 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience Constrained Hierarchical Federated Reinforcement Learning for Large-scale UAV Teams in Hazardous Environments
May 04, 2026Conventional federated learning assumes that greater learner participation improves training performance, by leveraging abundant, independently generated local data. However, in federated reinforcement learning (FRL) for unmanned aerial vehicle (UAV) teams in hazardous environments where experience generation is severely constrained by safety considerations, energy limitations, and mission duration, this assumption may break. This work introduces Experience-Constrained Hierarchical Federated Reinforcement Learning (EC-HFRL), a framework in which clusters act as federated learning agents, while multiple intra-cluster learners represent parallel learning resources that reuse a shared experience pool. We show that increasing participation does not necessarily improve learning performance. Instead, learning performance is strongly associated with experience reuse strategy and the dominance of key analytically identified gradient transition experiences within a cluster. In particular, minibatch size primarily determines effective replay exposure, while higher intra-cluster participation increases reuse level. Empirical results demonstrate that the performance regimes are strongly associated with the structure of the learning signal, rather than federated aggregation effects, clarifying the limited and secondary role of learner participation in experience-constrained FRL.
MapATM: Enhancing HD Map Construction through Actor Trajectory Modeling
Apr 13, 2026High-definition (HD) mapping tasks, which perform lane detections and predictions, are extremely challenging due to non-ideal conditions such as view occlusions, distant lane visibility, and adverse weather conditions. Those conditions often result in compromised lane detection accuracy and reduced reliability within autonomous driving systems. To address these challenges, we introduce MapATM, a novel deep neural network that effectively leverages historical actor trajectory information to improve lane detection accuracy, where actors refer to moving vehicles. By utilizing actor trajectories as structural priors for road geometry, MapATM achieves substantial performance enhancements, notably increasing AP by 4.6 for lane dividers and mAP by 2.6 on the challenging NuScenes dataset, representing relative improvements of 10.1% and 6.1%, respectively, compared to strong baseline methods. Extensive qualitative evaluations further demonstrate MapATM's capability to consistently maintain stable and robust map reconstruction across diverse and complex driving scenarios, underscoring its practical value for autonomous driving applications.
ACL-QL: Adaptive Conservative Level in Q-Learning for Offline Reinforcement Learning
Dec 22, 2024Offline Reinforcement Learning (RL), which operates solely on static datasets without further interactions with the environment, provides an appealing alternative to learning a safe and promising control policy. The prevailing methods typically learn a conservative policy to mitigate the problem of Q-value overestimation, but it is prone to overdo it, leading to an overly conservative policy. Moreover, they optimize all samples equally with fixed constraints, lacking the nuanced ability to control conservative levels in a fine-grained manner. Consequently, this limitation results in a performance decline. To address the above two challenges in a united way, we propose a framework, Adaptive Conservative Level in Q-Learning (ACL-QL), which limits the Q-values in a mild range and enables adaptive control on the conservative level over each state-action pair, i.e., lifting the Q-values more for good transitions and less for bad transitions. We theoretically analyze the conditions under which the conservative level of the learned Q-function can be limited in a mild range and how to optimize each transition adaptively. Motivated by the theoretical analysis, we propose a novel algorithm, ACL-QL, which uses two learnable adaptive weight functions to control the conservative level over each transition. Subsequently, we design a monotonicity loss and surrogate losses to train the adaptive weight functions, Q-function, and policy network alternatively. We evaluate ACL-QL on the commonly used D4RL benchmark and conduct extensive ablation studies to illustrate the effectiveness and state-of-the-art performance compared to existing offline DRL baselines.
LVP-CLIP:Revisiting CLIP for Continual Learning with Label Vector Pool
Dec 08, 2024



Continual learning aims to update a model so that it can sequentially learn new tasks without forgetting previously acquired knowledge. Recent continual learning approaches often leverage the vision-language model CLIP for its high-dimensional feature space and cross-modality feature matching. Traditional CLIP-based classification methods identify the most similar text label for a test image by comparing their embeddings. However, these methods are sensitive to the quality of text phrases and less effective for classes lacking meaningful text labels. In this work, we rethink CLIP-based continual learning and introduce the concept of Label Vector Pool (LVP). LVP replaces text labels with training images as similarity references, eliminating the need for ideal text descriptions. We present three variations of LVP and evaluate their performance on class and domain incremental learning tasks. Leveraging CLIP's high dimensional feature space, LVP learning algorithms are task-order invariant. The new knowledge does not modify the old knowledge, hence, there is minimum forgetting. Different tasks can be learned independently and in parallel with low computational and memory demands. Experimental results show that proposed LVP-based methods outperform the current state-of-the-art baseline by a significant margin of 40.7%.
Why the Agent Made that Decision: Explaining Deep Reinforcement Learning with Vision Masks
Nov 25, 2024



Due to the inherent lack of transparency in deep neural networks, it is challenging for deep reinforcement learning (DRL) agents to gain trust and acceptance from users, especially in safety-critical applications such as medical diagnosis and military operations. Existing methods for explaining an agent's decision either require to retrain the agent using models that support explanation generation or rely on perturbation-based techniques to reveal the significance of different input features in the decision making process. However, retraining the agent may compromise its integrity and performance, while perturbation-based methods have limited performance and lack knowledge accumulation or learning capabilities. Moreover, since each perturbation is performed independently, the joint state of the perturbed inputs may not be physically meaningful. To address these challenges, we introduce $\textbf{VisionMask}$, a standalone explanation model trained end-to-end to identify the most critical regions in the agent's visual input that can explain its actions. VisionMask is trained in a self-supervised manner without relying on human-generated labels. Importantly, its training does not alter the agent model, hence preserving the agent's performance and integrity. We evaluate VisionMask on Super Mario Bros (SMB) and three Atari games. Compared to existing methods, VisionMask achieves a 14.9% higher insertion accuracy and a 30.08% higher F1-Score in reproducing original actions from the selected visual explanations. We also present examples illustrating how VisionMask can be used for counterfactual analysis.
Discrete Policy: Learning Disentangled Action Space for Multi-Task Robotic Manipulation
Sep 27, 2024



Learning visuomotor policy for multi-task robotic manipulation has been a long-standing challenge for the robotics community. The difficulty lies in the diversity of action space: typically, a goal can be accomplished in multiple ways, resulting in a multimodal action distribution for a single task. The complexity of action distribution escalates as the number of tasks increases. In this work, we propose \textbf{Discrete Policy}, a robot learning method for training universal agents capable of multi-task manipulation skills. Discrete Policy employs vector quantization to map action sequences into a discrete latent space, facilitating the learning of task-specific codes. These codes are then reconstructed into the action space conditioned on observations and language instruction. We evaluate our method on both simulation and multiple real-world embodiments, including both single-arm and bimanual robot settings. We demonstrate that our proposed Discrete Policy outperforms a well-established Diffusion Policy baseline and many state-of-the-art approaches, including ACT, Octo, and OpenVLA. For example, in a real-world multi-task training setting with five tasks, Discrete Policy achieves an average success rate that is 26\% higher than Diffusion Policy and 15\% higher than OpenVLA. As the number of tasks increases to 12, the performance gap between Discrete Policy and Diffusion Policy widens to 32.5\%, further showcasing the advantages of our approach. Our work empirically demonstrates that learning multi-task policies within the latent space is a vital step toward achieving general-purpose agents.
Multi-agent Cooperative Games Using Belief Map Assisted Training
Jun 27, 2024



In a multi-agent system, agents share their local observations to gain global situational awareness for decision making and collaboration using a message passing system. When to send a message, how to encode a message, and how to leverage the received messages directly affect the effectiveness of the collaboration among agents. When training a multi-agent cooperative game using reinforcement learning (RL), the message passing system needs to be optimized together with the agent policies. This consequently increases the model's complexity and poses significant challenges to the convergence and performance of learning. To address this issue, we propose the Belief-map Assisted Multi-agent System (BAMS), which leverages a neuro-symbolic belief map to enhance training. The belief map decodes the agent's hidden state to provide a symbolic representation of the agent's understanding of the environment and other agent's status. The simplicity of symbolic representation allows the gathering and comparison of the ground truth information with the belief, which provides an additional channel of feedback for the learning. Compared to the sporadic and delayed feedback coming from the reward in RL, the feedback from the belief map is more consistent and reliable. Agents using BAMS can learn a more effective message passing network to better understand each other, resulting in better performance in a cooperative predator and prey game with varying levels of map complexity and compare it to previous multi-agent message passing models. The simulation results showed that BAMS reduced training epochs by 66\%, and agents who apply the BAMS model completed the game with 34.62\% fewer steps on average.
Predictive Temporal Attention on Event-based Video Stream for Energy-efficient Situation Awareness
Feb 14, 2024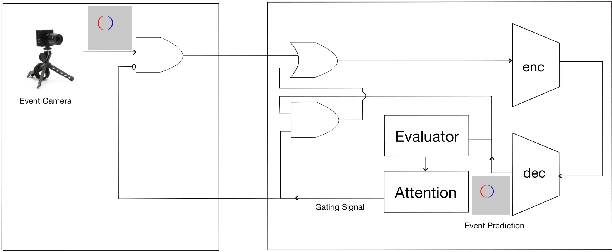
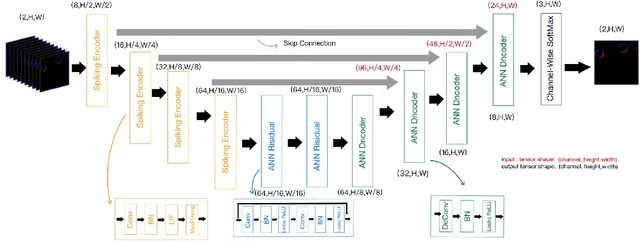
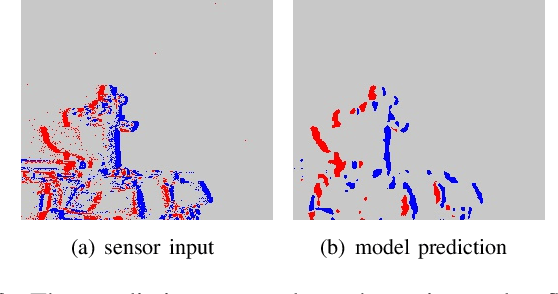
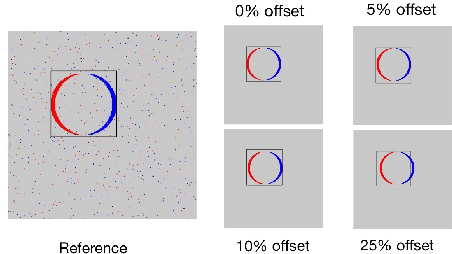
The Dynamic Vision Sensor (DVS) is an innovative technology that efficiently captures and encodes visual information in an event-driven manner. By combining it with event-driven neuromorphic processing, the sparsity in DVS camera output can result in high energy efficiency. However, similar to many embedded systems, the off-chip communication between the camera and processor presents a bottleneck in terms of power consumption. Inspired by the predictive coding model and expectation suppression phenomenon found in human brain, we propose a temporal attention mechanism to throttle the camera output and pay attention to it only when the visual events cannot be well predicted. The predictive attention not only reduces power consumption in the sensor-processor interface but also effectively decreases the computational workload by filtering out noisy events. We demonstrate that the predictive attention can reduce 46.7% of data communication between the camera and the processor and reduce 43.8% computation activities in the processor.
SemanticSLAM: Learning based Semantic Map Construction and Robust Camera Localization
Jan 23, 2024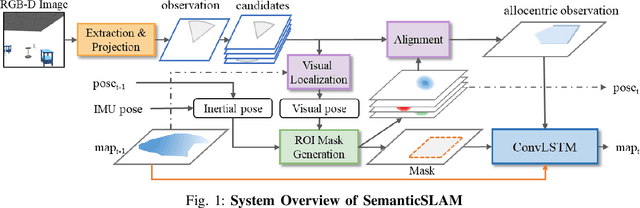

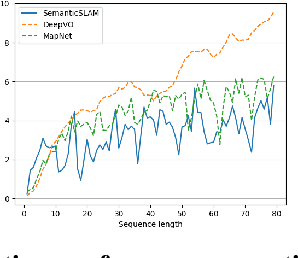
Current techniques in Visual Simultaneous Localization and Mapping (VSLAM) estimate camera displacement by comparing image features of consecutive scenes. These algorithms depend on scene continuity, hence requires frequent camera inputs. However, processing images frequently can lead to significant memory usage and computation overhead. In this study, we introduce SemanticSLAM, an end-to-end visual-inertial odometry system that utilizes semantic features extracted from an RGB-D sensor. This approach enables the creation of a semantic map of the environment and ensures reliable camera localization. SemanticSLAM is scene-agnostic, which means it doesn't require retraining for different environments. It operates effectively in indoor settings, even with infrequent camera input, without prior knowledge. The strength of SemanticSLAM lies in its ability to gradually refine the semantic map and improve pose estimation. This is achieved by a convolutional long-short-term-memory (ConvLSTM) network, trained to correct errors during map construction. Compared to existing VSLAM algorithms, SemanticSLAM improves pose estimation by 17%. The resulting semantic map provides interpretable information about the environment and can be easily applied to various downstream tasks, such as path planning, obstacle avoidance, and robot navigation. The code will be publicly available at https://github.com/Leomingyangli/SemanticSLAM
* 2023 IEEE Symposium Series on Computational Intelligence (SSCI) 6 pages
An Efficient Generalizable Framework for Visuomotor Policies via Control-aware Augmentation and Privilege-guided Distillation
Jan 17, 2024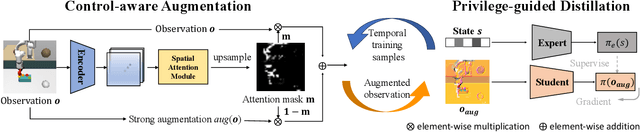
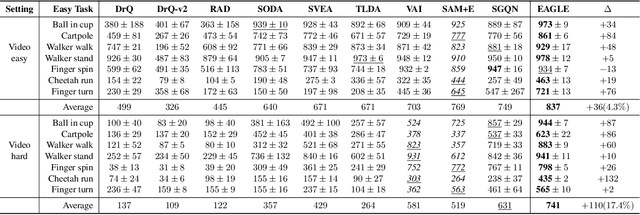
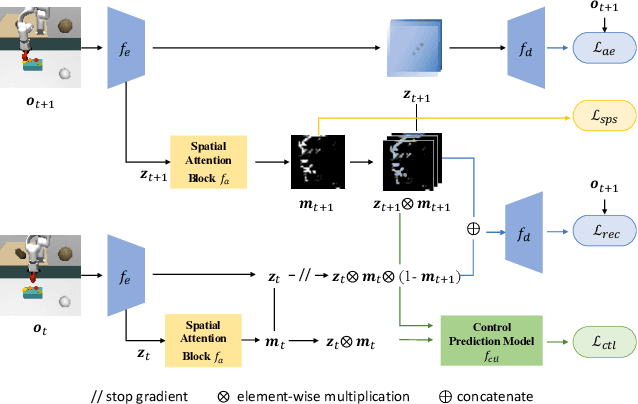
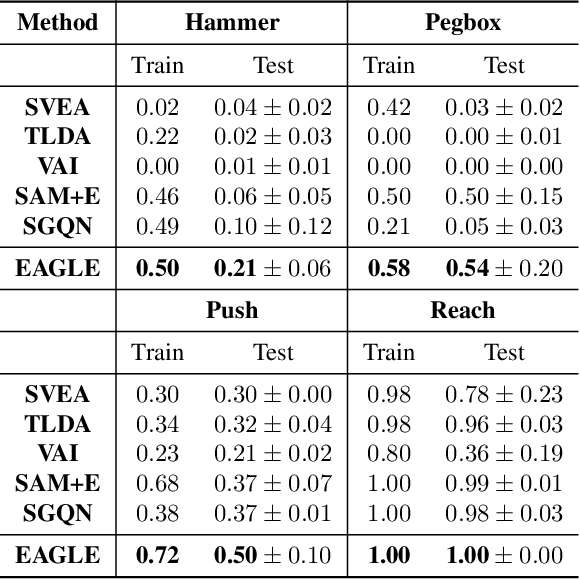
Visuomotor policies, which learn control mechanisms directly from high-dimensional visual observations, confront challenges in adapting to new environments with intricate visual variations. Data augmentation emerges as a promising method for bridging these generalization gaps by enriching data variety. However, straightforwardly augmenting the entire observation shall impose excessive burdens on policy learning and may even result in performance degradation. In this paper, we propose to improve the generalization ability of visuomotor policies as well as preserve training stability from two aspects: 1) We learn a control-aware mask through a self-supervised reconstruction task with three auxiliary losses and then apply strong augmentation only to those control-irrelevant regions based on the mask to reduce the generalization gaps. 2) To address training instability issues prevalent in visual reinforcement learning (RL), we distill the knowledge from a pretrained RL expert processing low-level environment states, to the student visuomotor policy. The policy is subsequently deployed to unseen environments without any further finetuning. We conducted comparison and ablation studies across various benchmarks: the DMControl Generalization Benchmark (DMC-GB), the enhanced Robot Manipulation Distraction Benchmark (RMDB), and a specialized long-horizontal drawer-opening robotic task. The extensive experimental results well demonstrate the effectiveness of our method, e.g., showing a 17\% improvement over previous methods in the video-hard setting of DMC-GB.