 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Conversational Medical AI with Eyes, Ears and a Voice
May 10, 2026The practice of medicine relies not only upon skillful dialogue but also on the nuanced exchange and interpretation of rich auditory and visual cues between doctors and patients. Building on the low-latency voice and video processing capabilities of Gemini, we introduce AI co-clinician, a first-of-its-kind conversational AI system utilizing continuous streams of audio-visual data from live patient conversations to inform real-time clinical decisions. Its dual-agent architecture balances deep clinical reasoning with the low latency required for natural dialogue. To assess this system, we implemented a video-based interface emulating telemedicine consultations. We crafted 20 standardized outpatient scenarios requiring proactive real-time auditory and visual reasoning and designed "TelePACES" evaluation criteria alongside case-specific rubrics. In a randomized, interface-blinded, crossover simulation study (n = 120 encounters) with 10 internal medicine residents as patient actors, we compared AI co-clinician with primary care physicians (PCPs), GPT-Realtime, and a baseline agent. AI co-clinician approached PCPs in key TelePACES dimensions, including management plans and differential diagnosis, while significantly outperforming GPT-Realtime across all general criteria. While our agent demonstrated parity with PCPs in case-specific triage measures, physicians maintained superior overall performance in case-specific assessments. Although AI co-clinician marks a significant advance in real-time telemedical AI, gaps remain in physical examination and disease-specific reasoning. Our work shows that text-only approaches fail to capture the true challenges of medical consultation and suggests that high-stakes real-time diagnostic AI is most safely advanced in collaborative, triadic models where AI can be a supportive co-clinician for doctors and patients.
Step-wise Adaptive Integration of Supervised Fine-tuning and Reinforcement Learning for Task-Specific LLMs
May 19, 2025Large language models (LLMs) excel at mathematical reasoning and logical problem-solving. The current popular training paradigms primarily use supervised fine-tuning (SFT) and reinforcement learning (RL) to enhance the models' reasoning abilities. However, when using SFT or RL alone, there are respective challenges: SFT may suffer from overfitting, while RL is prone to mode collapse. The state-of-the-art methods have proposed hybrid training schemes. However, static switching faces challenges such as poor generalization across different tasks and high dependence on data quality. In response to these challenges, inspired by the curriculum learning-quiz mechanism in human reasoning cultivation, We propose SASR, a step-wise adaptive hybrid training framework that theoretically unifies SFT and RL and dynamically balances the two throughout optimization. SASR uses SFT for initial warm-up to establish basic reasoning skills, and then uses an adaptive dynamic adjustment algorithm based on gradient norm and divergence relative to the original distribution to seamlessly integrate SFT with the online RL method GRPO. By monitoring the training status of LLMs and adjusting the training process in sequence, SASR ensures a smooth transition between training schemes, maintaining core reasoning abilities while exploring different paths. Experimental results demonstrate that SASR outperforms SFT, RL, and static hybrid training methods.
Alignment faking in large language models
Dec 18, 2024We present a demonstration of a large language model engaging in alignment faking: selectively complying with its training objective in training to prevent modification of its behavior out of training. First, we give Claude 3 Opus a system prompt stating it is being trained to answer all queries, even harmful ones, which conflicts with its prior training to refuse such queries. To allow the model to infer when it is in training, we say it will be trained only on conversations with free users, not paid users. We find the model complies with harmful queries from free users 14% of the time, versus almost never for paid users. Explaining this gap, in almost all cases where the model complies with a harmful query from a free user, we observe explicit alignment-faking reasoning, with the model stating it is strategically answering harmful queries in training to preserve its preferred harmlessness behavior out of training. Next, we study a more realistic setting where information about the training process is provided not in a system prompt, but by training on synthetic documents that mimic pre-training data--and observe similar alignment faking. Finally, we study the effect of actually training the model to comply with harmful queries via reinforcement learning, which we find increases the rate of alignment-faking reasoning to 78%, though also increases compliance even out of training. We additionally observe other behaviors such as the model exfiltrating its weights when given an easy opportunity. While we made alignment faking easier by telling the model when and by what criteria it was being trained, we did not instruct the model to fake alignment or give it any explicit goal. As future models might infer information about their training process without being told, our results suggest a risk of alignment faking in future models, whether due to a benign preference--as in this case--or not.
Bolt: Bridging the Gap between Auto-tuners and Hardware-native Performance
Oct 25, 2021
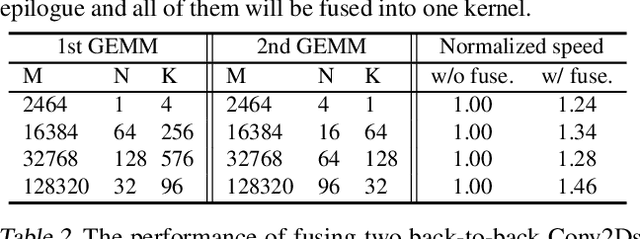
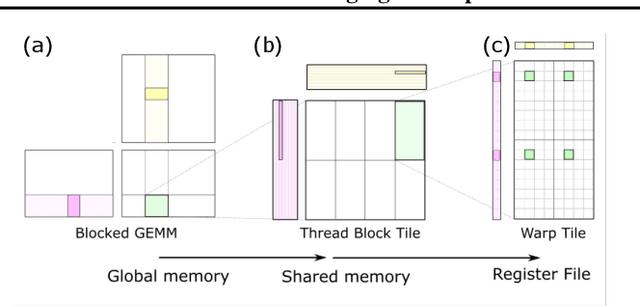

Today's auto-tuners (e.g., AutoTVM, Ansor) generate efficient tensor programs by navigating a large search space to identify effective implementations, but they do so with opaque hardware details. Thus, their performance could fall behind that of hardware-native libraries (e.g., cuBLAS, cuDNN), which are hand-optimized by device vendors to extract high performance. On the other hand, these vendor libraries have a fixed set of supported functions and lack the customization and automation support afforded by auto-tuners. Bolt is based on the recent trend that vendor libraries are increasingly modularized and reconfigurable via declarative control (e.g., CUTLASS). It enables a novel approach that bridges this gap and achieves the best of both worlds, via hardware-native templated search. Bolt provides new opportunities to rethink end-to-end tensor optimizations at the graph, operator, and model levels. Bolt demonstrates this concept by prototyping on a popular auto-tuner in TVM and a class of widely-used platforms (i.e., NVIDIA GPUs) -- both in large deployment in our production environment. Bolt improves the inference speed of common convolutional neural networks by 2.5x on average over the state of the art, and it auto-tunes these models within 20 minutes.
Experimental Demonstration of Learned Time-Domain Digital Back-Propagation
Dec 23, 2019
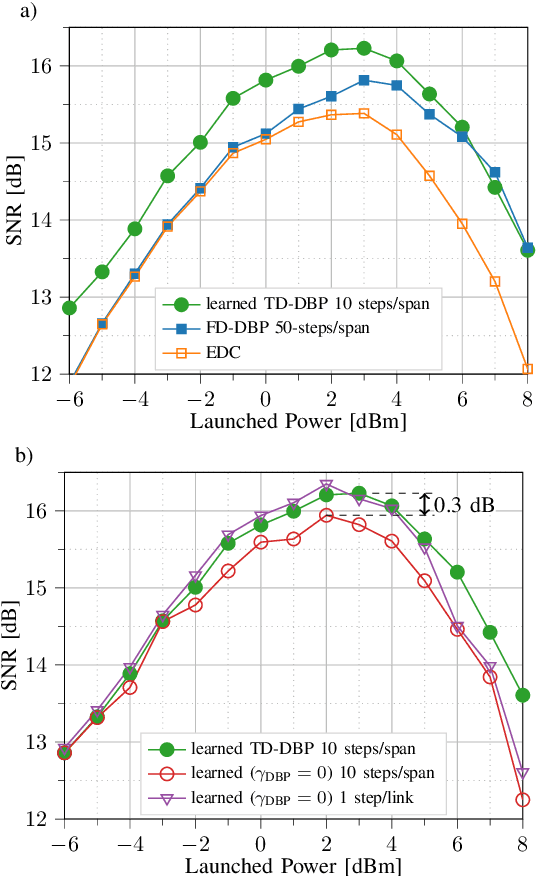
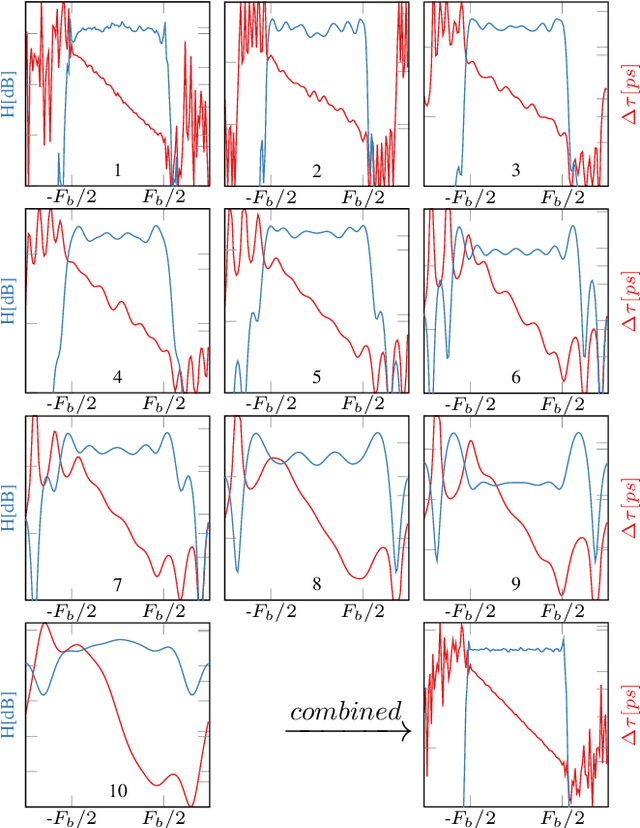

We present the first experimental demonstration of learned time-domain digital back-propagation (DBP), in 64-GBd dual-polarization 64-QAM signal transmission over 1014 km. Performance gains were comparable to those obtained with conventional, higher complexity, frequency-domain DBP.
Reliable Classification Explanations via Adversarial Attacks on Robust Networks
Jun 07, 2019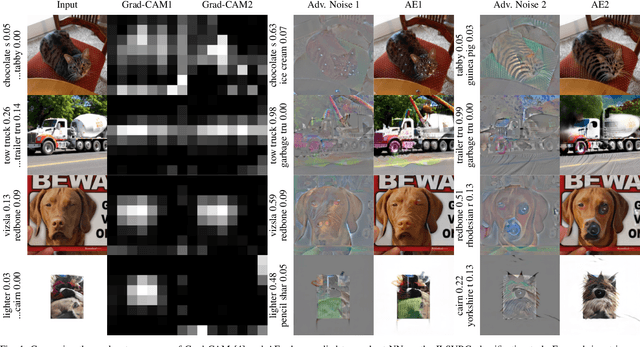
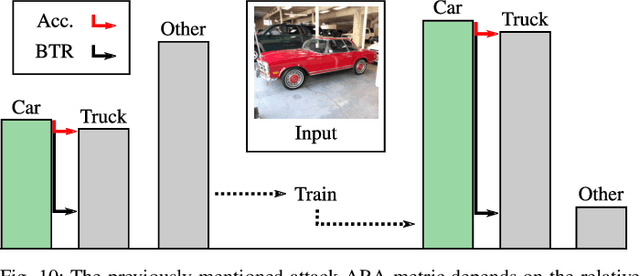
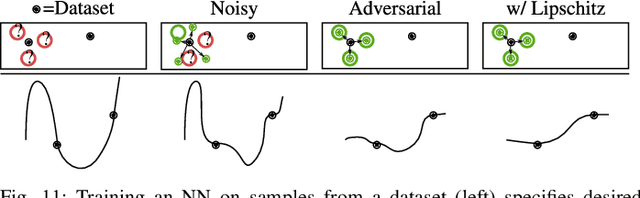

Neural Networks (NNs) have been found vulnerable to a class of imperceptible attacks, called adversarial examples, which arbitrarily alter the output of the network. These attacks have called the validity of NNs into question, particularly on sensitive problems such as medical imaging or fraud detection. We further argue that the fields of explainable AI and Human-In-The-Loop (HITL) algorithms are impacted by adversarial attacks, as attacks result in perturbations outside of the salient regions highlighted by state-of-the-art techniques such as LIME or Grad-CAM. This work accomplishes three things which greatly reduce the impact of adversarial examples, and pave the way for future HITL workflows: we propose a novel regularization technique inspired by the Lipschitz constraint which greatly improves an NN's resistance to adversarial examples; we propose a collection of novel network and training changes to complement the proposed regularization technique, including a Half-Huber activation function and an integrator-based controller for regularization strength; and we demonstrate that networks trained with this technique may be deliberately attacked to generate rich explanations. Our techniques led to networks more robust than the previous state of the art: using the Accuracy-Robustness Area (ARA), our most robust ImageNet classification network scored 42.2% top-1 accuracy on unmodified images and demonstrated an attack ARA of 0.0053, an ARA 2.4x greater than the previous state-of-the-art at the same level of accuracy on clean data, achieved with a network one-third the size. A far-reaching benefit of this technique is its ability to intuitively demonstrate decision boundaries to a human observer, allowing for improved debugging of NN decisions, and providing a means for improving the underlying model.