 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCriticality and Safety Margins for Reinforcement Learning
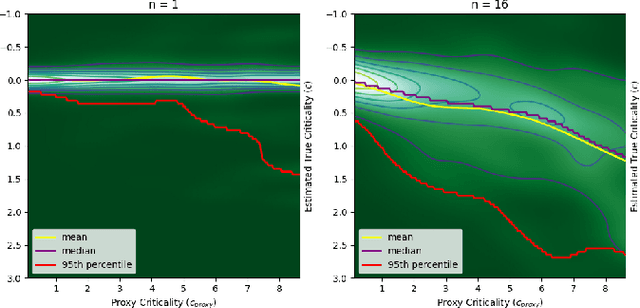
Sep 26, 2024State of the art reinforcement learning methods sometimes encounter unsafe situations. Identifying when these situations occur is of interest both for post-hoc analysis and during deployment, where it might be advantageous to call out to a human overseer for help. Efforts to gauge the criticality of different points in time have been developed, but their accuracy is not well established due to a lack of ground truth, and they are not designed to be easily interpretable by end users. Therefore, we seek to define a criticality framework with both a quantifiable ground truth and a clear significance to users. We introduce true criticality as the expected drop in reward when an agent deviates from its policy for n consecutive random actions. We also introduce the concept of proxy criticality, a low-overhead metric that has a statistically monotonic relationship to true criticality. Safety margins make these interpretable, when defined as the number of random actions for which performance loss will not exceed some tolerance with high confidence. We demonstrate this approach in several environment-agent combinations; for an A3C agent in an Atari Beamrider environment, the lowest 5% of safety margins contain 47% of agent losses; i.e., supervising only 5% of decisions could potentially prevent roughly half of an agent's errors. This criticality framework measures the potential impacts of bad decisions, even before those decisions are made, allowing for more effective debugging and oversight of autonomous agents.
Combining AI Control Systems and Human Decision Support via Robustness and Criticality
Jul 03, 2024AI-enabled capabilities are reaching the requisite level of maturity to be deployed in the real world, yet do not always make correct or safe decisions. One way of addressing these concerns is to leverage AI control systems alongside and in support of human decisions, relying on the AI control system in safe situations while calling on a human co-decider for critical situations. We extend a methodology for adversarial explanations (AE) to state-of-the-art reinforcement learning frameworks, including MuZero. Multiple improvements to the base agent architecture are proposed. We demonstrate how this technology has two applications: for intelligent decision tools and to enhance training / learning frameworks. In a decision support context, adversarial explanations help a user make the correct decision by highlighting those contextual factors that would need to change for a different AI-recommended decision. As another benefit of adversarial explanations, we show that the learned AI control system demonstrates robustness against adversarial tampering. Additionally, we supplement AE by introducing strategically similar autoencoders (SSAs) to help users identify and understand all salient factors being considered by the AI system. In a training / learning framework, this technology can improve both the AI's decisions and explanations through human interaction. Finally, to identify when AI decisions would most benefit from human oversight, we tie this combined system to our prior art on statistically verified analyses of the criticality of decisions at any point in time.
* 19 pages, 12 figures
Training Neural Networks with Internal State, Unconstrained Connectivity, and Discrete Activations
Dec 22, 2023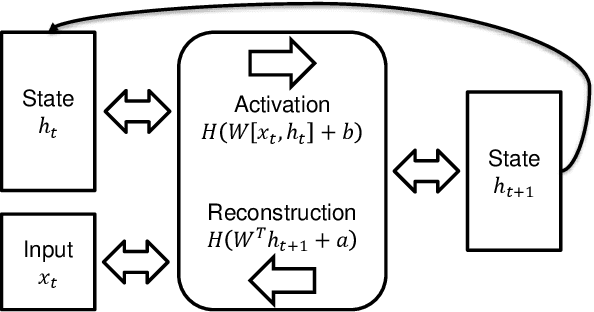
Today's most powerful machine learning approaches are typically designed to train stateless architectures with predefined layers and differentiable activation functions. While these approaches have led to unprecedented successes in areas such as natural language processing and image recognition, the trained models are also susceptible to making mistakes that a human would not. In this paper, we take the view that true intelligence may require the ability of a machine learning model to manage internal state, but that we have not yet discovered the most effective algorithms for training such models. We further postulate that such algorithms might not necessarily be based on gradient descent over a deep architecture, but rather, might work best with an architecture that has discrete activations and few initial topological constraints (such as multiple predefined layers). We present one attempt in our ongoing efforts to design such a training algorithm, applied to an architecture with binary activations and only a single matrix of weights, and show that it is able to form useful representations of natural language text, but is also limited in its ability to leverage large quantities of training data. We then provide ideas for improving the algorithm and for designing other training algorithms for similar architectures. Finally, we discuss potential benefits that could be gained if an effective training algorithm is found, and suggest experiments for evaluating whether these benefits exist in practice.
Safety Margins for Reinforcement Learning
Jul 25, 2023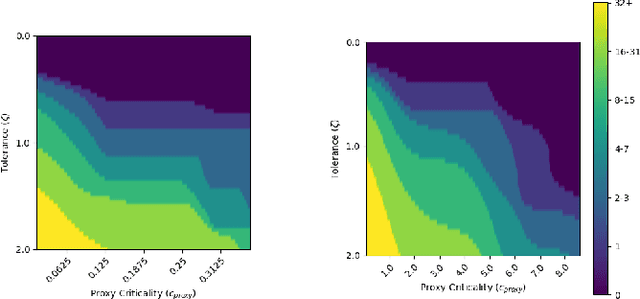
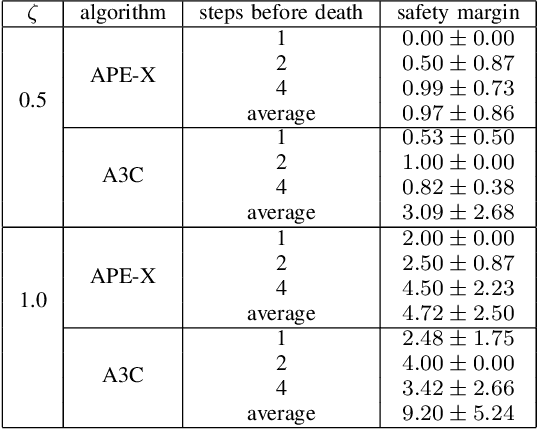
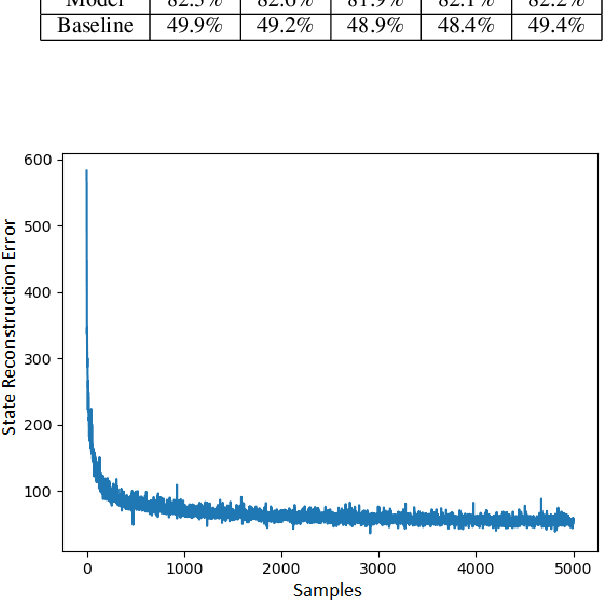
Any autonomous controller will be unsafe in some situations. The ability to quantitatively identify when these unsafe situations are about to occur is crucial for drawing timely human oversight in, e.g., freight transportation applications. In this work, we demonstrate that the true criticality of an agent's situation can be robustly defined as the mean reduction in reward given some number of random actions. Proxy criticality metrics that are computable in real-time (i.e., without actually simulating the effects of random actions) can be compared to the true criticality, and we show how to leverage these proxy metrics to generate safety margins, which directly tie the consequences of potentially incorrect actions to an anticipated loss in overall performance. We evaluate our approach on learned policies from APE-X and A3C within an Atari environment, and demonstrate how safety margins decrease as agents approach failure states. The integration of safety margins into programs for monitoring deployed agents allows for the real-time identification of potentially catastrophic situations.
Extracting Grammars from a Neural Network Parser for Anomaly Detection in Unknown Formats
Jul 30, 2021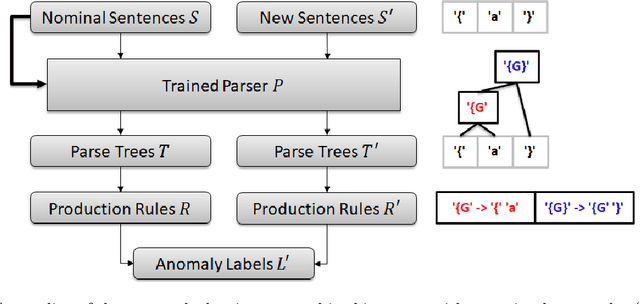

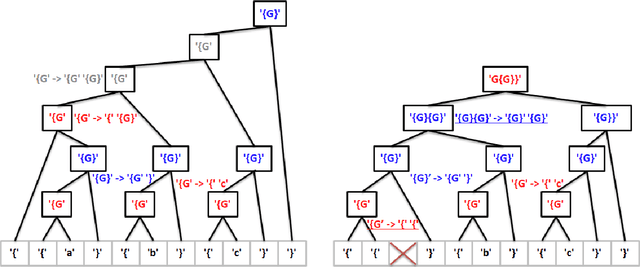
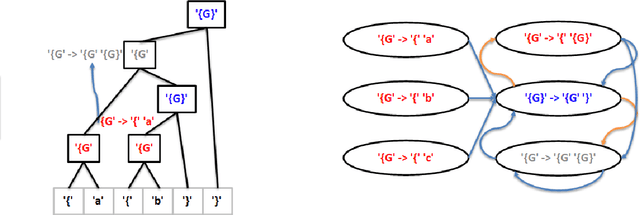
Reinforcement learning has recently shown promise as a technique for training an artificial neural network to parse sentences in some unknown format. A key aspect of this approach is that rather than explicitly inferring a grammar that describes the format, the neural network learns to perform various parsing actions (such as merging two tokens) over a corpus of sentences, with the goal of maximizing the total reward, which is roughly based on the estimated frequency of the resulting parse structures. This can allow the learning process to more easily explore different action choices, since a given choice may change the optimality of the parse (as expressed by the total reward), but will not result in the failure to parse a sentence. However, the approach also exhibits limitations: first, the neural network does not provide production rules for the grammar that it uses during parsing; second, because this neural network can successfully parse any sentence, it cannot be directly used to identify sentences that deviate from the format of the training sentences, i.e., that are anomalous. In this paper, we address these limitations by presenting procedures for extracting production rules from the neural network, and for using these rules to determine whether a given sentence is nominal or anomalous, when compared to structures observed within training data. In the latter case, an attempt is made to identify the location of the anomaly. Additionally, a two pass mechanism is presented for dealing with formats containing high-entropy information. We empirically evaluate the approach on artificial formats, demonstrating effectiveness, but also identifying limitations. By further improving parser learning, and leveraging rule extraction and anomaly detection, one might begin to understand common errors, either benign or malicious, in practical formats.