 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Influence-aware Group Recommendation for Online Media Propagation
Jul 02, 2025Group recommendation over social media streams has attracted significant attention due to its wide applications in domains such as e-commerce, entertainment, and online news broadcasting. By leveraging social connections and group behaviours, group recommendation (GR) aims to provide more accurate and engaging content to a set of users rather than individuals. Recently, influence-aware GR has emerged as a promising direction, as it considers the impact of social influence on group decision-making. In earlier work, we proposed Influence-aware Group Recommendation (IGR) to solve this task. However, this task remains challenging due to three key factors: the large and ever-growing scale of social graphs, the inherently dynamic nature of influence propagation within user groups, and the high computational overhead of real-time group-item matching. To tackle these issues, we propose an Enhanced Influence-aware Group Recommendation (EIGR) framework. First, we introduce a Graph Extraction-based Sampling (GES) strategy to minimise redundancy across multiple temporal social graphs and effectively capture the evolving dynamics of both groups and items. Second, we design a novel DYnamic Independent Cascade (DYIC) model to predict how influence propagates over time across social items and user groups. Finally, we develop a two-level hash-based User Group Index (UG-Index) to efficiently organise user groups and enable real-time recommendation generation. Extensive experiments on real-world datasets demonstrate that our proposed framework, EIGR, consistently outperforms state-of-the-art baselines in both effectiveness and efficiency.
Slow is Fast! Dissecting Ethereum's Slow Liquidity Drain
Mar 06, 2025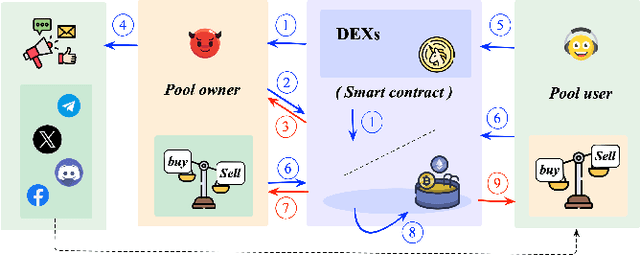
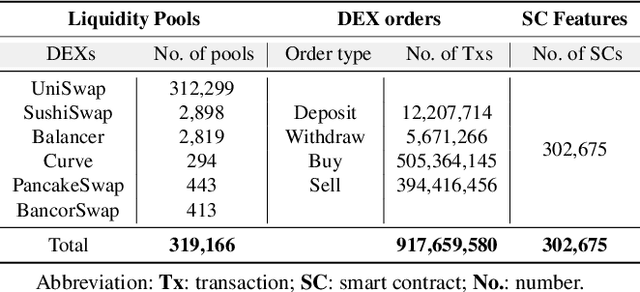
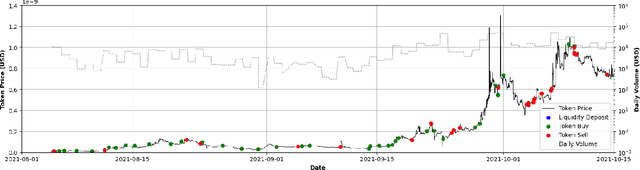
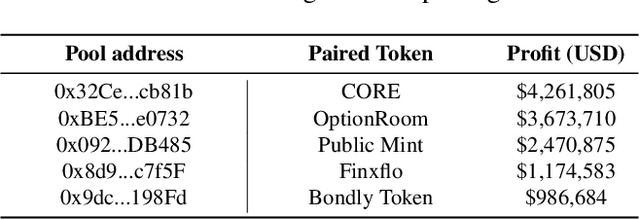
We identify the slow liquidity drain (SLID) scam, an insidious and highly profitable threat to decentralized finance (DeFi), posing a large-scale, persistent, and growing risk to the ecosystem. Unlike traditional scams such as rug pulls or honeypots (USENIX Sec'19, USENIX Sec'23), SLID gradually siphons funds from liquidity pools over extended periods, making detection significantly more challenging. In this paper, we conducted the first large-scale empirical analysis of 319,166 liquidity pools across six major decentralized exchanges (DEXs) since 2018. We identified 3,117 SLID affected liquidity pools, resulting in cumulative losses of more than US$103 million. We propose a rule-based heuristic and an enhanced machine learning model for early detection. Our machine learning model achieves a detection speed 4.77 times faster than the heuristic while maintaining 95% accuracy. Our study establishes a foundation for protecting DeFi investors at an early stage and promoting transparency in the DeFi ecosystem.
Security and Privacy for Artificial Intelligence: Opportunities and Challenges
Feb 09, 2021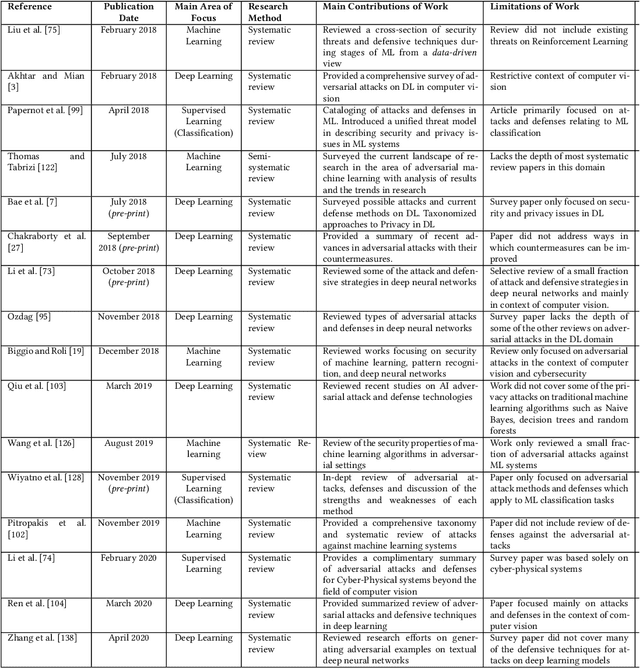
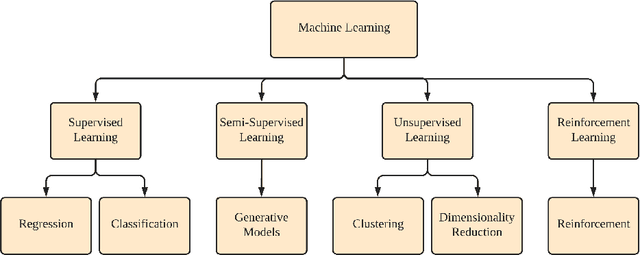
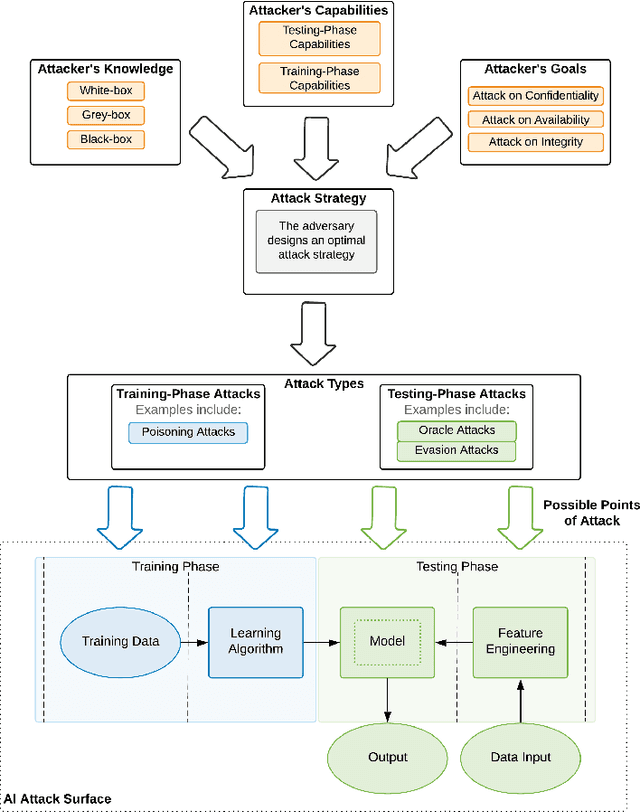
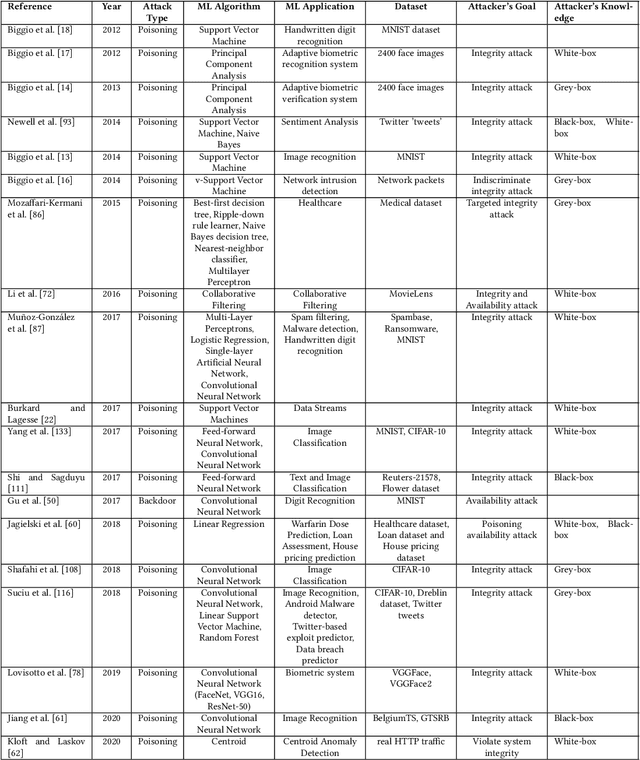
The increased adoption of Artificial Intelligence (AI) presents an opportunity to solve many socio-economic and environmental challenges; however, this cannot happen without securing AI-enabled technologies. In recent years, most AI models are vulnerable to advanced and sophisticated hacking techniques. This challenge has motivated concerted research efforts into adversarial AI, with the aim of developing robust machine and deep learning models that are resilient to different types of adversarial scenarios. In this paper, we present a holistic cyber security review that demonstrates adversarial attacks against AI applications, including aspects such as adversarial knowledge and capabilities, as well as existing methods for generating adversarial examples and existing cyber defence models. We explain mathematical AI models, especially new variants of reinforcement and federated learning, to demonstrate how attack vectors would exploit vulnerabilities of AI models. We also propose a systematic framework for demonstrating attack techniques against AI applications and reviewed several cyber defences that would protect AI applications against those attacks. We also highlight the importance of understanding the adversarial goals and their capabilities, especially the recent attacks against industry applications, to develop adaptive defences that assess to secure AI applications. Finally, we describe the main challenges and future research directions in the domain of security and privacy of AI technologies.
Correlated Differential Privacy: Feature Selection in Machine Learning
Oct 07, 2020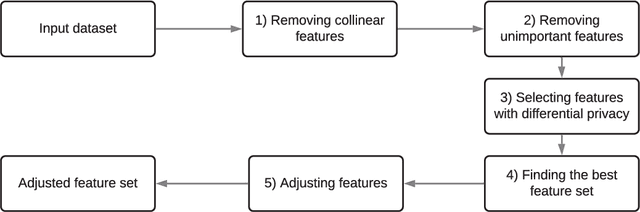
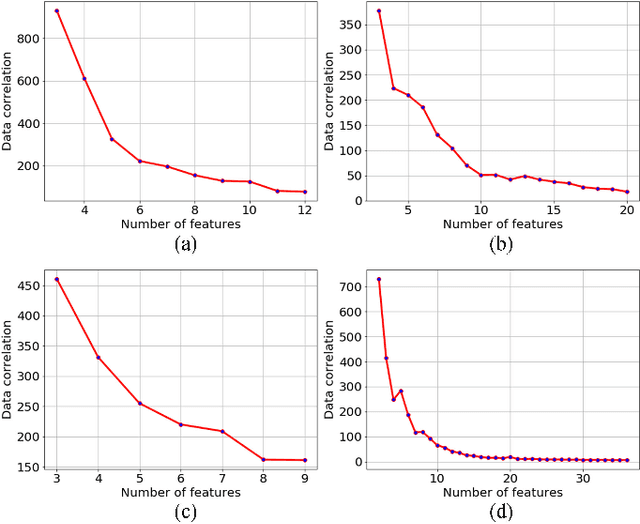
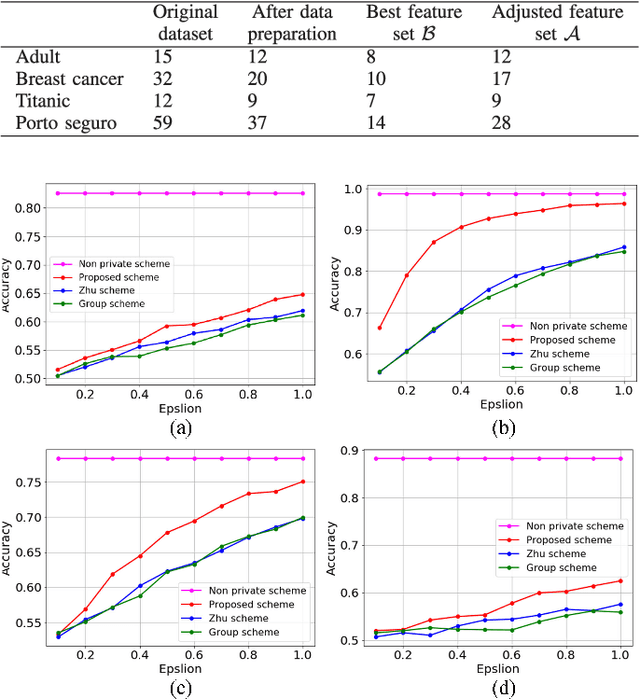
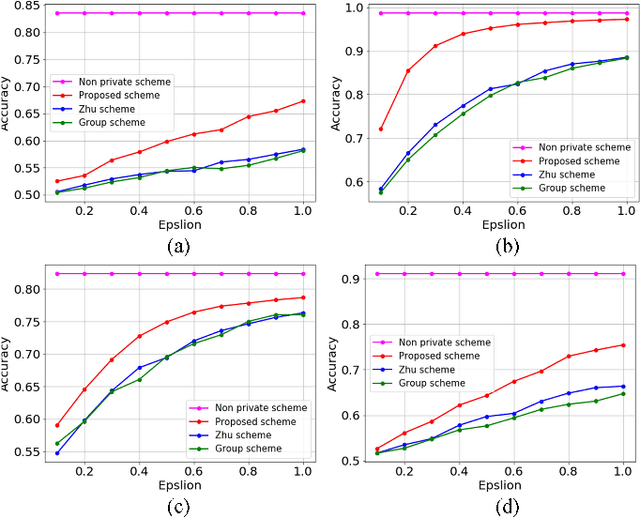
Privacy preserving in machine learning is a crucial issue in industry informatics since data used for training in industries usually contain sensitive information. Existing differentially private machine learning algorithms have not considered the impact of data correlation, which may lead to more privacy leakage than expected in industrial applications. For example, data collected for traffic monitoring may contain some correlated records due to temporal correlation or user correlation. To fill this gap, we propose a correlation reduction scheme with differentially private feature selection considering the issue of privacy loss when data have correlation in machine learning tasks. %The key to the proposed scheme is to describe the data correlation and select features which leads to less data correlation across the whole dataset. The proposed scheme involves five steps with the goal of managing the extent of data correlation, preserving the privacy, and supporting accuracy in the prediction results. In this way, the impact of data correlation is relieved with the proposed feature selection scheme, and moreover, the privacy issue of data correlation in learning is guaranteed. The proposed method can be widely used in machine learning algorithms which provide services in industrial areas. Experiments show that the proposed scheme can produce better prediction results with machine learning tasks and fewer mean square errors for data queries compared to existing schemes.
* This paper has been published in IEEE Transactions on Industrial Informatics