 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCriticality and Safety Margins for Reinforcement Learning
Sep 26, 2024State of the art reinforcement learning methods sometimes encounter unsafe situations. Identifying when these situations occur is of interest both for post-hoc analysis and during deployment, where it might be advantageous to call out to a human overseer for help. Efforts to gauge the criticality of different points in time have been developed, but their accuracy is not well established due to a lack of ground truth, and they are not designed to be easily interpretable by end users. Therefore, we seek to define a criticality framework with both a quantifiable ground truth and a clear significance to users. We introduce true criticality as the expected drop in reward when an agent deviates from its policy for n consecutive random actions. We also introduce the concept of proxy criticality, a low-overhead metric that has a statistically monotonic relationship to true criticality. Safety margins make these interpretable, when defined as the number of random actions for which performance loss will not exceed some tolerance with high confidence. We demonstrate this approach in several environment-agent combinations; for an A3C agent in an Atari Beamrider environment, the lowest 5% of safety margins contain 47% of agent losses; i.e., supervising only 5% of decisions could potentially prevent roughly half of an agent's errors. This criticality framework measures the potential impacts of bad decisions, even before those decisions are made, allowing for more effective debugging and oversight of autonomous agents.
Combining AI Control Systems and Human Decision Support via Robustness and Criticality
Jul 03, 2024AI-enabled capabilities are reaching the requisite level of maturity to be deployed in the real world, yet do not always make correct or safe decisions. One way of addressing these concerns is to leverage AI control systems alongside and in support of human decisions, relying on the AI control system in safe situations while calling on a human co-decider for critical situations. We extend a methodology for adversarial explanations (AE) to state-of-the-art reinforcement learning frameworks, including MuZero. Multiple improvements to the base agent architecture are proposed. We demonstrate how this technology has two applications: for intelligent decision tools and to enhance training / learning frameworks. In a decision support context, adversarial explanations help a user make the correct decision by highlighting those contextual factors that would need to change for a different AI-recommended decision. As another benefit of adversarial explanations, we show that the learned AI control system demonstrates robustness against adversarial tampering. Additionally, we supplement AE by introducing strategically similar autoencoders (SSAs) to help users identify and understand all salient factors being considered by the AI system. In a training / learning framework, this technology can improve both the AI's decisions and explanations through human interaction. Finally, to identify when AI decisions would most benefit from human oversight, we tie this combined system to our prior art on statistically verified analyses of the criticality of decisions at any point in time.
* 19 pages, 12 figures
Safety Margins for Reinforcement Learning
Jul 25, 2023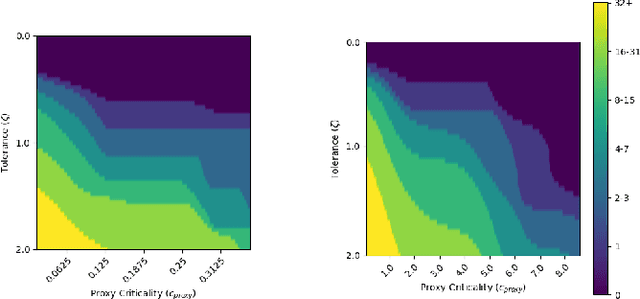
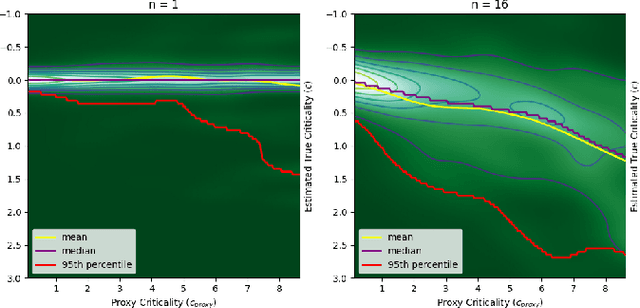
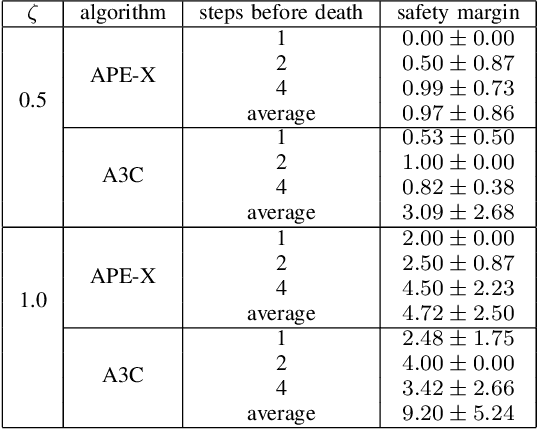
Any autonomous controller will be unsafe in some situations. The ability to quantitatively identify when these unsafe situations are about to occur is crucial for drawing timely human oversight in, e.g., freight transportation applications. In this work, we demonstrate that the true criticality of an agent's situation can be robustly defined as the mean reduction in reward given some number of random actions. Proxy criticality metrics that are computable in real-time (i.e., without actually simulating the effects of random actions) can be compared to the true criticality, and we show how to leverage these proxy metrics to generate safety margins, which directly tie the consequences of potentially incorrect actions to an anticipated loss in overall performance. We evaluate our approach on learned policies from APE-X and A3C within an Atari environment, and demonstrate how safety margins decrease as agents approach failure states. The integration of safety margins into programs for monitoring deployed agents allows for the real-time identification of potentially catastrophic situations.
LAGOON: An Analysis Tool for Open Source Communities
Jan 26, 2022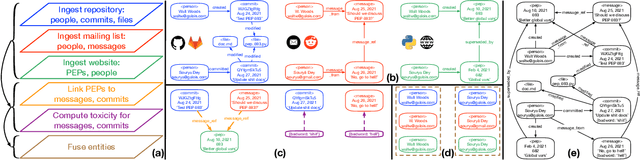
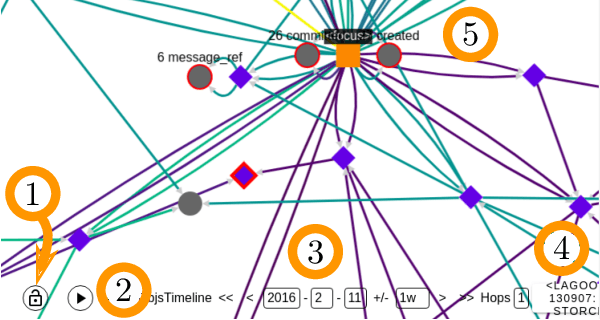

This paper presents LAGOON -- an open source platform for understanding the complex ecosystems of Open Source Software (OSS) communities. The platform currently utilizes spatiotemporal graphs to store and investigate the artifacts produced by these communities, and help analysts identify bad actors who might compromise an OSS project's security. LAGOON provides ingest of artifacts from several common sources, including source code repositories, issue trackers, mailing lists and scraping content from project websites. Ingestion utilizes a modular architecture, which supports incremental updates from data sources and provides a generic identity fusion process that can recognize the same community members across disparate accounts. A user interface is provided for visualization and exploration of an OSS project's complete sociotechnical graph. Scripts are provided for applying machine learning to identify patterns within the data. While current focus is on the identification of bad actors in the Python community, the platform's reusability makes it easily extensible with new data and analyses, paving the way for LAGOON to become a comprehensive means of assessing various OSS-based projects and their communities.
Extracting Grammars from a Neural Network Parser for Anomaly Detection in Unknown Formats
Jul 30, 2021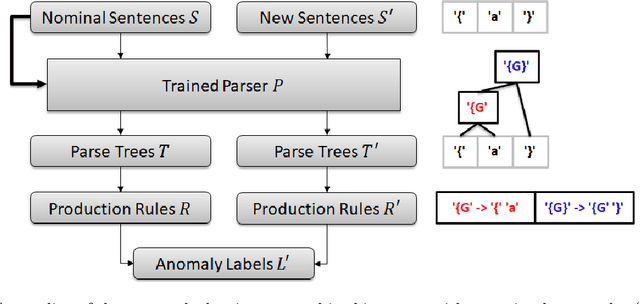

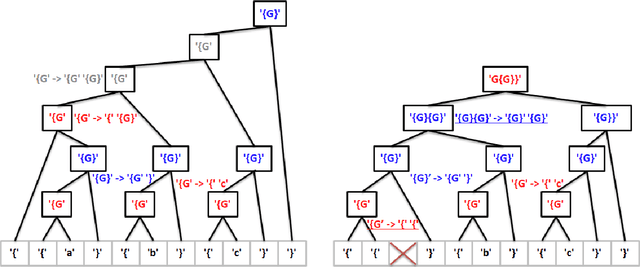
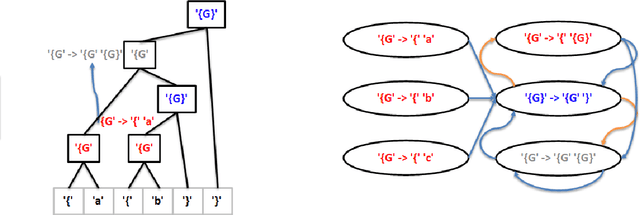
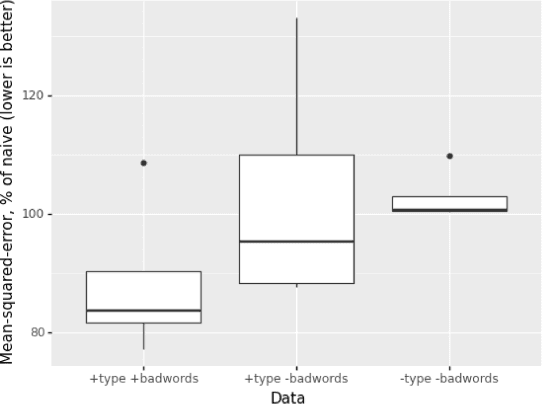
Reinforcement learning has recently shown promise as a technique for training an artificial neural network to parse sentences in some unknown format. A key aspect of this approach is that rather than explicitly inferring a grammar that describes the format, the neural network learns to perform various parsing actions (such as merging two tokens) over a corpus of sentences, with the goal of maximizing the total reward, which is roughly based on the estimated frequency of the resulting parse structures. This can allow the learning process to more easily explore different action choices, since a given choice may change the optimality of the parse (as expressed by the total reward), but will not result in the failure to parse a sentence. However, the approach also exhibits limitations: first, the neural network does not provide production rules for the grammar that it uses during parsing; second, because this neural network can successfully parse any sentence, it cannot be directly used to identify sentences that deviate from the format of the training sentences, i.e., that are anomalous. In this paper, we address these limitations by presenting procedures for extracting production rules from the neural network, and for using these rules to determine whether a given sentence is nominal or anomalous, when compared to structures observed within training data. In the latter case, an attempt is made to identify the location of the anomaly. Additionally, a two pass mechanism is presented for dealing with formats containing high-entropy information. We empirically evaluate the approach on artificial formats, demonstrating effectiveness, but also identifying limitations. By further improving parser learning, and leveraging rule extraction and anomaly detection, one might begin to understand common errors, either benign or malicious, in practical formats.
RL-GRIT: Reinforcement Learning for Grammar Inference
May 17, 2021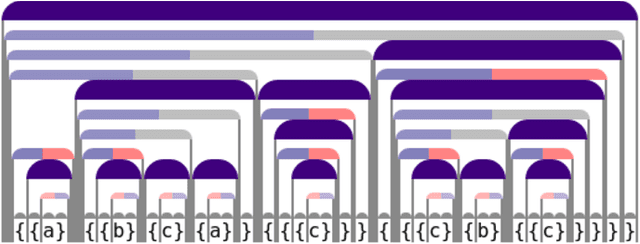
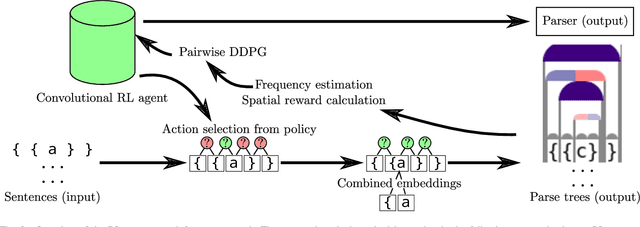
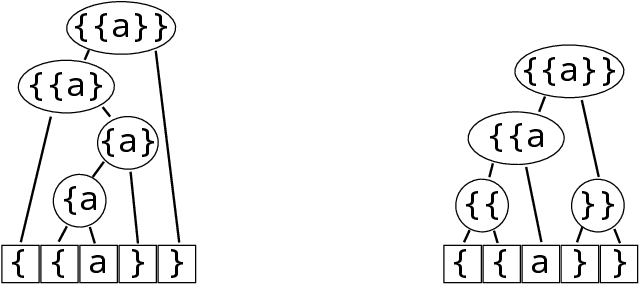
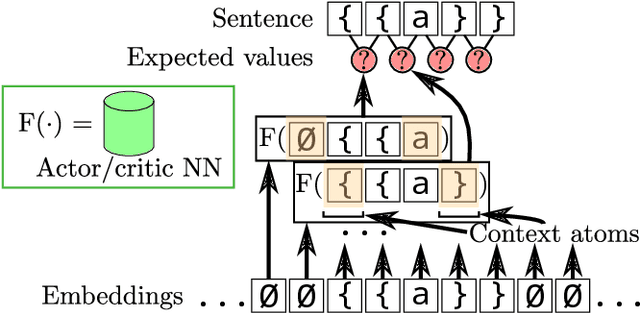
When working to understand usage of a data format, examples of the data format are often more representative than the format's specification. For example, two different applications might use very different JSON representations, or two PDF-writing applications might make use of very different areas of the PDF specification to realize the same rendered content. The complexity arising from these distinct origins can lead to large, difficult-to-understand attack surfaces, presenting a security concern when considering both exfiltration and data schizophrenia. Grammar inference can aid in describing the practical language generator behind examples of a data format. However, most grammar inference research focuses on natural language, not data formats, and fails to support crucial features such as type recursion. We propose a novel set of mechanisms for grammar inference, RL-GRIT, and apply them to understanding de facto data formats. After reviewing existing grammar inference solutions, it was determined that a new, more flexible scaffold could be found in Reinforcement Learning (RL). Within this work, we lay out the many algorithmic changes required to adapt RL from its traditional, sequential-time environment to the highly interdependent environment of parsing. The result is an algorithm which can demonstrably learn recursive control structures in simple data formats, and can extract meaningful structure from fragments of the PDF format. Whereas prior work in grammar inference focused on either regular languages or constituency parsing, we show that RL can be used to surpass the expressiveness of both classes, and offers a clear path to learning context-sensitive languages. The proposed algorithm can serve as a building block for understanding the ecosystems of de facto data formats.
Reliable Classification Explanations via Adversarial Attacks on Robust Networks
Jun 07, 2019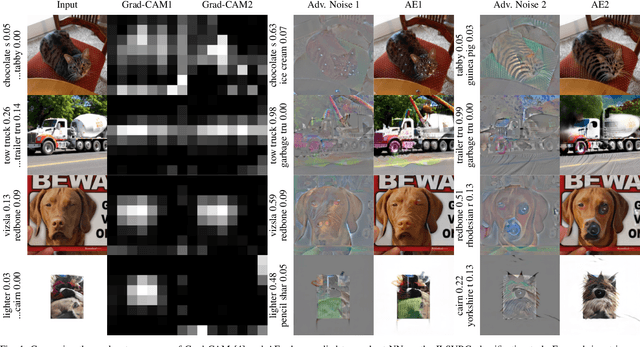
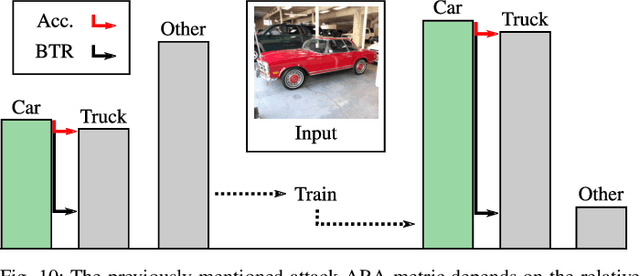
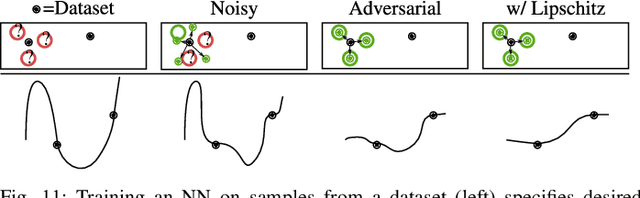

Neural Networks (NNs) have been found vulnerable to a class of imperceptible attacks, called adversarial examples, which arbitrarily alter the output of the network. These attacks have called the validity of NNs into question, particularly on sensitive problems such as medical imaging or fraud detection. We further argue that the fields of explainable AI and Human-In-The-Loop (HITL) algorithms are impacted by adversarial attacks, as attacks result in perturbations outside of the salient regions highlighted by state-of-the-art techniques such as LIME or Grad-CAM. This work accomplishes three things which greatly reduce the impact of adversarial examples, and pave the way for future HITL workflows: we propose a novel regularization technique inspired by the Lipschitz constraint which greatly improves an NN's resistance to adversarial examples; we propose a collection of novel network and training changes to complement the proposed regularization technique, including a Half-Huber activation function and an integrator-based controller for regularization strength; and we demonstrate that networks trained with this technique may be deliberately attacked to generate rich explanations. Our techniques led to networks more robust than the previous state of the art: using the Accuracy-Robustness Area (ARA), our most robust ImageNet classification network scored 42.2% top-1 accuracy on unmodified images and demonstrated an attack ARA of 0.0053, an ARA 2.4x greater than the previous state-of-the-art at the same level of accuracy on clean data, achieved with a network one-third the size. A far-reaching benefit of this technique is its ability to intuitively demonstrate decision boundaries to a human observer, allowing for improved debugging of NN decisions, and providing a means for improving the underlying model.