 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Grammars from a Neural Network Parser for Anomaly Detection in Unknown Formats
Paper and Code
Jul 30, 2021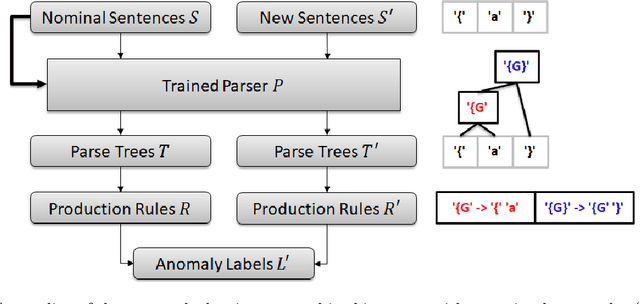

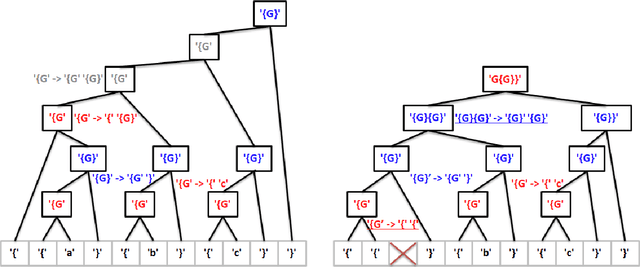
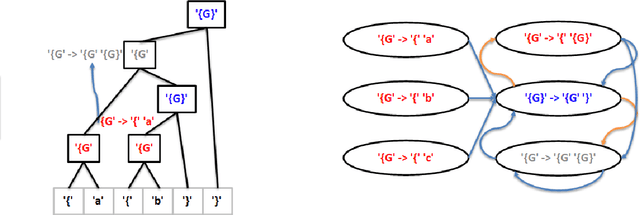
Reinforcement learning has recently shown promise as a technique for training an artificial neural network to parse sentences in some unknown format. A key aspect of this approach is that rather than explicitly inferring a grammar that describes the format, the neural network learns to perform various parsing actions (such as merging two tokens) over a corpus of sentences, with the goal of maximizing the total reward, which is roughly based on the estimated frequency of the resulting parse structures. This can allow the learning process to more easily explore different action choices, since a given choice may change the optimality of the parse (as expressed by the total reward), but will not result in the failure to parse a sentence. However, the approach also exhibits limitations: first, the neural network does not provide production rules for the grammar that it uses during parsing; second, because this neural network can successfully parse any sentence, it cannot be directly used to identify sentences that deviate from the format of the training sentences, i.e., that are anomalous. In this paper, we address these limitations by presenting procedures for extracting production rules from the neural network, and for using these rules to determine whether a given sentence is nominal or anomalous, when compared to structures observed within training data. In the latter case, an attempt is made to identify the location of the anomaly. Additionally, a two pass mechanism is presented for dealing with formats containing high-entropy information. We empirically evaluate the approach on artificial formats, demonstrating effectiveness, but also identifying limitations. By further improving parser learning, and leveraging rule extraction and anomaly detection, one might begin to understand common errors, either benign or malicious, in practical formats.