 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjectVLA: End-to-End Open-World Object Manipulation Without Demonstration
Feb 26, 2025Imitation learning has proven to be highly effective in teaching robots dexterous manipulation skills. However, it typically relies on large amounts of human demonstration data, which limits its scalability and applicability in dynamic, real-world environments. One key challenge in this context is object generalization, where a robot trained to perform a task with one object, such as "hand over the apple," struggles to transfer its skills to a semantically similar but visually different object, such as "hand over the peach." This gap in generalization to new objects beyond those in the same category has yet to be adequately addressed in previous work on end-to-end visuomotor policy learning. In this paper, we present a simple yet effective approach for achieving object generalization through Vision-Language-Action (VLA) models, referred to as \textbf{ObjectVLA}. Our model enables robots to generalize learned skills to novel objects without requiring explicit human demonstrations for each new target object. By leveraging vision-language pair data, our method provides a lightweight and scalable way to inject knowledge about the target object, establishing an implicit link between the object and the desired action. We evaluate ObjectVLA on a real robotic platform, demonstrating its ability to generalize across 100 novel objects with a 64\% success rate in selecting objects not seen during training. Furthermore, we propose a more accessible method for enhancing object generalization in VLA models, using a smartphone to capture a few images and fine-tune the pre-trained model. These results highlight the effectiveness of our approach in enabling object-level generalization and reducing the need for extensive human demonstrations, paving the way for more flexible and scalable robotic learning systems.
DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
Feb 09, 2025



Enabling robots to perform diverse tasks across varied environments is a central challenge in robot learning. While vision-language-action (VLA) models have shown promise for generalizable robot skills, realizing their full potential requires addressing limitations in action representation and efficient training. Current VLA models often focus on scaling the vision-language model (VLM) component, while the action space representation remains a critical bottleneck. This paper introduces DexVLA, a novel framework designed to enhance the efficiency and generalization capabilities of VLAs for complex, long-horizon tasks across diverse robot embodiments. DexVLA features a novel diffusion-based action expert, scaled to one billion parameters, designed for cross-embodiment learning. A novel embodiment curriculum learning strategy facilitates efficient training: (1) pre-training the diffusion expert that is separable from the VLA on cross-embodiment data, (2) aligning the VLA model to specific embodiments, and (3) post-training for rapid adaptation to new tasks. We conduct comprehensive experiments across multiple embodiments, including single-arm, bimanual, and dexterous hand, demonstrating DexVLA's adaptability to challenging tasks without task-specific adaptation, its ability to learn dexterous skills on novel embodiments with limited data, and its capacity to complete complex, long-horizon tasks using only direct language prompting, such as laundry folding. In all settings, our method demonstrates superior performance compared to state-of-the-art models like Octo, OpenVLA, and Diffusion Policy.
Improving Vision-Language-Action Models via Chain-of-Affordance
Dec 29, 2024



Robot foundation models, particularly Vision-Language-Action (VLA) models, have garnered significant attention for their ability to enhance robot policy learning, greatly improving robot generalization and robustness. OpenAI recent model, o1, showcased impressive capabilities in solving complex problems by utilizing extensive reasoning chains. This prompts an important question: can robot models achieve better performance in multi-task, complex environments by reviewing prior observations and then providing task-specific reasoning to guide action prediction? In this paper, we introduce \textbf{Chain-of-Affordance (CoA)}, a novel approach to scaling robot models by incorporating reasoning in the format of sequential robot affordances to facilitate task completion. Specifically, we prompt the model to consider the following four types of affordances before taking action: a) object affordance - what object to manipulate and where it is; b) grasp affordance - the specific object part to grasp; c) spatial affordance - the optimal space to place the object; and d) movement affordance - the collision-free path for movement. By integrating this knowledge into the policy model, the robot gains essential context, allowing it to act with increased precision and robustness during inference. Our experiments demonstrate that CoA achieves superior performance than state-of-the-art robot foundation models, such as OpenVLA and Octo. Additionally, CoA shows strong generalization to unseen object poses, identifies free space, and avoids obstacles in novel environments.
Diffusion-VLA: Scaling Robot Foundation Models via Unified Diffusion and Autoregression
Dec 04, 2024In this paper, we present DiffusionVLA, a novel framework that seamlessly combines the autoregression model with the diffusion model for learning visuomotor policy. Central to our approach is a next-token prediction objective, enabling the model to reason effectively over the user's query in the context of current observations. Subsequently, a diffusion model is attached to generate robust action outputs. To enhance policy learning through self-reasoning, we introduce a novel reasoning injection module that integrates reasoning phrases directly into the policy learning process. The whole framework is simple and flexible, making it easy to deploy and upgrade. We conduct extensive experiments using multiple real robots to validate the effectiveness of DiffusionVLA. Our tests include a challenging factory sorting task, where DiffusionVLA successfully categorizes objects, including those not seen during training. We observe that the reasoning module makes the model interpretable. It allows observers to understand the model thought process and identify potential causes of policy failures. Additionally, we test DiffusionVLA on a zero-shot bin-picking task, achieving 63.7\% accuracy on 102 previously unseen objects. Our method demonstrates robustness to visual changes, such as distractors and new backgrounds, and easily adapts to new embodiments. Furthermore, DiffusionVLA can follow novel instructions and retain conversational ability. Notably, DiffusionVLA is data-efficient and fast at inference; our smallest DiffusionVLA-2B runs 82Hz on a single A6000 GPU and can train from scratch on less than 50 demonstrations for a complex task. Finally, we scale the model from 2B to 72B parameters, showcasing improved generalization capabilities with increased model size.
Discrete Policy: Learning Disentangled Action Space for Multi-Task Robotic Manipulation
Sep 27, 2024



Learning visuomotor policy for multi-task robotic manipulation has been a long-standing challenge for the robotics community. The difficulty lies in the diversity of action space: typically, a goal can be accomplished in multiple ways, resulting in a multimodal action distribution for a single task. The complexity of action distribution escalates as the number of tasks increases. In this work, we propose \textbf{Discrete Policy}, a robot learning method for training universal agents capable of multi-task manipulation skills. Discrete Policy employs vector quantization to map action sequences into a discrete latent space, facilitating the learning of task-specific codes. These codes are then reconstructed into the action space conditioned on observations and language instruction. We evaluate our method on both simulation and multiple real-world embodiments, including both single-arm and bimanual robot settings. We demonstrate that our proposed Discrete Policy outperforms a well-established Diffusion Policy baseline and many state-of-the-art approaches, including ACT, Octo, and OpenVLA. For example, in a real-world multi-task training setting with five tasks, Discrete Policy achieves an average success rate that is 26\% higher than Diffusion Policy and 15\% higher than OpenVLA. As the number of tasks increases to 12, the performance gap between Discrete Policy and Diffusion Policy widens to 32.5\%, further showcasing the advantages of our approach. Our work empirically demonstrates that learning multi-task policies within the latent space is a vital step toward achieving general-purpose agents.
Scaling Diffusion Policy in Transformer to 1 Billion Parameters for Robotic Manipulation
Sep 22, 2024



Diffusion Policy is a powerful technique tool for learning end-to-end visuomotor robot control. It is expected that Diffusion Policy possesses scalability, a key attribute for deep neural networks, typically suggesting that increasing model size would lead to enhanced performance. However, our observations indicate that Diffusion Policy in transformer architecture (\DP) struggles to scale effectively; even minor additions of layers can deteriorate training outcomes. To address this issue, we introduce Scalable Diffusion Transformer Policy for visuomotor learning. Our proposed method, namely \textbf{\methodname}, introduces two modules that improve the training dynamic of Diffusion Policy and allow the network to better handle multimodal action distribution. First, we identify that \DP~suffers from large gradient issues, making the optimization of Diffusion Policy unstable. To resolve this issue, we factorize the feature embedding of observation into multiple affine layers, and integrate it into the transformer blocks. Additionally, our utilize non-causal attention which allows the policy network to \enquote{see} future actions during prediction, helping to reduce compounding errors. We demonstrate that our proposed method successfully scales the Diffusion Policy from 10 million to 1 billion parameters. This new model, named \methodname, can effectively scale up the model size with improved performance and generalization. We benchmark \methodname~across 50 different tasks from MetaWorld and find that our largest \methodname~outperforms \DP~with an average improvement of 21.6\%. Across 7 real-world robot tasks, our ScaleDP demonstrates an average improvement of 36.25\% over DP-T on four single-arm tasks and 75\% on three bimanual tasks. We believe our work paves the way for scaling up models for visuomotor learning. The project page is available at scaling-diffusion-policy.github.io.
MMRo: Are Multimodal LLMs Eligible as the Brain for In-Home Robotics?
Jun 28, 2024



It is fundamentally challenging for robots to serve as useful assistants in human environments because this requires addressing a spectrum of sub-problems across robotics, including perception, language understanding, reasoning, and planning. The recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated their exceptional abilities in solving complex mathematical problems, mastering commonsense and abstract reasoning. This has led to the recent utilization of MLLMs as the brain in robotic systems, enabling these models to conduct high-level planning prior to triggering low-level control actions for task execution. However, it remains uncertain whether existing MLLMs are reliable in serving the brain role of robots. In this study, we introduce the first benchmark for evaluating Multimodal LLM for Robotic (MMRo) benchmark, which tests the capability of MLLMs for robot applications. Specifically, we identify four essential capabilities perception, task planning, visual reasoning, and safety measurement that MLLMs must possess to qualify as the robot's central processing unit. We have developed several scenarios for each capability, resulting in a total of 14 metrics for evaluation. We present experimental results for various MLLMs, including both commercial and open-source models, to assess the performance of existing systems. Our findings indicate that no single model excels in all areas, suggesting that current MLLMs are not yet trustworthy enough to serve as the cognitive core for robots. Our data can be found in https://mm-robobench.github.io/.
A Survey on Robotics with Foundation Models: toward Embodied AI
Feb 04, 2024While the exploration for embodied AI has spanned multiple decades, it remains a persistent challenge to endow agents with human-level intelligence, including perception, learning, reasoning, decision-making, control, and generalization capabilities, so that they can perform general-purpose tasks in open, unstructured, and dynamic environments. Recent advances in computer vision, natural language processing, and multi-modality learning have shown that the foundation models have superhuman capabilities for specific tasks. They not only provide a solid cornerstone for integrating basic modules into embodied AI systems but also shed light on how to scale up robot learning from a methodological perspective. This survey aims to provide a comprehensive and up-to-date overview of foundation models in robotics, focusing on autonomous manipulation and encompassing high-level planning and low-level control. Moreover, we showcase their commonly used datasets, simulators, and benchmarks. Importantly, we emphasize the critical challenges intrinsic to this field and delineate potential avenues for future research, contributing to advancing the frontier of academic and industrial discourse.
Language-Conditioned Robotic Manipulation with Fast and Slow Thinking
Feb 01, 2024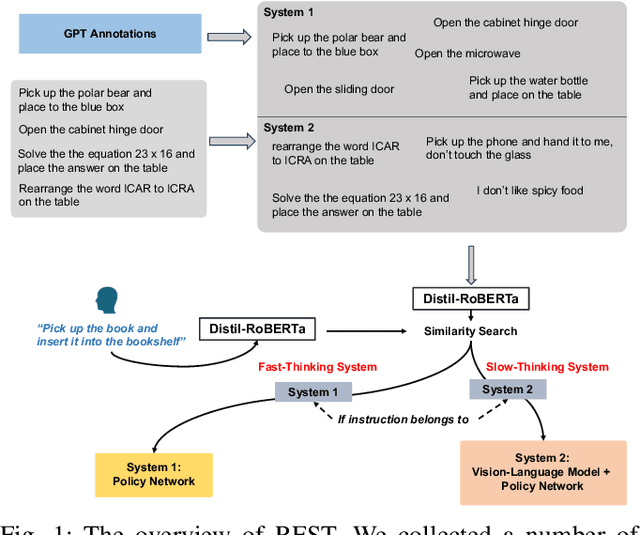



The language-conditioned robotic manipulation aims to transfer natural language instructions into executable actions, from simple pick-and-place to tasks requiring intent recognition and visual reasoning. Inspired by the dual process theory in cognitive science, which suggests two parallel systems of fast and slow thinking in human decision-making, we introduce Robotics with Fast and Slow Thinking (RFST), a framework that mimics human cognitive architecture to classify tasks and makes decisions on two systems based on instruction types. Our RFST consists of two key components: 1) an instruction discriminator to determine which system should be activated based on the current user instruction, and 2) a slow-thinking system that is comprised of a fine-tuned vision language model aligned with the policy networks, which allows the robot to recognize user intention or perform reasoning tasks. To assess our methodology, we built a dataset featuring real-world trajectories, capturing actions ranging from spontaneous impulses to tasks requiring deliberate contemplation. Our results, both in simulation and real-world scenarios, confirm that our approach adeptly manages intricate tasks that demand intent recognition and reasoning. The project is available at https://jlm-z.github.io/RSFT/
Visual Robotic Manipulation with Depth-Aware Pretraining
Jan 17, 2024


Recent work on visual representation learning has shown to be efficient for robotic manipulation tasks. However, most existing works pretrained the visual backbone solely on 2D images or egocentric videos, ignoring the fact that robots learn to act in 3D space, which is hard to learn from 2D observation. In this paper, we examine the effectiveness of pretraining for vision backbone with public-available large-scale 3D data to improve manipulation policy learning. Our method, namely Depth-aware Pretraining for Robotics (DPR), enables an RGB-only backbone to learn 3D scene representations from self-supervised contrastive learning, where depth information serves as auxiliary knowledge. No 3D information is necessary during manipulation policy learning and inference, making our model enjoy both efficiency and effectiveness in 3D space manipulation. Furthermore, we introduce a new way to inject robots' proprioception into the policy networks that makes the manipulation model robust and generalizable. We demonstrate in experiments that our proposed framework improves performance on unseen objects and visual environments for various robotics tasks on both simulated and real robots.