 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey of Knowledge-Based Vision Question Answering Systems: The Lifecycle of Knowledge in Visual Reasoning Task
Apr 24, 2025Knowledge-based Vision Question Answering (KB-VQA) extends general Vision Question Answering (VQA) by not only requiring the understanding of visual and textual inputs but also extensive range of knowledge, enabling significant advancements across various real-world applications. KB-VQA introduces unique challenges, including the alignment of heterogeneous information from diverse modalities and sources, the retrieval of relevant knowledge from noisy or large-scale repositories, and the execution of complex reasoning to infer answers from the combined context. With the advancement of Large Language Models (LLMs), KB-VQA systems have also undergone a notable transformation, where LLMs serve as powerful knowledge repositories, retrieval-augmented generators and strong reasoners. Despite substantial progress, no comprehensive survey currently exists that systematically organizes and reviews the existing KB-VQA methods. This survey aims to fill this gap by establishing a structured taxonomy of KB-VQA approaches, and categorizing the systems into main stages: knowledge representation, knowledge retrieval, and knowledge reasoning. By exploring various knowledge integration techniques and identifying persistent challenges, this work also outlines promising future research directions, providing a foundation for advancing KB-VQA models and their applications.
UniRVQA: A Unified Framework for Retrieval-Augmented Vision Question Answering via Self-Reflective Joint Training
Apr 05, 2025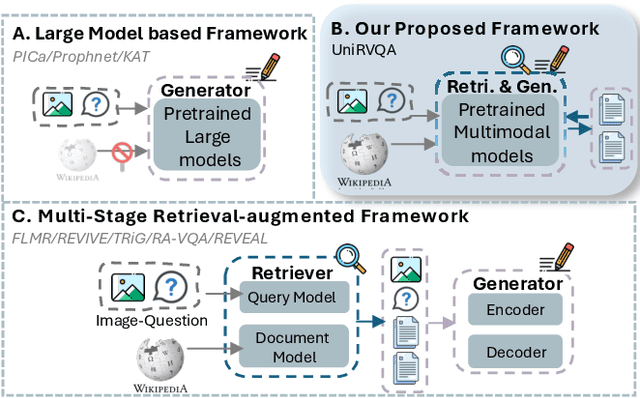
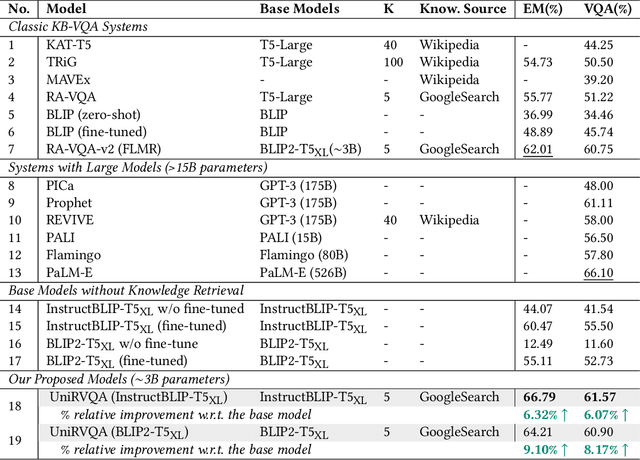
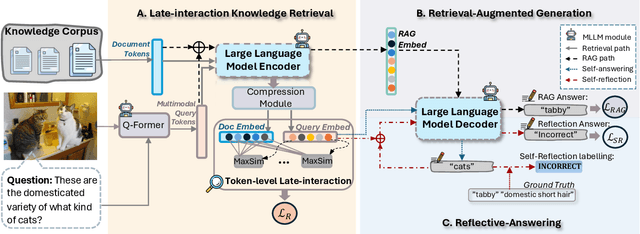
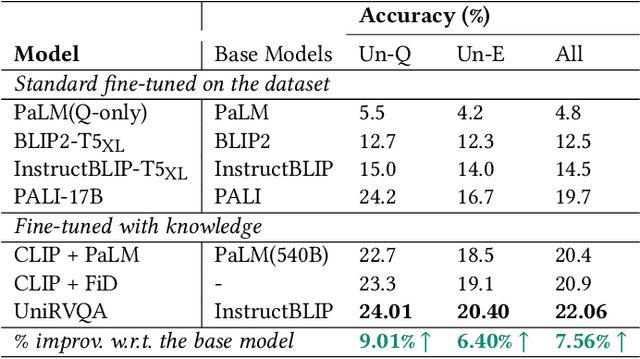
Knowledge-based Vision Question Answering (KB-VQA) systems address complex visual-grounded questions requiring external knowledge, such as web-sourced encyclopedia articles. Existing methods often use sequential and separate frameworks for the retriever and the generator with limited parametric knowledge sharing. However, since both retrieval and generation tasks require accurate understanding of contextual and external information, such separation can potentially lead to suboptimal system performance. Another key challenge is the integration of multimodal information. General-purpose multimodal pre-trained models, while adept at multimodal representation learning, struggle with fine-grained retrieval required for knowledge-intensive visual questions. Recent specialized pre-trained models mitigate the issue, but are computationally expensive. To bridge the gap, we propose a Unified Retrieval-Augmented VQA framework (UniRVQA). UniRVQA adapts general multimodal pre-trained models for fine-grained knowledge-intensive tasks within a unified framework, enabling cross-task parametric knowledge sharing and the extension of existing multimodal representation learning capability. We further introduce a reflective-answering mechanism that allows the model to explicitly evaluate and refine its knowledge boundary. Additionally, we integrate late interaction into the retrieval-augmented generation joint training process to enhance fine-grained understanding of queries and documents. Our approach achieves competitive performance against state-of-the-art models, delivering a significant 4.7% improvement in answering accuracy, and brings an average 7.5% boost in base MLLMs' VQA performance.
Vertical Federated Unlearning via Backdoor Certification
Dec 16, 2024Vertical Federated Learning (VFL) offers a novel paradigm in machine learning, enabling distinct entities to train models cooperatively while maintaining data privacy. This method is particularly pertinent when entities possess datasets with identical sample identifiers but diverse attributes. Recent privacy regulations emphasize an individual's \emph{right to be forgotten}, which necessitates the ability for models to unlearn specific training data. The primary challenge is to develop a mechanism to eliminate the influence of a specific client from a model without erasing all relevant data from other clients. Our research investigates the removal of a single client's contribution within the VFL framework. We introduce an innovative modification to traditional VFL by employing a mechanism that inverts the typical learning trajectory with the objective of extracting specific data contributions. This approach seeks to optimize model performance using gradient ascent, guided by a pre-defined constrained model. We also introduce a backdoor mechanism to verify the effectiveness of the unlearning procedure. Our method avoids fully accessing the initial training data and avoids storing parameter updates. Empirical evidence shows that the results align closely with those achieved by retraining from scratch. Utilizing gradient ascent, our unlearning approach addresses key challenges in VFL, laying the groundwork for future advancements in this domain. All the code and implementations related to this paper are publicly available at https://github.com/mengde-han/VFL-unlearn.
Predicting Financial Literacy via Semi-supervised Learning
Dec 18, 2023Financial literacy (FL) represents a person's ability to turn assets into income, and understanding digital currencies has been added to the modern definition. FL can be predicted by exploiting unlabelled recorded data in financial networks via semi-supervised learning (SSL). Measuring and predicting FL has not been widely studied, resulting in limited understanding of customer financial engagement consequences. Previous studies have shown that low FL increases the risk of social harm. Therefore, it is important to accurately estimate FL to allocate specific intervention programs to less financially literate groups. This will not only increase company profitability, but will also reduce government spending. Some studies considered predicting FL in classification tasks, whereas others developed FL definitions and impacts. The current paper investigated mechanisms to learn customer FL level from their financial data using sampling by synthetic minority over-sampling techniques for regression with Gaussian noise (SMOGN). We propose the SMOGN-COREG model for semi-supervised regression, applying SMOGN to deal with unbalanced datasets and a nonparametric multi-learner co-regression (COREG) algorithm for labeling. We compared the SMOGN-COREG model with six well-known regressors on five datasets to evaluate the proposed models effectiveness on unbalanced and unlabelled financial data. Experimental results confirmed that the proposed method outperformed the comparator models for unbalanced and unlabelled financial data. Therefore, SMOGN-COREG is a step towards using unlabelled data to estimate FL level.
* 12 pages
An Extended Variational Mode Decomposition Algorithm Developed Speech Emotion Recognition Performance
Dec 18, 2023Emotion recognition (ER) from speech signals is a robust approach since it cannot be imitated like facial expression or text based sentiment analysis. Valuable information underlying the emotions are significant for human-computer interactions enabling intelligent machines to interact with sensitivity in the real world. Previous ER studies through speech signal processing have focused exclusively on associations between different signal mode decomposition methods and hidden informative features. However, improper decomposition parameter selections lead to informative signal component losses due to mode duplicating and mixing. In contrast, the current study proposes VGG-optiVMD, an empowered variational mode decomposition algorithm, to distinguish meaningful speech features and automatically select the number of decomposed modes and optimum balancing parameter for the data fidelity constraint by assessing their effects on the VGG16 flattening output layer. Various feature vectors were employed to train the VGG16 network on different databases and assess VGG-optiVMD reproducibility and reliability. One, two, and three-dimensional feature vectors were constructed by concatenating Mel-frequency cepstral coefficients, Chromagram, Mel spectrograms, Tonnetz diagrams, and spectral centroids. Results confirmed a synergistic relationship between the fine-tuning of the signal sample rate and decomposition parameters with classification accuracy, achieving state-of-the-art 96.09% accuracy in predicting seven emotions on the Berlin EMO-DB database.
* 12 pages
Leveraged Mel spectrograms using Harmonic and Percussive Components in Speech Emotion Recognition
Dec 18, 2023Speech Emotion Recognition (SER) affective technology enables the intelligent embedded devices to interact with sensitivity. Similarly, call centre employees recognise customers' emotions from their pitch, energy, and tone of voice so as to modify their speech for a high-quality interaction with customers. This work explores, for the first time, the effects of the harmonic and percussive components of Mel spectrograms in SER. We attempt to leverage the Mel spectrogram by decomposing distinguishable acoustic features for exploitation in our proposed architecture, which includes a novel feature map generator algorithm, a CNN-based network feature extractor and a multi-layer perceptron (MLP) classifier. This study specifically focuses on effective data augmentation techniques for building an enriched hybrid-based feature map. This process results in a function that outputs a 2D image so that it can be used as input data for a pre-trained CNN-VGG16 feature extractor. Furthermore, we also investigate other acoustic features such as MFCCs, chromagram, spectral contrast, and the tonnetz to assess our proposed framework. A test accuracy of 92.79% on the Berlin EMO-DB database is achieved. Our result is higher than previous works using CNN-VGG16.
* 12 pages
Churn Prediction via Multimodal Fusion Learning:Integrating Customer Financial Literacy, Voice, and Behavioral Data
Dec 03, 2023In todays competitive landscape, businesses grapple with customer retention. Churn prediction models, although beneficial, often lack accuracy due to the reliance on a single data source. The intricate nature of human behavior and high dimensional customer data further complicate these efforts. To address these concerns, this paper proposes a multimodal fusion learning model for identifying customer churn risk levels in financial service providers. Our multimodal approach integrates customer sentiments financial literacy (FL) level, and financial behavioral data, enabling more accurate and bias-free churn prediction models. The proposed FL model utilizes a SMOGN COREG supervised model to gauge customer FL levels from their financial data. The baseline churn model applies an ensemble artificial neural network and oversampling techniques to predict churn propensity in high-dimensional financial data. We also incorporate a speech emotion recognition model employing a pre-trained CNN-VGG16 to recognize customer emotions based on pitch, energy, and tone. To integrate these diverse features while retaining unique insights, we introduced late and hybrid fusion techniques that complementary boost coordinated multimodal co learning. Robust metrics were utilized to evaluate the proposed multimodal fusion model and hence the approach validity, including mean average precision and macro-averaged F1 score. Our novel approach demonstrates a marked improvement in churn prediction, achieving a test accuracy of 91.2%, a Mean Average Precision (MAP) score of 66, and a Macro-Averaged F1 score of 54 through the proposed hybrid fusion learning technique compared with late fusion and baseline models. Furthermore, the analysis demonstrates a positive correlation between negative emotions, low FL scores, and high-risk customers.
Improved Churn Causal Analysis Through Restrained High-Dimensional Feature Space Effects in Financial Institutions
Apr 23, 2023Customer churn describes terminating a relationship with a business or reducing customer engagement over a specific period. Customer acquisition cost can be five to six times that of customer retention, hence investing in customers with churn risk is wise. Causal analysis of the churn model can predict whether a customer will churn in the foreseeable future and identify effects and possible causes for churn. In general, this study presents a conceptual framework to discover the confounding features that correlate with independent variables and are causally related to those dependent variables that impact churn. We combine different algorithms including the SMOTE, ensemble ANN, and Bayesian networks to address churn prediction problems on a massive and high-dimensional finance data that is usually generated in financial institutions due to employing interval-based features used in Customer Relationship Management systems. The effects of the curse and blessing of dimensionality assessed by utilising the Recursive Feature Elimination method to overcome the high dimension feature space problem. Moreover, a causal discovery performed to find possible interpretation methods to describe cause probabilities that lead to customer churn. Evaluation metrics on validation data confirm the random forest and our ensemble ANN model, with %86 accuracy, outperformed other approaches. Causal analysis results confirm that some independent causal variables representing the level of super guarantee contribution, account growth, and account balance amount were identified as confounding variables that cause customer churn with a high degree of belief. This article provides a real-world customer churn analysis from current status inference to future directions in local superannuation funds.
* Human-Centric Intelligent Systems 2022. arXiv admin note: substantial text overlap with arXiv:2304.10604
Causal Analysis of Customer Churn Using Deep Learning
Apr 20, 2023Customer churn describes terminating a relationship with a business or reducing customer engagement over a specific period. Two main business marketing strategies play vital roles to increase market share dollar-value: gaining new and preserving existing customers. Customer acquisition cost can be five to six times that for customer retention, hence investing in customers with churn risk is smart. Causal analysis of the churn model can predict whether a customer will churn in the foreseeable future and assist enterprises to identify effects and possible causes for churn and subsequently use that knowledge to apply tailored incentives. This paper proposes a framework using a deep feedforward neural network for classification accompanied by a sequential pattern mining method on high-dimensional sparse data. We also propose a causal Bayesian network to predict cause probabilities that lead to customer churn. Evaluation metrics on test data confirm the XGBoost and our deep learning model outperformed previous techniques. Experimental analysis confirms that some independent causal variables representing the level of super guarantee contribution, account growth, and customer tenure were identified as confounding factors for customer churn with a high degree of belief. This paper provides a real-world customer churn analysis from current status inference to future directions in local superannuation funds.
* 6 pages
High-order Spatial Interactions Enhanced Lightweight Model for Optical Remote Sensing Image-based Small Ship Detection
Apr 07, 2023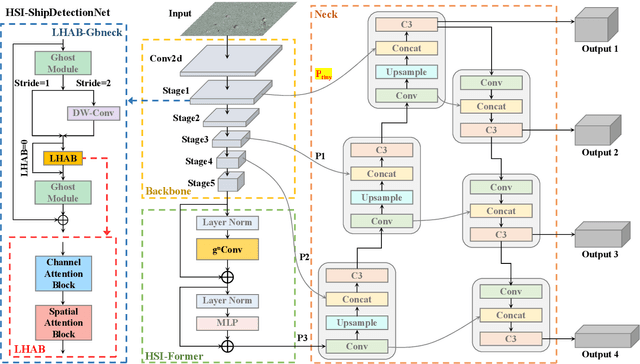
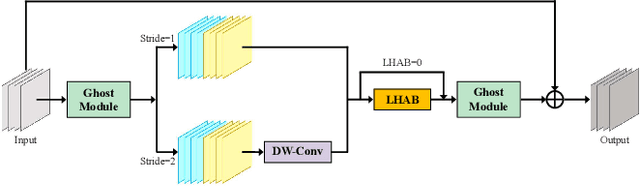
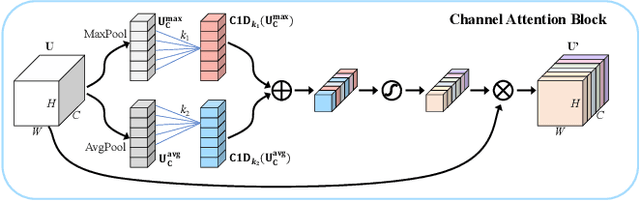
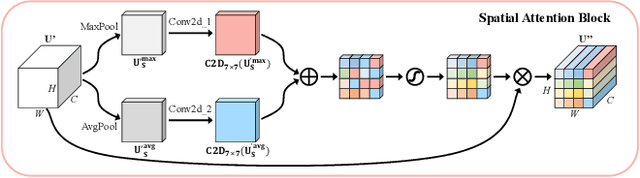
Accurate and reliable optical remote sensing image-based small-ship detection is crucial for maritime surveillance systems, but existing methods often struggle with balancing detection performance and computational complexity. In this paper, we propose a novel lightweight framework called \textit{HSI-ShipDetectionNet} that is based on high-order spatial interactions and is suitable for deployment on resource-limited platforms, such as satellites and unmanned aerial vehicles. HSI-ShipDetectionNet includes a prediction branch specifically for tiny ships and a lightweight hybrid attention block for reduced complexity. Additionally, the use of a high-order spatial interactions module improves advanced feature understanding and modeling ability. Our model is evaluated using the public Kaggle marine ship detection dataset and compared with multiple state-of-the-art models including small object detection models, lightweight detection models, and ship detection models. The results show that HSI-ShipDetectionNet outperforms the other models in terms of recall, and mean average precision (mAP) while being lightweight and suitable for deployment on resource-limited platforms.