 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Classification Explanations via Adversarial Attacks on Robust Networks
Paper and Code
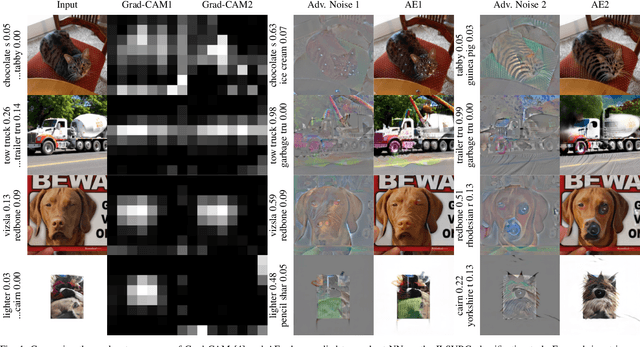
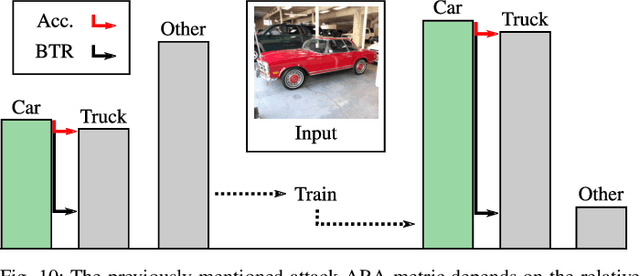
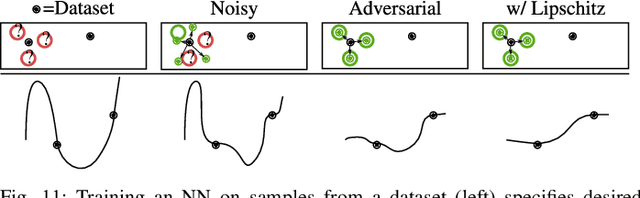

Neural Networks (NNs) have been found vulnerable to a class of imperceptible attacks, called adversarial examples, which arbitrarily alter the output of the network. These attacks have called the validity of NNs into question, particularly on sensitive problems such as medical imaging or fraud detection. We further argue that the fields of explainable AI and Human-In-The-Loop (HITL) algorithms are impacted by adversarial attacks, as attacks result in perturbations outside of the salient regions highlighted by state-of-the-art techniques such as LIME or Grad-CAM. This work accomplishes three things which greatly reduce the impact of adversarial examples, and pave the way for future HITL workflows: we propose a novel regularization technique inspired by the Lipschitz constraint which greatly improves an NN's resistance to adversarial examples; we propose a collection of novel network and training changes to complement the proposed regularization technique, including a Half-Huber activation function and an integrator-based controller for regularization strength; and we demonstrate that networks trained with this technique may be deliberately attacked to generate rich explanations. Our techniques led to networks more robust than the previous state of the art: using the Accuracy-Robustness Area (ARA), our most robust ImageNet classification network scored 42.2% top-1 accuracy on unmodified images and demonstrated an attack ARA of 0.0053, an ARA 2.4x greater than the previous state-of-the-art at the same level of accuracy on clean data, achieved with a network one-third the size. A far-reaching benefit of this technique is its ability to intuitively demonstrate decision boundaries to a human observer, allowing for improved debugging of NN decisions, and providing a means for improving the underlying model.