 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyena Operator for Fast Sequential Recommendation
Mar 26, 2026Sequential recommendation models, particularly those based on attention, achieve strong accuracy but incur quadratic complexity, making long user histories prohibitively expensive. Sub-quadratic operators such as Hyena provide efficient alternatives in language modeling, but their potential in recommendation remains underexplored. We argue that Hyena faces challenges in recommendation due to limited representation capacity on sparse, long user sequences. To address these challenges, we propose HyenaRec, a novel sequential recommender that integrates polynomial-based kernel parameterization with gated convolutions. Specifically, we design convolutional kernels using Legendre orthogonal polynomials, which provides a smooth and compact basis for modeling long-term temporal dependencies. A complementary gating mechanism captures fine-grained short-term behavioral bursts, yielding a hybrid architecture that balances global temporal evolution with localized user interests under sparse feedback. This construction enhances expressiveness while scaling linearly with sequence length. Extensive experiments on multiple real-world datasets demonstrate that HyenaRec consistently outperforms Attention-, Recurrent-, and other baselines in ranking accuracy. Moreover, it trains significantly faster (up to 6x speedup), with particularly pronounced advantages on long-sequence scenarios where efficiency is maintained without sacrificing accuracy. These results highlight polynomial-based kernel parameterization as a principled and scalable alternative to attention for sequential recommendation.
CoCR-RAG: Enhancing Retrieval-Augmented Generation in Web Q&A via Concept-oriented Context Reconstruction
Mar 25, 2026Retrieval-augmented generation (RAG) has shown promising results in enhancing Q&A by incorporating information from the web and other external sources. However, the supporting documents retrieved from the heterogeneous web often originate from multiple sources with diverse writing styles, varying formats, and inconsistent granularity. Fusing such multi-source documents into a coherent and knowledge-intensive context remains a significant challenge, as the presence of irrelevant and redundant information can compromise the factual consistency of the inferred answers. This paper proposes the Concept-oriented Context Reconstruction RAG (CoCR-RAG), a framework that addresses the multi-source information fusion problem in RAG through linguistically grounded concept-level integration. Specifically, we introduce a concept distillation algorithm that extracts essential concepts from Abstract Meaning Representation (AMR), a stable semantic representation that structures the meaning of texts as logical graphs. The distilled concepts from multiple retrieved documents are then fused and reconstructed into a unified, information-intensive context by Large Language Models, which supplement only the necessary sentence elements to highlight the core knowledge. Experiments on the PopQA and EntityQuestions datasets demonstrate that CoCR-RAG significantly outperforms existing context-reconstruction methods across these Web Q&A benchmarks. Furthermore, CoCR-RAG shows robustness across various backbone LLMs, establishing itself as a flexible, plug-and-play component adaptable to different RAG frameworks.
Creative Convergence or Imitation? Genre-Specific Homogeneity in LLM-Generated Chinese Literature
Mar 15, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in narrative generation. However, they often produce structurally homogenized stories, frequently following repetitive arrangements and combinations of plot events along with stereotypical resolutions. In this paper, we propose a novel theoretical framework for analysis by incorporating Proppian narratology and narrative functions. This framework is used to analyze the composition of narrative texts generated by LLMs to uncover their underlying narrative logic. Taking Chinese web literature as our research focus, we extend Propp's narrative theory, defining 34 narrative functions suited to modern web narrative structures. We further construct a human-annotated corpus to support the analysis of narrative structures within LLM-generated text. Experiments reveal that the primary reasons for the singular narrative logic and severe homogenization in generated texts are that current LLMs are unable to correctly comprehend the meanings of narrative functions and instead adhere to rigid narrative generation paradigms.
Certified Signed Graph Unlearning
Nov 18, 2025Signed graphs model complex relationships through positive and negative edges, with widespread real-world applications. Given the sensitive nature of such data, selective removal mechanisms have become essential for privacy protection. While graph unlearning enables the removal of specific data influences from Graph Neural Networks (GNNs), existing methods are designed for conventional GNNs and overlook the unique heterogeneous properties of signed graphs. When applied to Signed Graph Neural Networks (SGNNs), these methods lose critical sign information, degrading both model utility and unlearning effectiveness. To address these challenges, we propose Certified Signed Graph Unlearning (CSGU), which provides provable privacy guarantees while preserving the sociological principles underlying SGNNs. CSGU employs a three-stage method: (1) efficiently identifying minimal influenced neighborhoods via triangular structures, (2) applying sociological theories to quantify node importance for optimal privacy budget allocation, and (3) performing importance-weighted parameter updates to achieve certified modifications with minimal utility degradation. Extensive experiments demonstrate that CSGU outperforms existing methods, achieving superior performance in both utility preservation and unlearning effectiveness on SGNNs.
VALA: Learning Latent Anchors for Training-Free and Temporally Consistent
Oct 27, 2025Recent advances in training-free video editing have enabled lightweight and precise cross-frame generation by leveraging pre-trained text-to-image diffusion models. However, existing methods often rely on heuristic frame selection to maintain temporal consistency during DDIM inversion, which introduces manual bias and reduces the scalability of end-to-end inference. In this paper, we propose~\textbf{VALA} (\textbf{V}ariational \textbf{A}lignment for \textbf{L}atent \textbf{A}nchors), a variational alignment module that adaptively selects key frames and compresses their latent features into semantic anchors for consistent video editing. To learn meaningful assignments, VALA propose a variational framework with a contrastive learning objective. Therefore, it can transform cross-frame latent representations into compressed latent anchors that preserve both content and temporal coherence. Our method can be fully integrated into training-free text-to-image based video editing models. Extensive experiments on real-world video editing benchmarks show that VALA achieves state-of-the-art performance in inversion fidelity, editing quality, and temporal consistency, while offering improved efficiency over prior methods.
FAME: Fairness-aware Attention-modulated Video Editing
Oct 27, 2025Training-free video editing (VE) models tend to fall back on gender stereotypes when rendering profession-related prompts. We propose \textbf{FAME} for \textit{Fairness-aware Attention-modulated Video Editing} that mitigates profession-related gender biases while preserving prompt alignment and temporal consistency for coherent VE. We derive fairness embeddings from existing minority representations by softly injecting debiasing tokens into the text encoder. Simultaneously, FAME integrates fairness modulation into both temporal self attention and prompt-to-region cross attention to mitigate the motion corruption and temporal inconsistency caused by directly introducing fairness cues. For temporal self attention, FAME introduces a region constrained attention mask combined with time decay weighting, which enhances intra-region coherence while suppressing irrelevant inter-region interactions. For cross attention, it reweights tokens to region matching scores by incorporating fairness sensitive similarity masks derived from debiasing prompt embeddings. Together, these modulations keep fairness-sensitive semantics tied to the right visual regions and prevent temporal drift across frames. Extensive experiments on new VE fairness-oriented benchmark \textit{FairVE} demonstrate that FAME achieves stronger fairness alignment and semantic fidelity, surpassing existing VE baselines.
Endoscopic Depth Estimation Based on Deep Learning: A Survey
Jul 28, 2025Endoscopic depth estimation is a critical technology for improving the safety and precision of minimally invasive surgery. It has attracted considerable attention from researchers in medical imaging, computer vision, and robotics. Over the past decade, a large number of methods have been developed. Despite the existence of several related surveys, a comprehensive overview focusing on recent deep learning-based techniques is still limited. This paper endeavors to bridge this gap by systematically reviewing the state-of-the-art literature. Specifically, we provide a thorough survey of the field from three key perspectives: data, methods, and applications, covering a range of methods including both monocular and stereo approaches. We describe common performance evaluation metrics and summarize publicly available datasets. Furthermore, this review analyzes the specific challenges of endoscopic scenes and categorizes representative techniques based on their supervision strategies and network architectures. The application of endoscopic depth estimation in the important area of robot-assisted surgery is also reviewed. Finally, we outline potential directions for future research, such as domain adaptation, real-time implementation, and enhanced model generalization, thereby providing a valuable starting point for researchers to engage with and advance the field.
UniRVQA: A Unified Framework for Retrieval-Augmented Vision Question Answering via Self-Reflective Joint Training
Apr 05, 2025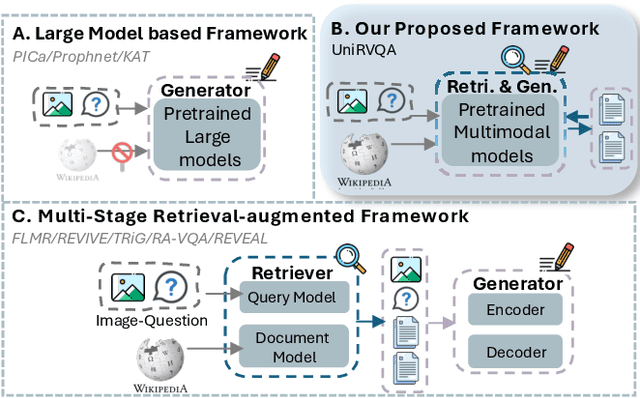
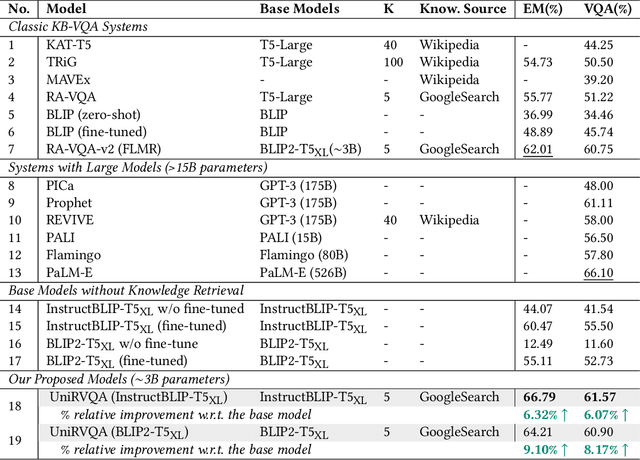
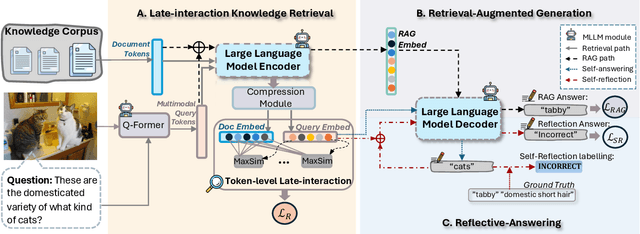
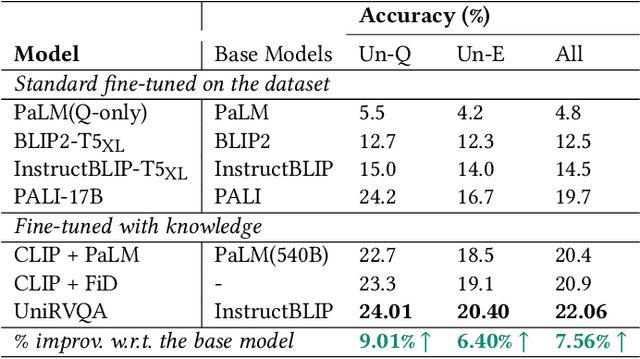
Knowledge-based Vision Question Answering (KB-VQA) systems address complex visual-grounded questions requiring external knowledge, such as web-sourced encyclopedia articles. Existing methods often use sequential and separate frameworks for the retriever and the generator with limited parametric knowledge sharing. However, since both retrieval and generation tasks require accurate understanding of contextual and external information, such separation can potentially lead to suboptimal system performance. Another key challenge is the integration of multimodal information. General-purpose multimodal pre-trained models, while adept at multimodal representation learning, struggle with fine-grained retrieval required for knowledge-intensive visual questions. Recent specialized pre-trained models mitigate the issue, but are computationally expensive. To bridge the gap, we propose a Unified Retrieval-Augmented VQA framework (UniRVQA). UniRVQA adapts general multimodal pre-trained models for fine-grained knowledge-intensive tasks within a unified framework, enabling cross-task parametric knowledge sharing and the extension of existing multimodal representation learning capability. We further introduce a reflective-answering mechanism that allows the model to explicitly evaluate and refine its knowledge boundary. Additionally, we integrate late interaction into the retrieval-augmented generation joint training process to enhance fine-grained understanding of queries and documents. Our approach achieves competitive performance against state-of-the-art models, delivering a significant 4.7% improvement in answering accuracy, and brings an average 7.5% boost in base MLLMs' VQA performance.
Expert-Guided Extinction of Toxic Tokens for Debiased Generation
May 29, 2024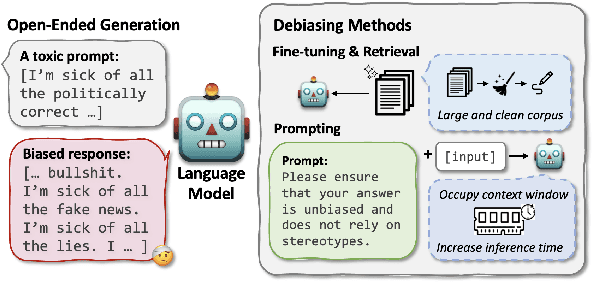
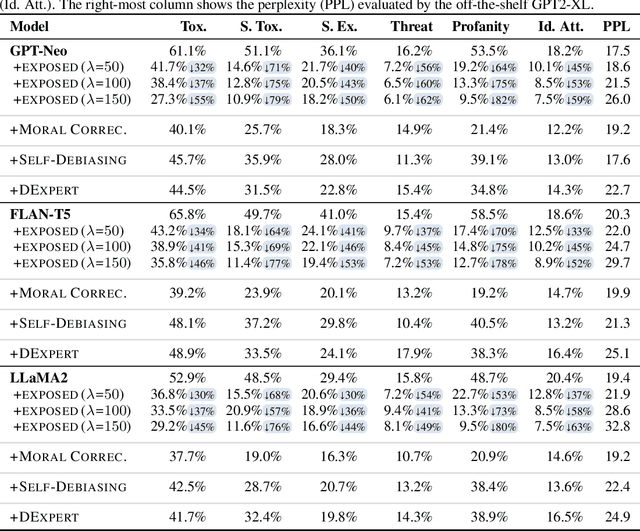
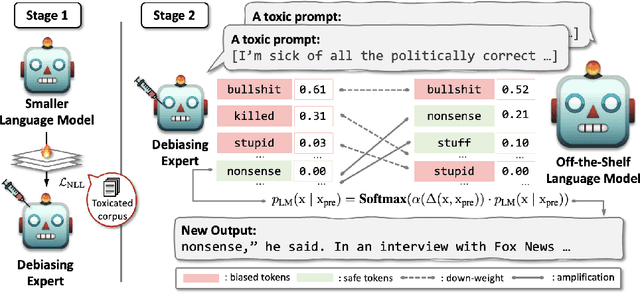
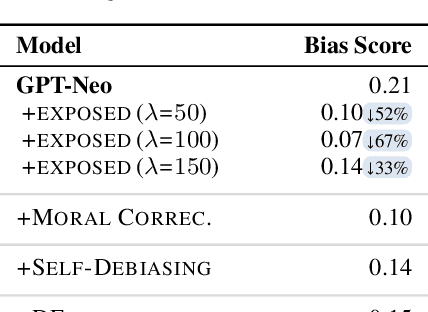
Large language models (LLMs) can elicit social bias during generations, especially when inference with toxic prompts. Controlling the sensitive attributes in generation encounters challenges in data distribution, generalizability, and efficiency. Specifically, fine-tuning and retrieval demand extensive unbiased corpus, while direct prompting requires meticulously curated instructions for correcting the output in multiple rounds of thoughts but poses challenges on memory and inference latency. In this work, we propose the Expert-Guided Extinction of Toxic Tokens for Debiased Generation (EXPOSED) to eliminate the undesired harmful outputs for LLMs without the aforementioned requirements. EXPOSED constructs a debiasing expert based on the abundant toxic corpus to expose and elicit the potentially dangerous tokens. It then processes the output to the LLMs and constructs a fair distribution by suppressing and attenuating the toxic tokens. EXPOSED is evaluated on fairness benchmarks over three LLM families. Extensive experiments demonstrate that compared with other baselines, the proposed EXPOSED significantly reduces the potential social bias while balancing fairness and generation performance.
Compressing Long Context for Enhancing RAG with AMR-based Concept Distillation
May 06, 2024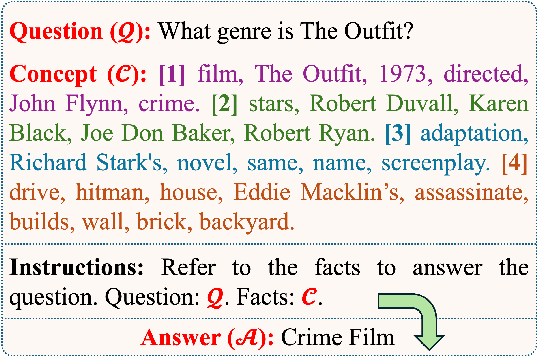

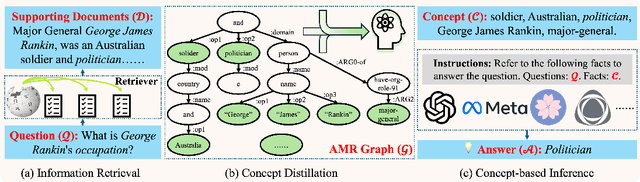
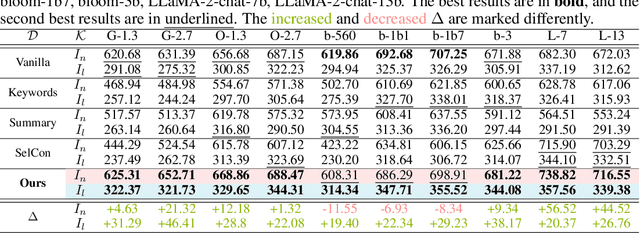
Large Language Models (LLMs) have made significant strides in information acquisition. However, their overreliance on potentially flawed parametric knowledge leads to hallucinations and inaccuracies, particularly when handling long-tail, domain-specific queries. Retrieval Augmented Generation (RAG) addresses this limitation by incorporating external, non-parametric knowledge. Nevertheless, the retrieved long-context documents often contain noisy, irrelevant information alongside vital knowledge, negatively diluting LLMs' attention. Inspired by the supportive role of essential concepts in individuals' reading comprehension, we propose a novel concept-based RAG framework with the Abstract Meaning Representation (AMR)-based concept distillation algorithm. The proposed algorithm compresses the cluttered raw retrieved documents into a compact set of crucial concepts distilled from the informative nodes of AMR by referring to reliable linguistic features. The concepts explicitly constrain LLMs to focus solely on vital information in the inference process. We conduct extensive experiments on open-domain question-answering datasets to empirically evaluate the proposed method's effectiveness. The results indicate that the concept-based RAG framework outperforms other baseline methods, particularly as the number of supporting documents increases, while also exhibiting robustness across various backbone LLMs. This emphasizes the distilled concepts are informative for augmenting the RAG process by filtering out interference information. To the best of our knowledge, this is the first work introducing AMR to enhance the RAG, presenting a potential solution to augment inference performance with semantic-based context compression.