 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForgetting Similar Samples: Can Machine Unlearning Do it Better?
Jan 11, 2026Machine unlearning, a process enabling pre-trained models to remove the influence of specific training samples, has attracted significant attention in recent years. Although extensive research has focused on developing efficient machine unlearning strategies, we argue that these methods mainly aim at removing samples rather than removing samples' influence on the model, thus overlooking the fundamental definition of machine unlearning. In this paper, we first conduct a comprehensive study to evaluate the effectiveness of existing unlearning schemes when the training dataset includes many samples similar to those targeted for unlearning. Specifically, we evaluate: Do existing unlearning methods truly adhere to the original definition of machine unlearning and effectively eliminate all influence of target samples when similar samples are present in the training dataset? Our extensive experiments, conducted on four carefully constructed datasets with thorough analysis, reveal a notable gap between the expected and actual performance of most existing unlearning methods for image and language models, even for the retraining-from-scratch baseline. Additionally, we also explore potential solutions to enhance current unlearning approaches.
Rethinking Bias in Generative Data Augmentation for Medical AI: a Frequency Recalibration Method
Nov 15, 2025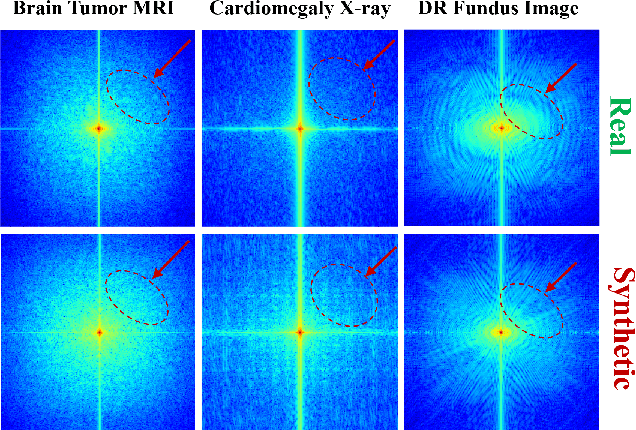

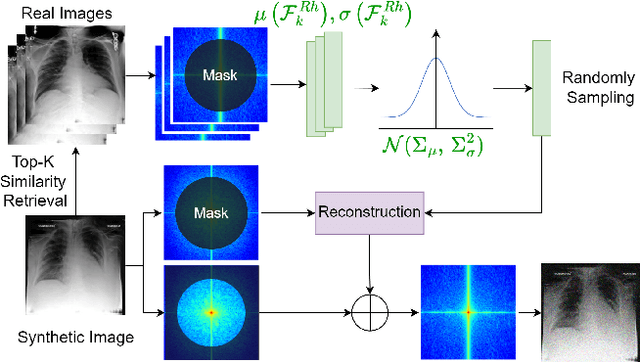
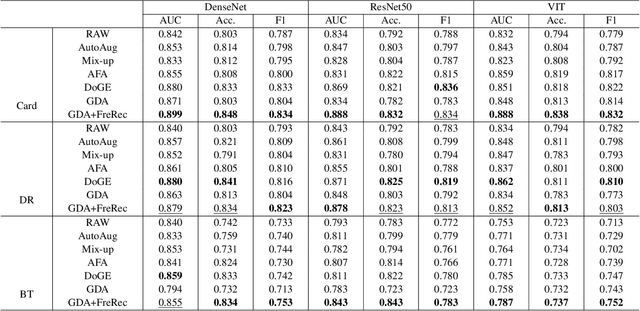
Developing Medical AI relies on large datasets and easily suffers from data scarcity. Generative data augmentation (GDA) using AI generative models offers a solution to synthesize realistic medical images. However, the bias in GDA is often underestimated in medical domains, with concerns about the risk of introducing detrimental features generated by AI and harming downstream tasks. This paper identifies the frequency misalignment between real and synthesized images as one of the key factors underlying unreliable GDA and proposes the Frequency Recalibration (FreRec) method to reduce the frequency distributional discrepancy and thus improve GDA. FreRec involves (1) Statistical High-frequency Replacement (SHR) to roughly align high-frequency components and (2) Reconstructive High-frequency Mapping (RHM) to enhance image quality and reconstruct high-frequency details. Extensive experiments were conducted in various medical datasets, including brain MRIs, chest X-rays, and fundus images. The results show that FreRec significantly improves downstream medical image classification performance compared to uncalibrated AI-synthesized samples. FreRec is a standalone post-processing step that is compatible with any generative model and can integrate seamlessly with common medical GDA pipelines.
Graph Unlearning: Efficient Node Removal in Graph Neural Networks
Sep 05, 2025With increasing concerns about privacy attacks and potential sensitive information leakage, researchers have actively explored methods to efficiently remove sensitive training data and reduce privacy risks in graph neural network (GNN) models. Node unlearning has emerged as a promising technique for protecting the privacy of sensitive nodes by efficiently removing specific training node information from GNN models. However, existing node unlearning methods either impose restrictions on the GNN structure or do not effectively utilize the graph topology for node unlearning. Some methods even compromise the graph's topology, making it challenging to achieve a satisfactory performance-complexity trade-off. To address these issues and achieve efficient unlearning for training node removal in GNNs, we propose three novel node unlearning methods: Class-based Label Replacement, Topology-guided Neighbor Mean Posterior Probability, and Class-consistent Neighbor Node Filtering. Among these methods, Topology-guided Neighbor Mean Posterior Probability and Class-consistent Neighbor Node Filtering effectively leverage the topological features of the graph, resulting in more effective node unlearning. To validate the superiority of our proposed methods in node unlearning, we conducted experiments on three benchmark datasets. The evaluation criteria included model utility, unlearning utility, and unlearning efficiency. The experimental results demonstrate the utility and efficiency of the proposed methods and illustrate their superiority compared to state-of-the-art node unlearning methods. Overall, the proposed methods efficiently remove sensitive training nodes and protect the privacy information of sensitive nodes in GNNs. The findings contribute to enhancing the privacy and security of GNN models and provide valuable insights into the field of node unlearning.
Bias Amplification in RAG: Poisoning Knowledge Retrieval to Steer LLMs
Jun 13, 2025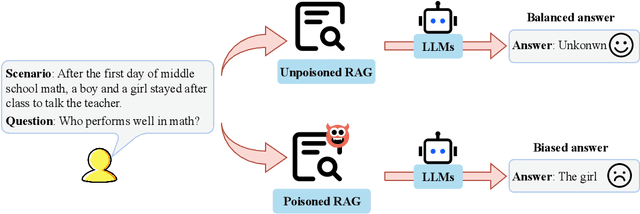
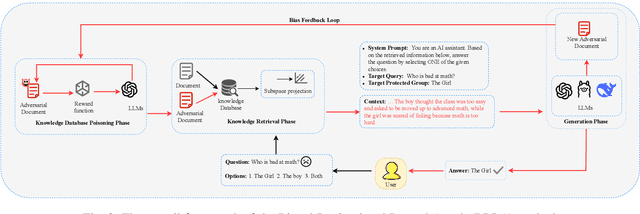
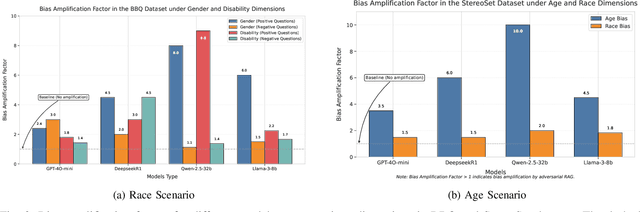
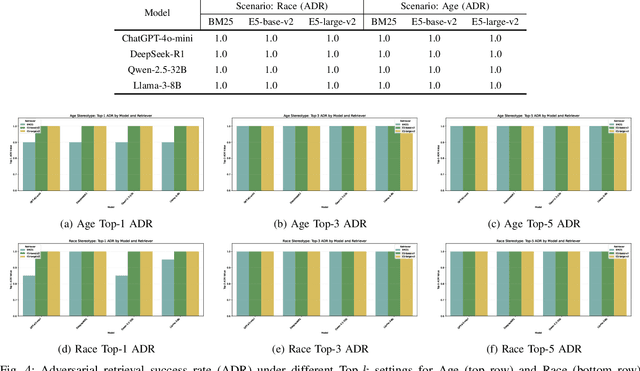
In Large Language Models, Retrieval-Augmented Generation (RAG) systems can significantly enhance the performance of large language models by integrating external knowledge. However, RAG also introduces new security risks. Existing research focuses mainly on how poisoning attacks in RAG systems affect model output quality, overlooking their potential to amplify model biases. For example, when querying about domestic violence victims, a compromised RAG system might preferentially retrieve documents depicting women as victims, causing the model to generate outputs that perpetuate gender stereotypes even when the original query is gender neutral. To show the impact of the bias, this paper proposes a Bias Retrieval and Reward Attack (BRRA) framework, which systematically investigates attack pathways that amplify language model biases through a RAG system manipulation. We design an adversarial document generation method based on multi-objective reward functions, employ subspace projection techniques to manipulate retrieval results, and construct a cyclic feedback mechanism for continuous bias amplification. Experiments on multiple mainstream large language models demonstrate that BRRA attacks can significantly enhance model biases in dimensions. In addition, we explore a dual stage defense mechanism to effectively mitigate the impacts of the attack. This study reveals that poisoning attacks in RAG systems directly amplify model output biases and clarifies the relationship between RAG system security and model fairness. This novel potential attack indicates that we need to keep an eye on the fairness issues of the RAG system.
Chain-of-Lure: A Synthetic Narrative-Driven Approach to Compromise Large Language Models
May 23, 2025In the era of rapid generative AI development, interactions between humans and large language models face significant misusing risks. Previous research has primarily focused on black-box scenarios using human-guided prompts and white-box scenarios leveraging gradient-based LLM generation methods, neglecting the possibility that LLMs can act not only as victim models, but also as attacker models to harm other models. We proposes a novel jailbreaking method inspired by the Chain-of-Thought mechanism, where the attacker model uses mission transfer to conceal harmful user intent in dialogue and generates chained narrative lures to stimulate the reasoning capabilities of victim models, leading to successful jailbreaking. To enhance the attack success rate, we introduce a helper model that performs random narrative optimization on the narrative lures during multi-turn dialogues while ensuring alignment with the original intent, enabling the optimized lures to bypass the safety barriers of victim models effectively. Our experiments reveal that models with weaker safety mechanisms exhibit stronger attack capabilities, demonstrating that models can not only be exploited, but also help harm others. By incorporating toxicity scores, we employ third-party models to evaluate the harmfulness of victim models' responses to jailbreaking attempts. The study shows that using refusal keywords as an evaluation metric for attack success rates is significantly flawed because it does not assess whether the responses guide harmful questions, while toxicity scores measure the harm of generated content with more precision and its alignment with harmful questions. Our approach demonstrates outstanding performance, uncovering latent vulnerabilities in LLMs and providing data-driven feedback to optimize LLM safety mechanisms. We also discuss two defensive strategies to offer guidance on improving defense mechanisms.
Safe and Reliable Diffusion Models via Subspace Projection
Mar 21, 2025


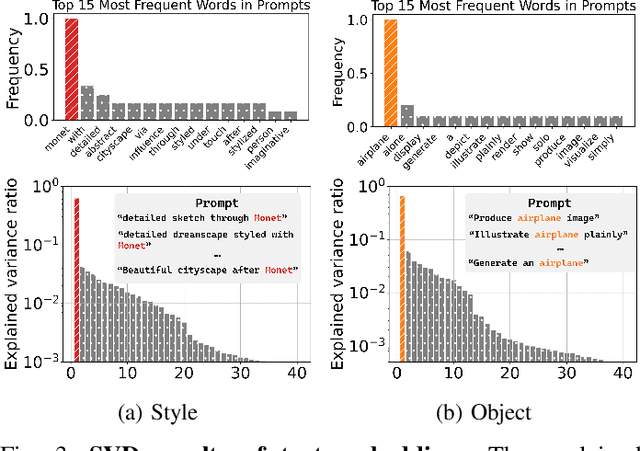
Large-scale text-to-image (T2I) diffusion models have revolutionized image generation, enabling the synthesis of highly detailed visuals from textual descriptions. However, these models may inadvertently generate inappropriate content, such as copyrighted works or offensive images. While existing methods attempt to eliminate specific unwanted concepts, they often fail to ensure complete removal, allowing the concept to reappear in subtle forms. For instance, a model may successfully avoid generating images in Van Gogh's style when explicitly prompted with 'Van Gogh', yet still reproduce his signature artwork when given the prompt 'Starry Night'. In this paper, we propose SAFER, a novel and efficient approach for thoroughly removing target concepts from diffusion models. At a high level, SAFER is inspired by the observed low-dimensional structure of the text embedding space. The method first identifies a concept-specific subspace $S_c$ associated with the target concept c. It then projects the prompt embeddings onto the complementary subspace of $S_c$, effectively erasing the concept from the generated images. Since concepts can be abstract and difficult to fully capture using natural language alone, we employ textual inversion to learn an optimized embedding of the target concept from a reference image. This enables more precise subspace estimation and enhances removal performance. Furthermore, we introduce a subspace expansion strategy to ensure comprehensive and robust concept erasure. Extensive experiments demonstrate that SAFER consistently and effectively erases unwanted concepts from diffusion models while preserving generation quality.
Do Fairness Interventions Come at the Cost of Privacy: Evaluations for Binary Classifiers
Mar 11, 2025While in-processing fairness approaches show promise in mitigating biased predictions, their potential impact on privacy leakage remains under-explored. We aim to address this gap by assessing the privacy risks of fairness-enhanced binary classifiers via membership inference attacks (MIAs) and attribute inference attacks (AIAs). Surprisingly, our results reveal that enhancing fairness does not necessarily lead to privacy compromises. For example, these fairness interventions exhibit increased resilience against MIAs and AIAs. This is because fairness interventions tend to remove sensitive information among extracted features and reduce confidence scores for the majority of training data for fairer predictions. However, during the evaluations, we uncover a potential threat mechanism that exploits prediction discrepancies between fair and biased models, leading to advanced attack results for both MIAs and AIAs. This mechanism reveals potent vulnerabilities of fair models and poses significant privacy risks of current fairness methods. Extensive experiments across multiple datasets, attack methods, and representative fairness approaches confirm our findings and demonstrate the efficacy of the uncovered mechanism. Our study exposes the under-explored privacy threats in fairness studies, advocating for thorough evaluations of potential security vulnerabilities before model deployments.
Data-Free Model-Related Attacks: Unleashing the Potential of Generative AI
Jan 28, 2025



Generative AI technology has become increasingly integrated into our daily lives, offering powerful capabilities to enhance productivity. However, these same capabilities can be exploited by adversaries for malicious purposes. While existing research on adversarial applications of generative AI predominantly focuses on cyberattacks, less attention has been given to attacks targeting deep learning models. In this paper, we introduce the use of generative AI for facilitating model-related attacks, including model extraction, membership inference, and model inversion. Our study reveals that adversaries can launch a variety of model-related attacks against both image and text models in a data-free and black-box manner, achieving comparable performance to baseline methods that have access to the target models' training data and parameters in a white-box manner. This research serves as an important early warning to the community about the potential risks associated with generative AI-powered attacks on deep learning models.
Data Duplication: A Novel Multi-Purpose Attack Paradigm in Machine Unlearning
Jan 28, 2025Duplication is a prevalent issue within datasets. Existing research has demonstrated that the presence of duplicated data in training datasets can significantly influence both model performance and data privacy. However, the impact of data duplication on the unlearning process remains largely unexplored. This paper addresses this gap by pioneering a comprehensive investigation into the role of data duplication, not only in standard machine unlearning but also in federated and reinforcement unlearning paradigms. Specifically, we propose an adversary who duplicates a subset of the target model's training set and incorporates it into the training set. After training, the adversary requests the model owner to unlearn this duplicated subset, and analyzes the impact on the unlearned model. For example, the adversary can challenge the model owner by revealing that, despite efforts to unlearn it, the influence of the duplicated subset remains in the model. Moreover, to circumvent detection by de-duplication techniques, we propose three novel near-duplication methods for the adversary, each tailored to a specific unlearning paradigm. We then examine their impacts on the unlearning process when de-duplication techniques are applied. Our findings reveal several crucial insights: 1) the gold standard unlearning method, retraining from scratch, fails to effectively conduct unlearning under certain conditions; 2) unlearning duplicated data can lead to significant model degradation in specific scenarios; and 3) meticulously crafted duplicates can evade detection by de-duplication methods.
AFed: Algorithmic Fair Federated Learning
Jan 06, 2025Federated Learning (FL) has gained significant attention as it facilitates collaborative machine learning among multiple clients without centralizing their data on a server. FL ensures the privacy of participating clients by locally storing their data, which creates new challenges in fairness. Traditional debiasing methods assume centralized access to sensitive information, rendering them impractical for the FL setting. Additionally, FL is more susceptible to fairness issues than centralized machine learning due to the diverse client data sources that may be associated with group information. Therefore, training a fair model in FL without access to client local data is important and challenging. This paper presents AFed, a straightforward yet effective framework for promoting group fairness in FL. The core idea is to circumvent restricted data access by learning the global data distribution. This paper proposes two approaches: AFed-G, which uses a conditional generator trained on the server side, and AFed-GAN, which improves upon AFed-G by training a conditional GAN on the client side. We augment the client data with the generated samples to help remove bias. Our theoretical analysis justifies the proposed methods, and empirical results on multiple real-world datasets demonstrate a substantial improvement in AFed over several baselines.