 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMMT: Siamese Motion Mamba with Self-attention for Thermal Infrared Target Tracking
May 07, 2025Thermal infrared (TIR) object tracking often suffers from challenges such as target occlusion, motion blur, and background clutter, which significantly degrade the performance of trackers. To address these issues, this paper pro-poses a novel Siamese Motion Mamba Tracker (SMMT), which integrates a bidirectional state-space model and a self-attention mechanism. Specifically, we introduce the Motion Mamba module into the Siamese architecture to ex-tract motion features and recover overlooked edge details using bidirectional modeling and self-attention. We propose a Siamese parameter-sharing strate-gy that allows certain convolutional layers to share weights. This approach reduces computational redundancy while preserving strong feature represen-tation. In addition, we design a motion edge-aware regression loss to improve tracking accuracy, especially for motion-blurred targets. Extensive experi-ments are conducted on four TIR tracking benchmarks, including LSOTB-TIR, PTB-TIR, VOT-TIR2015, and VOT-TIR 2017. The results show that SMMT achieves superior performance in TIR target tracking.
STARS: Sparse Learning Correlation Filter with Spatio-temporal Regularization and Super-resolution Reconstruction for Thermal Infrared Target Tracking
Apr 20, 2025Thermal infrared (TIR) target tracking methods often adopt the correlation filter (CF) framework due to its computational efficiency. However, the low resolution of TIR images, along with tracking interference, significantly limits the perfor-mance of TIR trackers. To address these challenges, we introduce STARS, a novel sparse learning-based CF tracker that incorporates spatio-temporal regulari-zation and super-resolution reconstruction. First, we apply adaptive sparse filter-ing and temporal domain filtering to extract key features of the target while reduc-ing interference from background clutter and noise. Next, we introduce an edge-preserving sparse regularization method to stabilize target features and prevent excessive blurring. This regularization integrates multiple terms and employs the alternating direction method of multipliers to optimize the solution. Finally, we propose a gradient-enhanced super-resolution method to extract fine-grained TIR target features and improve the resolution of TIR images, addressing performance degradation in tracking caused by low-resolution sequences. To the best of our knowledge, STARS is the first to integrate super-resolution methods within a sparse learning-based CF framework. Extensive experiments on the LSOTB-TIR, PTB-TIR, VOT-TIR2015, and VOT-TIR2017 benchmarks demonstrate that STARS outperforms state-of-the-art trackers in terms of robustness.
SMTT: Novel Structured Multi-task Tracking with Graph-Regularized Sparse Representation for Robust Thermal Infrared Target Tracking
Apr 20, 2025Thermal infrared target tracking is crucial in applications such as surveillance, autonomous driving, and military operations. In this paper, we propose a novel tracker, SMTT, which effectively addresses common challenges in thermal infrared imagery, such as noise, occlusion, and rapid target motion, by leveraging multi-task learning, joint sparse representation, and adaptive graph regularization. By reformulating the tracking task as a multi-task learning problem, the SMTT tracker independently optimizes the representation of each particle while dynamically capturing spatial and feature-level similarities using a weighted mixed-norm regularization strategy. To ensure real-time performance, we incorporate the Accelerated Proximal Gradient method for efficient optimization. Extensive experiments on benchmark datasets - including VOT-TIR, PTB-TIR, and LSOTB-TIR - demonstrate that SMTT achieves superior accuracy, robustness, and computational efficiency. These results highlight SMTT as a reliable and high-performance solution for thermal infrared target tracking in complex environments.
FGSGT: Saliency-Guided Siamese Network Tracker Based on Key Fine-Grained Feature Information for Thermal Infrared Target Tracking
Apr 19, 2025Thermal infrared (TIR) images typically lack detailed features and have low contrast, making it challenging for conventional feature extraction models to capture discriminative target characteristics. As a result, trackers are often affected by interference from visually similar objects and are susceptible to tracking drift. To address these challenges, we propose a novel saliency-guided Siamese network tracker based on key fine-grained feature infor-mation. First, we introduce a fine-grained feature parallel learning convolu-tional block with a dual-stream architecture and convolutional kernels of varying sizes. This design captures essential global features from shallow layers, enhances feature diversity, and minimizes the loss of fine-grained in-formation typically encountered in residual connections. In addition, we propose a multi-layer fine-grained feature fusion module that uses bilinear matrix multiplication to effectively integrate features across both deep and shallow layers. Next, we introduce a Siamese residual refinement block that corrects saliency map prediction errors using residual learning. Combined with deep supervision, this mechanism progressively refines predictions, ap-plying supervision at each recursive step to ensure consistent improvements in accuracy. Finally, we present a saliency loss function to constrain the sali-ency predictions, directing the network to focus on highly discriminative fi-ne-grained features. Extensive experiment results demonstrate that the pro-posed tracker achieves the highest precision and success rates on the PTB-TIR and LSOTB-TIR benchmarks. It also achieves a top accuracy of 0.78 on the VOT-TIR 2015 benchmark and 0.75 on the VOT-TIR 2017 benchmark.
DCFG: Diverse Cross-Channel Fine-Grained Feature Learning and Progressive Fusion Siamese Tracker for Thermal Infrared Target Tracking
Apr 19, 2025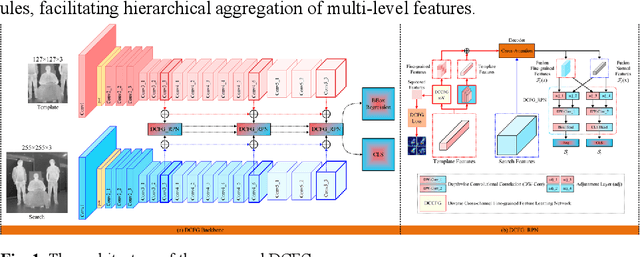

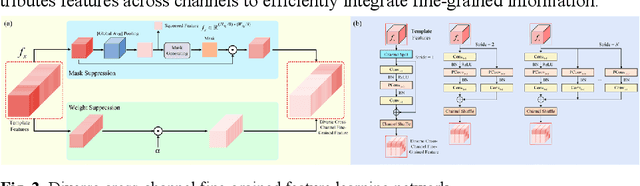

To address the challenge of capturing highly discriminative features in ther-mal infrared (TIR) tracking, we propose a novel Siamese tracker based on cross-channel fine-grained feature learning and progressive fusion. First, we introduce a cross-channel fine-grained feature learning network that employs masks and suppression coefficients to suppress dominant target features, en-abling the tracker to capture more detailed and subtle information. The net-work employs a channel rearrangement mechanism to enhance efficient in-formation flow, coupled with channel equalization to reduce parameter count. Additionally, we incorporate layer-by-layer combination units for ef-fective feature extraction and fusion, thereby minimizing parameter redun-dancy and computational complexity. The network further employs feature redirection and channel shuffling strategies to better integrate fine-grained details. Second, we propose a specialized cross-channel fine-grained loss function designed to guide feature groups toward distinct discriminative re-gions of the target, thus improving overall target representation. This loss function includes an inter-channel loss term that promotes orthogonality be-tween channels, maximizing feature diversity and facilitating finer detail capture. Extensive experiments demonstrate that our proposed tracker achieves the highest accuracy, scoring 0.81 on the VOT-TIR 2015 and 0.78 on the VOT-TIR 2017 benchmark, while also outperforming other methods across all evaluation metrics on the LSOTB-TIR and PTB-TIR benchmarks.
ISTD-YOLO: A Multi-Scale Lightweight High-Performance Infrared Small Target Detection Algorithm
Apr 19, 2025Aiming at the detection difficulties of infrared images such as complex background, low signal-to-noise ratio, small target size and weak brightness, a lightweight infrared small target detection algorithm ISTD-YOLO based on improved YOLOv7 was proposed. Firstly, the YOLOv7 network structure was lightweight reconstructed, and a three-scale lightweight network architecture was designed. Then, the ELAN-W module of the model neck network is replaced by VoV-GSCSP to reduce the computational cost and the complexity of the network structure. Secondly, a parameter-free attention mechanism was introduced into the neck network to enhance the relevance of local con-text information. Finally, the Normalized Wasserstein Distance (NWD) was used to optimize the commonly used IoU index to enhance the localization and detection accuracy of small targets. Experimental results show that compared with YOLOv7 and the current mainstream algorithms, ISTD-YOLO can effectively improve the detection effect, and all indicators are effectively improved, which can achieve high-quality detection of infrared small targets.
RAMCT: Novel Region-adaptive Multi-channel Tracker with Iterative Tikhonov Regularization for Thermal Infrared Tracking
Apr 19, 2025Correlation filter (CF)-based trackers have gained significant attention for their computational efficiency in thermal infrared (TIR) target tracking. However, ex-isting methods struggle with challenges such as low-resolution imagery, occlu-sion, background clutter, and target deformation, which severely impact tracking performance. To overcome these limitations, we propose RAMCT, a region-adaptive sparse correlation filter tracker that integrates multi-channel feature opti-mization with an adaptive regularization strategy. Firstly, we refine the CF learn-ing process by introducing a spatially adaptive binary mask, which enforces spar-sity in the target region while dynamically suppressing background interference. Secondly, we introduce generalized singular value decomposition (GSVD) and propose a novel GSVD-based region-adaptive iterative Tikhonov regularization method. This enables flexible and robust optimization across multiple feature channels, improving resilience to occlusion and background variations. Thirdly, we propose an online optimization strategy with dynamic discrepancy-based pa-rameter adjustment. This mechanism facilitates real time adaptation to target and background variations, thereby improving tracking accuracy and robustness. Ex-tensive experiments on LSOTB-TIR, PTB-TIR, VOT-TIR2015, and VOT-TIR2017 benchmarks demonstrate that RAMCT outperforms other state-of-the-art trackers in terms of accuracy and robustness.
ByteTransformer: A High-Performance Transformer Boosted for Variable-Length Inputs
Oct 06, 2022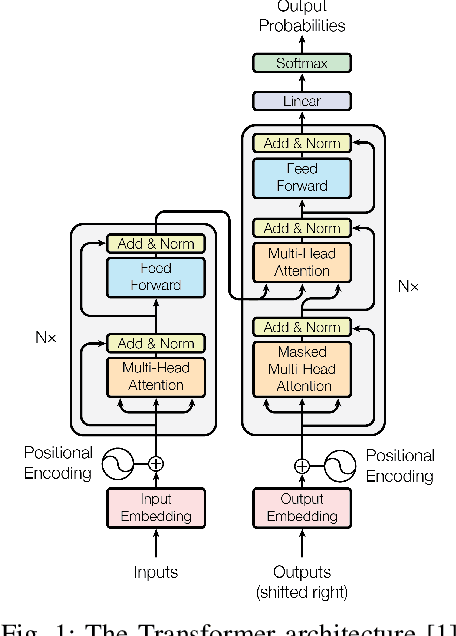
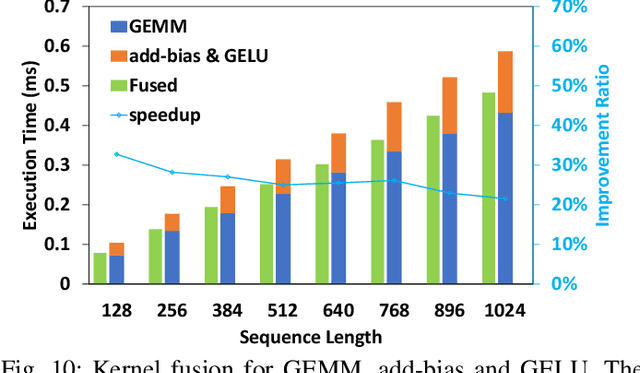
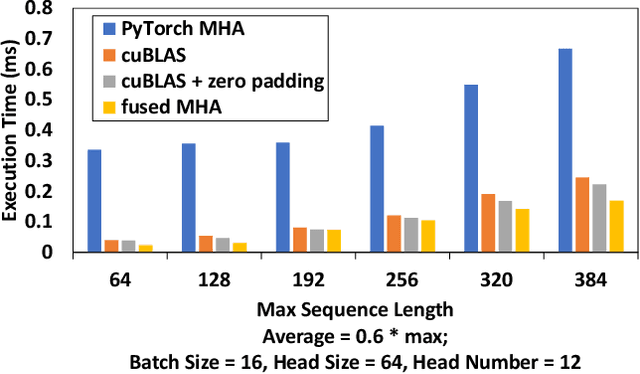
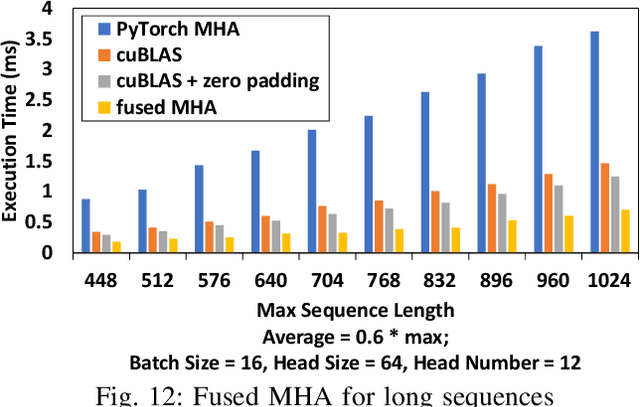
Transformer is the cornerstone model of Natural Language Processing (NLP) over the past decade. Despite its great success in Deep Learning (DL) applications, the increasingly growing parameter space required by transformer models boosts the demand on accelerating the performance of transformer models. In addition, NLP problems can commonly be faced with variable-length sequences since their word numbers can vary among sentences. Existing DL frameworks need to pad variable-length sequences to the maximal length, which, however, leads to significant memory and computational overhead. In this paper, we present ByteTransformer, a high-performance transformer boosted for variable-length inputs. We propose a zero padding algorithm that enables the whole transformer to be free from redundant computations on useless padded tokens. Besides the algorithmic level optimization, we provide architectural-aware optimizations for transformer functioning modules, especially the performance-critical algorithm, multi-head attention (MHA). Experimental results on an NVIDIA A100 GPU with variable-length sequence inputs validate that our fused MHA (FMHA) outperforms the standard PyTorch MHA by 6.13X. The end-to-end performance of ByteTransformer for a standard BERT transformer model surpasses the state-of-the-art Transformer frameworks, such as PyTorch JIT, TensorFlow XLA, Tencent TurboTransformer and NVIDIA FasterTransformer, by 87\%, 131\%, 138\% and 46\%, respectively.
Bolt: Bridging the Gap between Auto-tuners and Hardware-native Performance
Oct 25, 2021
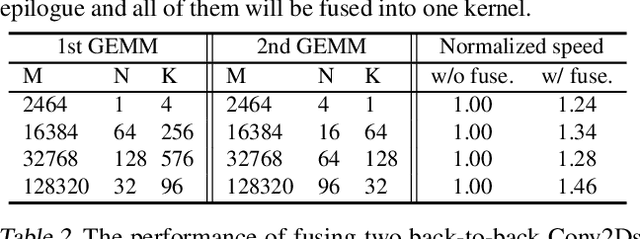
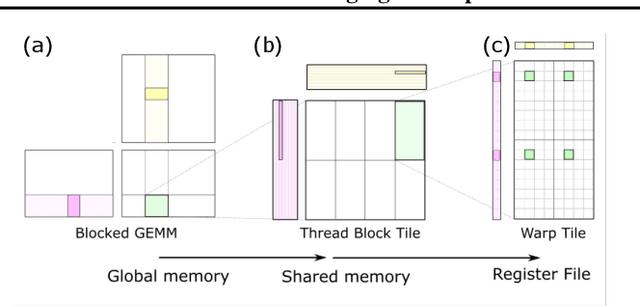

Today's auto-tuners (e.g., AutoTVM, Ansor) generate efficient tensor programs by navigating a large search space to identify effective implementations, but they do so with opaque hardware details. Thus, their performance could fall behind that of hardware-native libraries (e.g., cuBLAS, cuDNN), which are hand-optimized by device vendors to extract high performance. On the other hand, these vendor libraries have a fixed set of supported functions and lack the customization and automation support afforded by auto-tuners. Bolt is based on the recent trend that vendor libraries are increasingly modularized and reconfigurable via declarative control (e.g., CUTLASS). It enables a novel approach that bridges this gap and achieves the best of both worlds, via hardware-native templated search. Bolt provides new opportunities to rethink end-to-end tensor optimizations at the graph, operator, and model levels. Bolt demonstrates this concept by prototyping on a popular auto-tuner in TVM and a class of widely-used platforms (i.e., NVIDIA GPUs) -- both in large deployment in our production environment. Bolt improves the inference speed of common convolutional neural networks by 2.5x on average over the state of the art, and it auto-tunes these models within 20 minutes.