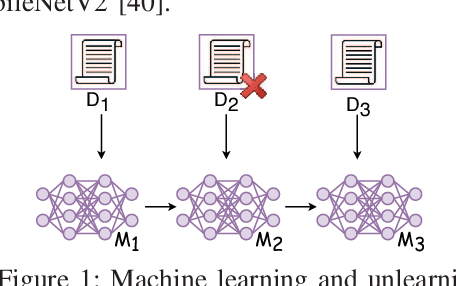
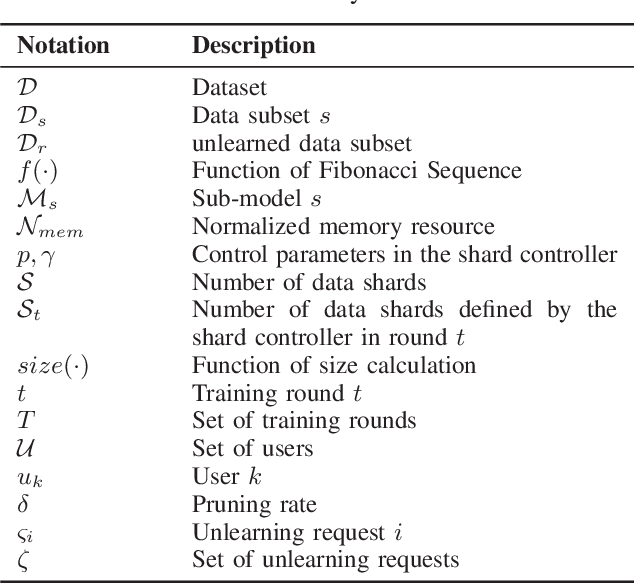
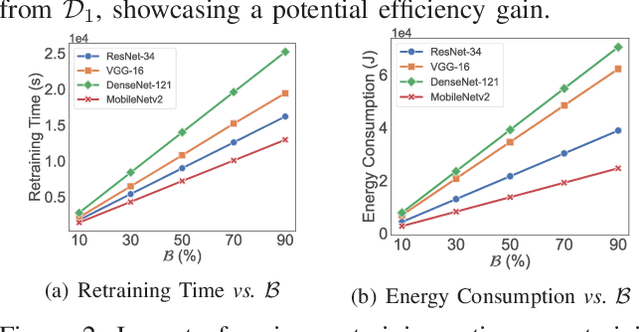
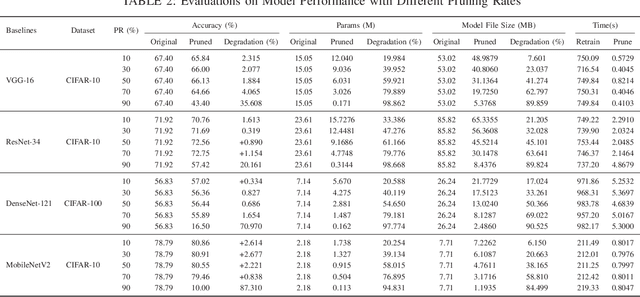
The right to be forgotten mandates that machine learning models enable the erasure of a data owner's data and information from a trained model. Removing data from the dataset alone is inadequate, as machine learning models can memorize information from the training data, increasing the potential privacy risk to users. To address this, multiple machine unlearning techniques have been developed and deployed. Among them, approximate unlearning is a popular solution, but recent studies report that its unlearning effectiveness is not fully guaranteed. Another approach, exact unlearning, tackles this issue by discarding the data and retraining the model from scratch, but at the cost of considerable computational and memory resources. However, not all devices have the capability to perform such retraining. In numerous machine learning applications, such as edge devices, Internet-of-Things (IoT), mobile devices, and satellites, resources are constrained, posing challenges for deploying existing exact unlearning methods. In this study, we propose a Constraint-aware Adaptive Exact Unlearning System at the network Edge (CAUSE), an approach to enabling exact unlearning on resource-constrained devices. Aiming to minimize the retrain overhead by storing sub-models on the resource-constrained device, CAUSE innovatively applies a Fibonacci-based replacement strategy and updates the number of shards adaptively in the user-based data partition process. To further improve the effectiveness of memory usage, CAUSE leverages the advantage of model pruning to save memory via compression with minimal accuracy sacrifice. The experimental results demonstrate that CAUSE significantly outperforms other representative systems in realizing exact unlearning on the resource-constrained device by 9.23%-80.86%, 66.21%-83.46%, and 5.26%-194.13% in terms of unlearning speed, energy consumption, and accuracy.
Towards Integrated Fine-tuning and Inference when Generative AI meets Edge Intelligence
Jan 05, 2024The high-performance generative artificial intelligence (GAI) represents the latest evolution of computational intelligence, while the blessing of future 6G networks also makes edge intelligence (EI) full of development potential. The inevitable encounter between GAI and EI can unleash new opportunities, where GAI's pre-training based on massive computing resources and large-scale unlabeled corpora can provide strong foundational knowledge for EI, while EI can harness fragmented computing resources to aggregate personalized knowledge for GAI. However, the natural contradictory features pose significant challenges to direct knowledge sharing. To address this, in this paper, we propose the GAI-oriented synthetical network (GaisNet), a collaborative cloud-edge-end intelligence framework that buffers contradiction leveraging data-free knowledge relay, where the bidirectional knowledge flow enables GAI's virtuous-cycle model fine-tuning and task inference, achieving mutualism between GAI and EI with seamless fusion and collaborative evolution. Experimental results demonstrate the effectiveness of the proposed mechanisms. Finally, we discuss the future challenges and directions in the interplay between GAI and EI.