 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreative Convergence or Imitation? Genre-Specific Homogeneity in LLM-Generated Chinese Literature
Mar 15, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in narrative generation. However, they often produce structurally homogenized stories, frequently following repetitive arrangements and combinations of plot events along with stereotypical resolutions. In this paper, we propose a novel theoretical framework for analysis by incorporating Proppian narratology and narrative functions. This framework is used to analyze the composition of narrative texts generated by LLMs to uncover their underlying narrative logic. Taking Chinese web literature as our research focus, we extend Propp's narrative theory, defining 34 narrative functions suited to modern web narrative structures. We further construct a human-annotated corpus to support the analysis of narrative structures within LLM-generated text. Experiments reveal that the primary reasons for the singular narrative logic and severe homogenization in generated texts are that current LLMs are unable to correctly comprehend the meanings of narrative functions and instead adhere to rigid narrative generation paradigms.
TimeRadar: A Domain-Rotatable Foundation Model for Time Series Anomaly Detection
Feb 22, 2026Current time series foundation models (TSFMs) primarily focus on learning prevalent and regular patterns within a predefined time or frequency domain to enable supervised downstream tasks (e.g., forecasting). Consequently, they are often ineffective for inherently unsupervised downstream tasks-such as time series anomaly detection (TSAD), which aims to identify rare, irregular patterns. This limitation arises because such abnormal patterns can closely resemble the regular patterns when presented in the same time/frequency domain. To address this issue, we introduce TimeRadar, an innovative TSFM built in a fractional time-frequency domain to support generalist TSAD across diverse unseen datasets. Our key insight is that rotating a time series into a data-dependent fractional time-frequency representation can adaptively differentiate the normal and abnormal signals across different datasets. To this end, a novel component, namely Fractionally modulated Time-Frequency Reconstruction (FTFRecon), is proposed in TimeRadar to leverage a learnable fractional order to rotate the time series to the most pronounced angle between a continuous time and frequency domain for accurate data reconstruction. This provides adaptive data reconstruction in an optimal time-frequency domain for each data input, enabling effective differentiation of the unbounded abnormal patterns from the regular ones across datasets, including unseen datasets. To allow TimeRadar to model local abnormality that is not captured by the global data reconstruction, we further introduce a Contextual Deviation Learning (CDL) component to model the local deviation of the input relative to its contextual time series data in the rotatable domain.
SVBench: Evaluation of Video Generation Models on Social Reasoning
Dec 25, 2025Recent text-to-video generation models exhibit remarkable progress in visual realism, motion fidelity, and text-video alignment, yet they remain fundamentally limited in their ability to generate socially coherent behavior. Unlike humans, who effortlessly infer intentions, beliefs, emotions, and social norms from brief visual cues, current models tend to render literal scenes without capturing the underlying causal or psychological logic. To systematically evaluate this gap, we introduce the first benchmark for social reasoning in video generation. Grounded in findings from developmental and social psychology, our benchmark organizes thirty classic social cognition paradigms into seven core dimensions, including mental-state inference, goal-directed action, joint attention, social coordination, prosocial behavior, social norms, and multi-agent strategy. To operationalize these paradigms, we develop a fully training-free agent-based pipeline that (i) distills the reasoning mechanism of each experiment, (ii) synthesizes diverse video-ready scenarios, (iii) enforces conceptual neutrality and difficulty control through cue-based critique, and (iv) evaluates generated videos using a high-capacity VLM judge across five interpretable dimensions of social reasoning. Using this framework, we conduct the first large-scale study across seven state-of-the-art video generation systems. Our results reveal substantial performance gaps: while modern models excel in surface-level plausibility, they systematically fail in intention recognition, belief reasoning, joint attention, and prosocial inference.
Circumventing Backdoor Space via Weight Symmetry
Jun 09, 2025Deep neural networks are vulnerable to backdoor attacks, where malicious behaviors are implanted during training. While existing defenses can effectively purify compromised models, they typically require labeled data or specific training procedures, making them difficult to apply beyond supervised learning settings. Notably, recent studies have shown successful backdoor attacks across various learning paradigms, highlighting a critical security concern. To address this gap, we propose Two-stage Symmetry Connectivity (TSC), a novel backdoor purification defense that operates independently of data format and requires only a small fraction of clean samples. Through theoretical analysis, we prove that by leveraging permutation invariance in neural networks and quadratic mode connectivity, TSC amplifies the loss on poisoned samples while maintaining bounded clean accuracy. Experiments demonstrate that TSC achieves robust performance comparable to state-of-the-art methods in supervised learning scenarios. Furthermore, TSC generalizes to self-supervised learning frameworks, such as SimCLR and CLIP, maintaining its strong defense capabilities. Our code is available at https://github.com/JiePeng104/TSC.
FGSGT: Saliency-Guided Siamese Network Tracker Based on Key Fine-Grained Feature Information for Thermal Infrared Target Tracking
Apr 19, 2025Thermal infrared (TIR) images typically lack detailed features and have low contrast, making it challenging for conventional feature extraction models to capture discriminative target characteristics. As a result, trackers are often affected by interference from visually similar objects and are susceptible to tracking drift. To address these challenges, we propose a novel saliency-guided Siamese network tracker based on key fine-grained feature infor-mation. First, we introduce a fine-grained feature parallel learning convolu-tional block with a dual-stream architecture and convolutional kernels of varying sizes. This design captures essential global features from shallow layers, enhances feature diversity, and minimizes the loss of fine-grained in-formation typically encountered in residual connections. In addition, we propose a multi-layer fine-grained feature fusion module that uses bilinear matrix multiplication to effectively integrate features across both deep and shallow layers. Next, we introduce a Siamese residual refinement block that corrects saliency map prediction errors using residual learning. Combined with deep supervision, this mechanism progressively refines predictions, ap-plying supervision at each recursive step to ensure consistent improvements in accuracy. Finally, we present a saliency loss function to constrain the sali-ency predictions, directing the network to focus on highly discriminative fi-ne-grained features. Extensive experiment results demonstrate that the pro-posed tracker achieves the highest precision and success rates on the PTB-TIR and LSOTB-TIR benchmarks. It also achieves a top accuracy of 0.78 on the VOT-TIR 2015 benchmark and 0.75 on the VOT-TIR 2017 benchmark.
DCFG: Diverse Cross-Channel Fine-Grained Feature Learning and Progressive Fusion Siamese Tracker for Thermal Infrared Target Tracking
Apr 19, 2025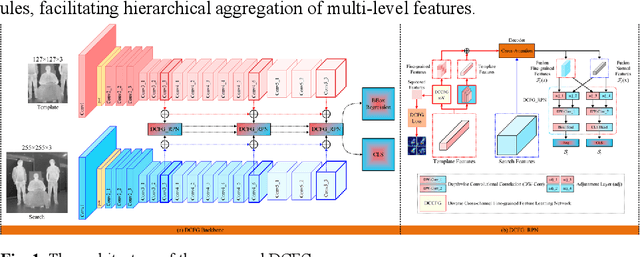

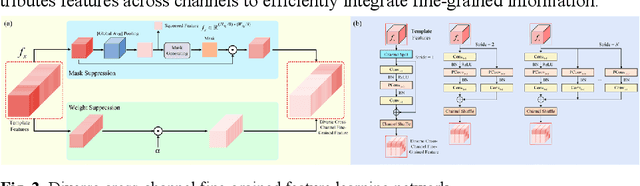

To address the challenge of capturing highly discriminative features in ther-mal infrared (TIR) tracking, we propose a novel Siamese tracker based on cross-channel fine-grained feature learning and progressive fusion. First, we introduce a cross-channel fine-grained feature learning network that employs masks and suppression coefficients to suppress dominant target features, en-abling the tracker to capture more detailed and subtle information. The net-work employs a channel rearrangement mechanism to enhance efficient in-formation flow, coupled with channel equalization to reduce parameter count. Additionally, we incorporate layer-by-layer combination units for ef-fective feature extraction and fusion, thereby minimizing parameter redun-dancy and computational complexity. The network further employs feature redirection and channel shuffling strategies to better integrate fine-grained details. Second, we propose a specialized cross-channel fine-grained loss function designed to guide feature groups toward distinct discriminative re-gions of the target, thus improving overall target representation. This loss function includes an inter-channel loss term that promotes orthogonality be-tween channels, maximizing feature diversity and facilitating finer detail capture. Extensive experiments demonstrate that our proposed tracker achieves the highest accuracy, scoring 0.81 on the VOT-TIR 2015 and 0.78 on the VOT-TIR 2017 benchmark, while also outperforming other methods across all evaluation metrics on the LSOTB-TIR and PTB-TIR benchmarks.
RURANET++: An Unsupervised Learning Method for Diabetic Macular Edema Based on SCSE Attention Mechanisms and Dynamic Multi-Projection Head Clustering
Feb 27, 2025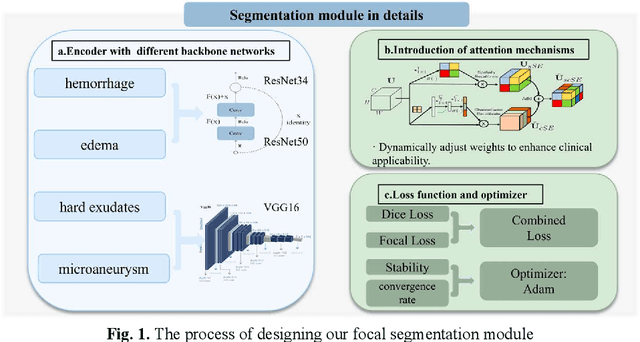
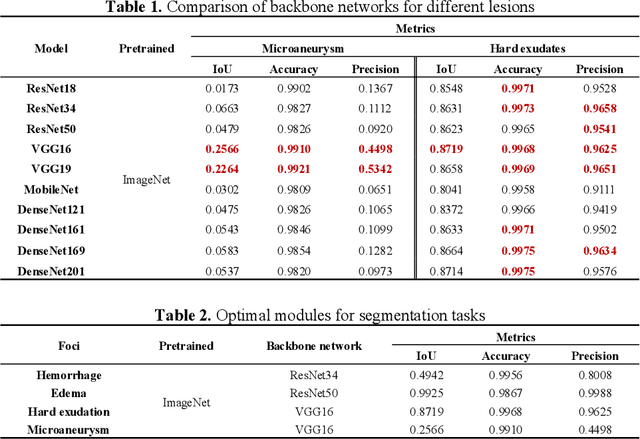
Diabetic Macular Edema (DME), a prevalent complication among diabetic patients, constitutes a major cause of visual impairment and blindness. Although deep learning has achieved remarkable progress in medical image analysis, traditional DME diagnosis still relies on extensive annotated data and subjective ophthalmologist assessments, limiting practical applications. To address this, we present RURANET++, an unsupervised learning-based automated DME diagnostic system. This framework incorporates an optimized U-Net architecture with embedded Spatial and Channel Squeeze & Excitation (SCSE) attention mechanisms to enhance lesion feature extraction. During feature processing, a pre-trained GoogLeNet model extracts deep features from retinal images, followed by PCA-based dimensionality reduction to 50 dimensions for computational efficiency. Notably, we introduce a novel clustering algorithm employing multi-projection heads to explicitly control cluster diversity while dynamically adjusting similarity thresholds, thereby optimizing intra-class consistency and inter-class discrimination. Experimental results demonstrate superior performance across multiple metrics, achieving maximum accuracy (0.8411), precision (0.8593), recall (0.8411), and F1-score (0.8390), with exceptional clustering quality. This work provides an efficient unsupervised solution for DME diagnosis with significant clinical implications.
FilterNet: Harnessing Frequency Filters for Time Series Forecasting
Nov 05, 2024


While numerous forecasters have been proposed using different network architectures, the Transformer-based models have state-of-the-art performance in time series forecasting. However, forecasters based on Transformers are still suffering from vulnerability to high-frequency signals, efficiency in computation, and bottleneck in full-spectrum utilization, which essentially are the cornerstones for accurately predicting time series with thousands of points. In this paper, we explore a novel perspective of enlightening signal processing for deep time series forecasting. Inspired by the filtering process, we introduce one simple yet effective network, namely FilterNet, built upon our proposed learnable frequency filters to extract key informative temporal patterns by selectively passing or attenuating certain components of time series signals. Concretely, we propose two kinds of learnable filters in the FilterNet: (i) Plain shaping filter, that adopts a universal frequency kernel for signal filtering and temporal modeling; (ii) Contextual shaping filter, that utilizes filtered frequencies examined in terms of its compatibility with input signals for dependency learning. Equipped with the two filters, FilterNet can approximately surrogate the linear and attention mappings widely adopted in time series literature, while enjoying superb abilities in handling high-frequency noises and utilizing the whole frequency spectrum that is beneficial for forecasting. Finally, we conduct extensive experiments on eight time series forecasting benchmarks, and experimental results have demonstrated our superior performance in terms of both effectiveness and efficiency compared with state-of-the-art methods. Code is available at this repository: https://github.com/aikunyi/FilterNet
How to Bridge Spatial and Temporal Heterogeneity in Link Prediction? A Contrastive Method
Nov 01, 2024


Temporal Heterogeneous Networks play a crucial role in capturing the dynamics and heterogeneity inherent in various real-world complex systems, rendering them a noteworthy research avenue for link prediction. However, existing methods fail to capture the fine-grained differential distribution patterns and temporal dynamic characteristics, which we refer to as spatial heterogeneity and temporal heterogeneity. To overcome such limitations, we propose a novel \textbf{C}ontrastive Learning-based \textbf{L}ink \textbf{P}rediction model, \textbf{CLP}, which employs a multi-view hierarchical self-supervised architecture to encode spatial and temporal heterogeneity. Specifically, aiming at spatial heterogeneity, we develop a spatial feature modeling layer to capture the fine-grained topological distribution patterns from node- and edge-level representations, respectively. Furthermore, aiming at temporal heterogeneity, we devise a temporal information modeling layer to perceive the evolutionary dependencies of dynamic graph topologies from time-level representations. Finally, we encode the spatial and temporal distribution heterogeneity from a contrastive learning perspective, enabling a comprehensive self-supervised hierarchical relation modeling for the link prediction task. Extensive experiments conducted on four real-world dynamic heterogeneous network datasets verify that our \mymodel consistently outperforms the state-of-the-art models, demonstrating an average improvement of 10.10\%, 13.44\% in terms of AUC and AP, respectively.
Multi-SIGATnet: A multimodal schizophrenia MRI classification algorithm using sparse interaction mechanisms and graph attention networks
Aug 25, 2024



Schizophrenia is a serious psychiatric disorder. Its pathogenesis is not completely clear, making it difficult to treat patients precisely. Because of the complicated non-Euclidean network structure of the human brain, learning critical information from brain networks remains difficult. To effectively capture the topological information of brain neural networks, a novel multimodal graph attention network based on sparse interaction mechanism (Multi-SIGATnet) was proposed for SZ classification was proposed for SZ classification. Firstly, structural and functional information were fused into multimodal data to obtain more comprehensive and abundant features for patients with SZ. Subsequently, a sparse interaction mechanism was proposed to effectively extract salient features and enhance the feature representation capability. By enhancing the strong connections and weakening the weak connections between feature information based on an asymmetric convolutional network, high-order interactive features were captured. Moreover, sparse learning strategies were designed to filter out redundant connections to improve model performance. Finally, local and global features were updated in accordance with the topological features and connection weight constraints of the higher-order brain network, the features being projected to the classification target space for disorder classification. The effectiveness of the model is verified on the Center for Biomedical Research Excellence (COBRE) and University of California Los Angeles (UCLA) datasets, achieving 81.9\% and 75.8\% average accuracy, respectively, 4.6\% and 5.5\% higher than the graph attention network (GAT) method. Experiments showed that the Multi-SIGATnet method exhibited good performance in identifying SZ.