 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMAC+: Embodied Multimodal Agent for Collaborative Planning with VLM+LLM
May 26, 2025Although LLMs demonstrate proficiency in several text-based reasoning and planning tasks, their implementation in robotics control is constrained by significant deficiencies: (1) LLM agents are designed to work mainly with textual inputs rather than visual conditions; (2) Current multimodal agents treat LLMs as static planners, which separates their reasoning from environment dynamics, resulting in actions that do not take domain-specific knowledge into account; and (3) LLMs are not designed to learn from visual interactions, which makes it harder for them to make better policies for specific domains. In this paper, we introduce EMAC+, an Embodied Multimodal Agent that collaboratively integrates LLM and VLM via a bidirectional training paradigm. Unlike existing methods, EMAC+ dynamically refines high-level textual plans generated by an LLM using real-time feedback from a VLM executing low-level visual control tasks. We address critical limitations of previous models by enabling the LLM to internalize visual environment dynamics directly through interactive experience, rather than relying solely on static symbolic mappings. Extensive experimental evaluations on ALFWorld and RT-1 benchmarks demonstrate that EMAC+ achieves superior task performance, robustness against noisy observations, and efficient learning. We also conduct thorough ablation studies and provide detailed analyses of success and failure cases.
Near-Optimal Sample Complexity for Iterated CVaR Reinforcement Learning with a Generative Model
Mar 11, 2025In this work, we study the sample complexity problem of risk-sensitive Reinforcement Learning (RL) with a generative model, where we aim to maximize the Conditional Value at Risk (CVaR) with risk tolerance level $\tau$ at each step, named Iterated CVaR. %We consider the sample complexity of obtaining an $\epsilon$-optimal policy in an infinite horizon discounted MDP, given access to a generative model. % We first build a connection between Iterated CVaR RL with $(s, a)$-rectangular distributional robust RL with the specific uncertainty set for CVaR. We develop nearly matching upper and lower bounds on the sample complexity for this problem. Specifically, we first prove that a value iteration-based algorithm, ICVaR-VI, achieves an $\epsilon$-optimal policy with at most $\tilde{{O}}\left(\frac{SA}{(1-\gamma)^4\tau^2\epsilon^2}\right)$ samples, where $\gamma$ is the discount factor, and $S, A$ are the sizes of the state and action spaces. Furthermore, if $\tau \geq \gamma$, then the sample complexity can be further improved to $\tilde{{O}}\left( \frac{SA}{(1-\gamma)^3\epsilon^2} \right)$. We further show a minimax lower bound of ${\tilde{{O}}}\left(\frac{(1-\gamma \tau)SA}{(1-\gamma)^4\tau\epsilon^2}\right)$. For a constant risk level $0<\tau\leq 1$, our upper and lower bounds match with each other, demonstrating the tightness and optimality of our analyses. We also investigate a limiting case with a small risk level $\tau$, called Worst-Path RL, where the objective is to maximize the minimum possible cumulative reward. We develop matching upper and lower bounds of $\tilde{{O}}\left(\frac{SA}{p_{\min}}\right)$, where $p_{\min}$ denotes the minimum non-zero reaching probability of the transition kernel.
Why the Agent Made that Decision: Explaining Deep Reinforcement Learning with Vision Masks
Nov 25, 2024



Due to the inherent lack of transparency in deep neural networks, it is challenging for deep reinforcement learning (DRL) agents to gain trust and acceptance from users, especially in safety-critical applications such as medical diagnosis and military operations. Existing methods for explaining an agent's decision either require to retrain the agent using models that support explanation generation or rely on perturbation-based techniques to reveal the significance of different input features in the decision making process. However, retraining the agent may compromise its integrity and performance, while perturbation-based methods have limited performance and lack knowledge accumulation or learning capabilities. Moreover, since each perturbation is performed independently, the joint state of the perturbed inputs may not be physically meaningful. To address these challenges, we introduce $\textbf{VisionMask}$, a standalone explanation model trained end-to-end to identify the most critical regions in the agent's visual input that can explain its actions. VisionMask is trained in a self-supervised manner without relying on human-generated labels. Importantly, its training does not alter the agent model, hence preserving the agent's performance and integrity. We evaluate VisionMask on Super Mario Bros (SMB) and three Atari games. Compared to existing methods, VisionMask achieves a 14.9% higher insertion accuracy and a 30.08% higher F1-Score in reproducing original actions from the selected visual explanations. We also present examples illustrating how VisionMask can be used for counterfactual analysis.
Criticality and Safety Margins for Reinforcement Learning
Sep 26, 2024State of the art reinforcement learning methods sometimes encounter unsafe situations. Identifying when these situations occur is of interest both for post-hoc analysis and during deployment, where it might be advantageous to call out to a human overseer for help. Efforts to gauge the criticality of different points in time have been developed, but their accuracy is not well established due to a lack of ground truth, and they are not designed to be easily interpretable by end users. Therefore, we seek to define a criticality framework with both a quantifiable ground truth and a clear significance to users. We introduce true criticality as the expected drop in reward when an agent deviates from its policy for n consecutive random actions. We also introduce the concept of proxy criticality, a low-overhead metric that has a statistically monotonic relationship to true criticality. Safety margins make these interpretable, when defined as the number of random actions for which performance loss will not exceed some tolerance with high confidence. We demonstrate this approach in several environment-agent combinations; for an A3C agent in an Atari Beamrider environment, the lowest 5% of safety margins contain 47% of agent losses; i.e., supervising only 5% of decisions could potentially prevent roughly half of an agent's errors. This criticality framework measures the potential impacts of bad decisions, even before those decisions are made, allowing for more effective debugging and oversight of autonomous agents.
Combining AI Control Systems and Human Decision Support via Robustness and Criticality
Jul 03, 2024AI-enabled capabilities are reaching the requisite level of maturity to be deployed in the real world, yet do not always make correct or safe decisions. One way of addressing these concerns is to leverage AI control systems alongside and in support of human decisions, relying on the AI control system in safe situations while calling on a human co-decider for critical situations. We extend a methodology for adversarial explanations (AE) to state-of-the-art reinforcement learning frameworks, including MuZero. Multiple improvements to the base agent architecture are proposed. We demonstrate how this technology has two applications: for intelligent decision tools and to enhance training / learning frameworks. In a decision support context, adversarial explanations help a user make the correct decision by highlighting those contextual factors that would need to change for a different AI-recommended decision. As another benefit of adversarial explanations, we show that the learned AI control system demonstrates robustness against adversarial tampering. Additionally, we supplement AE by introducing strategically similar autoencoders (SSAs) to help users identify and understand all salient factors being considered by the AI system. In a training / learning framework, this technology can improve both the AI's decisions and explanations through human interaction. Finally, to identify when AI decisions would most benefit from human oversight, we tie this combined system to our prior art on statistically verified analyses of the criticality of decisions at any point in time.
* 19 pages, 12 figures
Multi-agent Cooperative Games Using Belief Map Assisted Training
Jun 27, 2024



In a multi-agent system, agents share their local observations to gain global situational awareness for decision making and collaboration using a message passing system. When to send a message, how to encode a message, and how to leverage the received messages directly affect the effectiveness of the collaboration among agents. When training a multi-agent cooperative game using reinforcement learning (RL), the message passing system needs to be optimized together with the agent policies. This consequently increases the model's complexity and poses significant challenges to the convergence and performance of learning. To address this issue, we propose the Belief-map Assisted Multi-agent System (BAMS), which leverages a neuro-symbolic belief map to enhance training. The belief map decodes the agent's hidden state to provide a symbolic representation of the agent's understanding of the environment and other agent's status. The simplicity of symbolic representation allows the gathering and comparison of the ground truth information with the belief, which provides an additional channel of feedback for the learning. Compared to the sporadic and delayed feedback coming from the reward in RL, the feedback from the belief map is more consistent and reliable. Agents using BAMS can learn a more effective message passing network to better understand each other, resulting in better performance in a cooperative predator and prey game with varying levels of map complexity and compare it to previous multi-agent message passing models. The simulation results showed that BAMS reduced training epochs by 66\%, and agents who apply the BAMS model completed the game with 34.62\% fewer steps on average.
REVEAL-IT: REinforcement learning with Visibility of Evolving Agent poLicy for InTerpretability
Jun 20, 2024Understanding the agent's learning process, particularly the factors that contribute to its success or failure post-training, is crucial for comprehending the rationale behind the agent's decision-making process. Prior methods clarify the learning process by creating a structural causal model (SCM) or visually representing the distribution of value functions. Nevertheless, these approaches have constraints as they exclusively function in 2D-environments or with uncomplicated transition dynamics. Understanding the agent's learning process in complicated environments or tasks is more challenging. In this paper, we propose REVEAL-IT, a novel framework for explaining the learning process of an agent in complex environments. Initially, we visualize the policy structure and the agent's learning process for various training tasks. By visualizing these findings, we can understand how much a particular training task or stage affects the agent's performance in test. Then, a GNN-based explainer learns to highlight the most important section of the policy, providing a more clear and robust explanation of the agent's learning process. The experiments demonstrate that explanations derived from this framework can effectively help in the optimization of the
CODEX: A Cluster-Based Method for Explainable Reinforcement Learning
Dec 07, 2023Despite the impressive feats demonstrated by Reinforcement Learning (RL), these algorithms have seen little adoption in high-risk, real-world applications due to current difficulties in explaining RL agent actions and building user trust. We present Counterfactual Demonstrations for Explanation (CODEX), a method that incorporates semantic clustering, which can effectively summarize RL agent behavior in the state-action space. Experimentation on the MiniGrid and StarCraft II gaming environments reveals the semantic clusters retain temporal as well as entity information, which is reflected in the constructed summary of agent behavior. Furthermore, clustering the discrete+continuous game-state latent representations identifies the most crucial episodic events, demonstrating a relationship between the latent and semantic spaces. This work contributes to the growing body of work that strives to unlock the power of RL for widespread use by leveraging and extending techniques from Natural Language Processing.
Safety Margins for Reinforcement Learning
Jul 25, 2023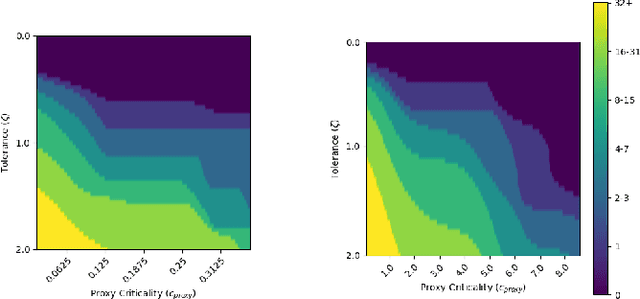
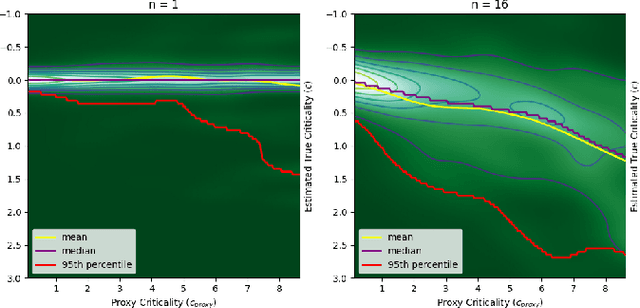
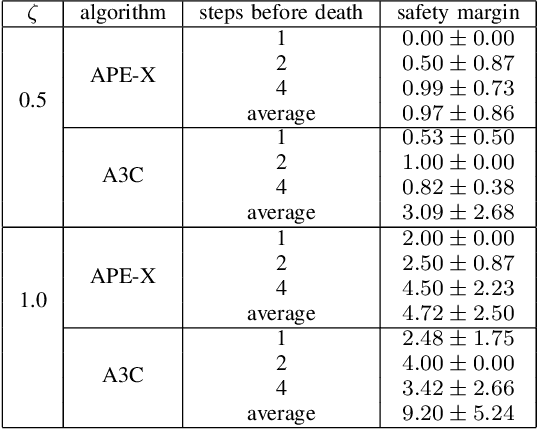
Any autonomous controller will be unsafe in some situations. The ability to quantitatively identify when these unsafe situations are about to occur is crucial for drawing timely human oversight in, e.g., freight transportation applications. In this work, we demonstrate that the true criticality of an agent's situation can be robustly defined as the mean reduction in reward given some number of random actions. Proxy criticality metrics that are computable in real-time (i.e., without actually simulating the effects of random actions) can be compared to the true criticality, and we show how to leverage these proxy metrics to generate safety margins, which directly tie the consequences of potentially incorrect actions to an anticipated loss in overall performance. We evaluate our approach on learned policies from APE-X and A3C within an Atari environment, and demonstrate how safety margins decrease as agents approach failure states. The integration of safety margins into programs for monitoring deployed agents allows for the real-time identification of potentially catastrophic situations.