 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiveUMI: Robotic Manipulation with Active Perception from Robot-Free Human Demonstrations
Oct 02, 2025


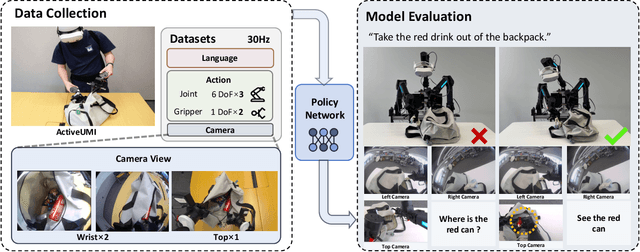
We present ActiveUMI, a framework for a data collection system that transfers in-the-wild human demonstrations to robots capable of complex bimanual manipulation. ActiveUMI couples a portable VR teleoperation kit with sensorized controllers that mirror the robot's end-effectors, bridging human-robot kinematics via precise pose alignment. To ensure mobility and data quality, we introduce several key techniques, including immersive 3D model rendering, a self-contained wearable computer, and efficient calibration methods. ActiveUMI's defining feature is its capture of active, egocentric perception. By recording an operator's deliberate head movements via a head-mounted display, our system learns the crucial link between visual attention and manipulation. We evaluate ActiveUMI on six challenging bimanual tasks. Policies trained exclusively on ActiveUMI data achieve an average success rate of 70\% on in-distribution tasks and demonstrate strong generalization, retaining a 56\% success rate when tested on novel objects and in new environments. Our results demonstrate that portable data collection systems, when coupled with learned active perception, provide an effective and scalable pathway toward creating generalizable and highly capable real-world robot policies.
ChatVLA-2: Vision-Language-Action Model with Open-World Embodied Reasoning from Pretrained Knowledge
May 29, 2025Vision-language-action (VLA) models have emerged as the next generation of models in robotics. However, despite leveraging powerful pre-trained Vision-Language Models (VLMs), existing end-to-end VLA systems often lose key capabilities during fine-tuning as the model adapts to specific robotic tasks. We argue that a generalizable VLA model should retain and expand upon the VLM's core competencies: 1) Open-world embodied reasoning - the VLA should inherit the knowledge from VLM, i.e., recognize anything that the VLM can recognize, be capable of solving math problems, and possess visual-spatial intelligence, 2) Reasoning following - effectively translating the open-world reasoning into actionable steps for the robot. In this work, we introduce ChatVLA-2, a novel mixture-of-expert VLA model coupled with a specialized two-stage training pipeline designed to preserve the VLM's original strengths while enabling actionable reasoning. To validate our approach, we design a math-matching task wherein a robot interprets math problems written on a whiteboard and picks corresponding number cards from a table to solve equations. Remarkably, our method exhibits exceptional mathematical reasoning and OCR capabilities, despite these abilities not being explicitly trained within the VLA. Furthermore, we demonstrate that the VLA possesses strong spatial reasoning skills, enabling it to interpret novel directional instructions involving previously unseen objects. Overall, our method showcases reasoning and comprehension abilities that significantly surpass state-of-the-art imitation learning methods such as OpenVLA, DexVLA, and pi-zero. This work represents a substantial advancement toward developing truly generalizable robotic foundation models endowed with robust reasoning capacities.
Vision-Language-Action Model with Open-World Embodied Reasoning from Pretrained Knowledge
May 28, 2025Vision-language-action (VLA) models have emerged as the next generation of models in robotics. However, despite leveraging powerful pre-trained Vision-Language Models (VLMs), existing end-to-end VLA systems often lose key capabilities during fine-tuning as the model adapts to specific robotic tasks. We argue that a generalizable VLA model should retain and expand upon the VLM's core competencies: 1) Open-world embodied reasoning - the VLA should inherit the knowledge from VLM, i.e., recognize anything that the VLM can recognize, capable of solving math problems, possessing visual-spatial intelligence, 2) Reasoning following - effectively translating the open-world reasoning into actionable steps for the robot. In this work, we introduce ChatVLA-2, a novel mixture-of-expert VLA model coupled with a specialized three-stage training pipeline designed to preserve the VLM's original strengths while enabling actionable reasoning. To validate our approach, we design a math-matching task wherein a robot interprets math problems written on a whiteboard and picks corresponding number cards from a table to solve equations. Remarkably, our method exhibits exceptional mathematical reasoning and OCR capabilities, despite these abilities not being explicitly trained within the VLA. Furthermore, we demonstrate that the VLA possesses strong spatial reasoning skills, enabling it to interpret novel directional instructions involving previously unseen objects. Overall, our method showcases reasoning and comprehension abilities that significantly surpass state-of-the-art imitation learning methods such as OpenVLA, DexVLA, and pi-zero. This work represents a substantial advancement toward developing truly generalizable robotic foundation models endowed with robust reasoning capacities.
WorldEval: World Model as Real-World Robot Policies Evaluator
May 25, 2025The field of robotics has made significant strides toward developing generalist robot manipulation policies. However, evaluating these policies in real-world scenarios remains time-consuming and challenging, particularly as the number of tasks scales and environmental conditions change. In this work, we demonstrate that world models can serve as a scalable, reproducible, and reliable proxy for real-world robot policy evaluation. A key challenge is generating accurate policy videos from world models that faithfully reflect the robot actions. We observe that directly inputting robot actions or using high-dimensional encoding methods often fails to generate action-following videos. To address this, we propose Policy2Vec, a simple yet effective approach to turn a video generation model into a world simulator that follows latent action to generate the robot video. We then introduce WorldEval, an automated pipeline designed to evaluate real-world robot policies entirely online. WorldEval effectively ranks various robot policies and individual checkpoints within a single policy, and functions as a safety detector to prevent dangerous actions by newly developed robot models. Through comprehensive paired evaluations of manipulation policies in real-world environments, we demonstrate a strong correlation between policy performance in WorldEval and real-world scenarios. Furthermore, our method significantly outperforms popular methods such as real-to-sim approach.
PointVLA: Injecting the 3D World into Vision-Language-Action Models
Mar 10, 2025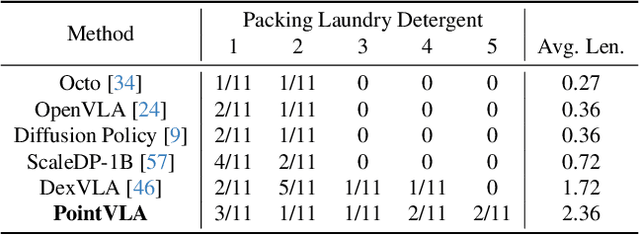
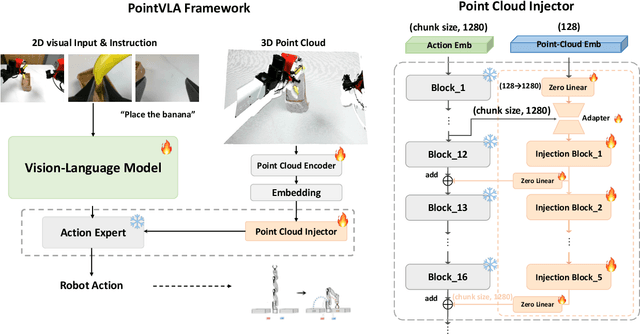
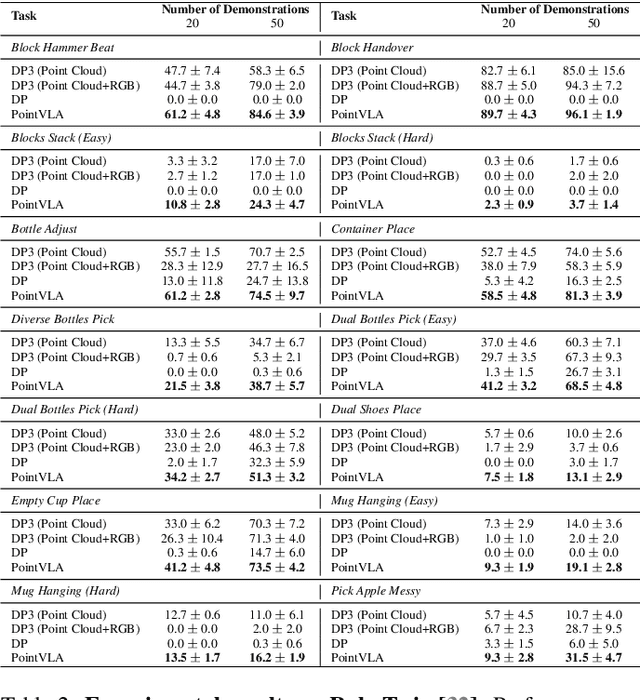
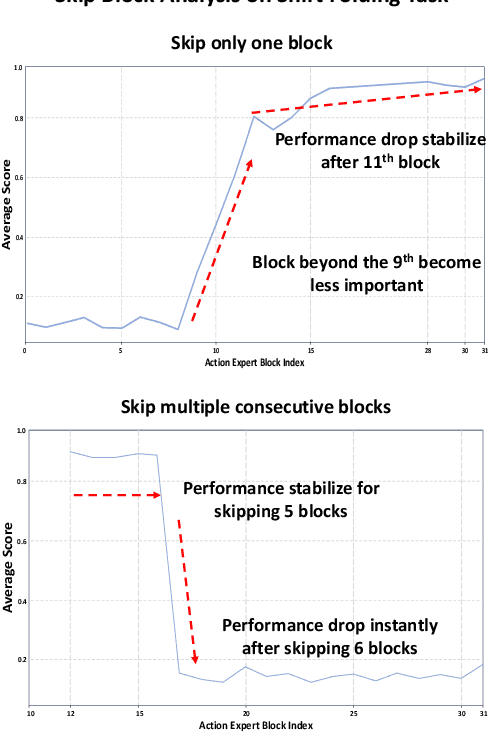
Vision-Language-Action (VLA) models excel at robotic tasks by leveraging large-scale 2D vision-language pretraining, but their reliance on RGB images limits spatial reasoning critical for real-world interaction. Retraining these models with 3D data is computationally prohibitive, while discarding existing 2D datasets wastes valuable resources. To bridge this gap, we propose PointVLA, a framework that enhances pre-trained VLAs with point cloud inputs without requiring retraining. Our method freezes the vanilla action expert and injects 3D features via a lightweight modular block. To identify the most effective way of integrating point cloud representations, we conduct a skip-block analysis to pinpoint less useful blocks in the vanilla action expert, ensuring that 3D features are injected only into these blocks--minimizing disruption to pre-trained representations. Extensive experiments demonstrate that PointVLA outperforms state-of-the-art 2D imitation learning methods, such as OpenVLA, Diffusion Policy and DexVLA, across both simulated and real-world robotic tasks. Specifically, we highlight several key advantages of PointVLA enabled by point cloud integration: (1) Few-shot multi-tasking, where PointVLA successfully performs four different tasks using only 20 demonstrations each; (2) Real-vs-photo discrimination, where PointVLA distinguishes real objects from their images, leveraging 3D world knowledge to improve safety and reliability; (3) Height adaptability, Unlike conventional 2D imitation learning methods, PointVLA enables robots to adapt to objects at varying table height that unseen in train data. Furthermore, PointVLA achieves strong performance in long-horizon tasks, such as picking and packing objects from a moving conveyor belt, showcasing its ability to generalize across complex, dynamic environments.
ObjectVLA: End-to-End Open-World Object Manipulation Without Demonstration
Feb 26, 2025Imitation learning has proven to be highly effective in teaching robots dexterous manipulation skills. However, it typically relies on large amounts of human demonstration data, which limits its scalability and applicability in dynamic, real-world environments. One key challenge in this context is object generalization, where a robot trained to perform a task with one object, such as "hand over the apple," struggles to transfer its skills to a semantically similar but visually different object, such as "hand over the peach." This gap in generalization to new objects beyond those in the same category has yet to be adequately addressed in previous work on end-to-end visuomotor policy learning. In this paper, we present a simple yet effective approach for achieving object generalization through Vision-Language-Action (VLA) models, referred to as \textbf{ObjectVLA}. Our model enables robots to generalize learned skills to novel objects without requiring explicit human demonstrations for each new target object. By leveraging vision-language pair data, our method provides a lightweight and scalable way to inject knowledge about the target object, establishing an implicit link between the object and the desired action. We evaluate ObjectVLA on a real robotic platform, demonstrating its ability to generalize across 100 novel objects with a 64\% success rate in selecting objects not seen during training. Furthermore, we propose a more accessible method for enhancing object generalization in VLA models, using a smartphone to capture a few images and fine-tune the pre-trained model. These results highlight the effectiveness of our approach in enabling object-level generalization and reducing the need for extensive human demonstrations, paving the way for more flexible and scalable robotic learning systems.
ChatVLA: Unified Multimodal Understanding and Robot Control with Vision-Language-Action Model
Feb 21, 2025Humans possess a unified cognitive ability to perceive, comprehend, and interact with the physical world. Why can't large language models replicate this holistic understanding? Through a systematic analysis of existing training paradigms in vision-language-action models (VLA), we identify two key challenges: spurious forgetting, where robot training overwrites crucial visual-text alignments, and task interference, where competing control and understanding tasks degrade performance when trained jointly. To overcome these limitations, we propose ChatVLA, a novel framework featuring Phased Alignment Training, which incrementally integrates multimodal data after initial control mastery, and a Mixture-of-Experts architecture to minimize task interference. ChatVLA demonstrates competitive performance on visual question-answering datasets and significantly surpasses state-of-the-art vision-language-action (VLA) methods on multimodal understanding benchmarks. Notably, it achieves a six times higher performance on MMMU and scores 47.2% on MMStar with a more parameter-efficient design than ECoT. Furthermore, ChatVLA demonstrates superior performance on 25 real-world robot manipulation tasks compared to existing VLA methods like OpenVLA. Our findings highlight the potential of our unified framework for achieving both robust multimodal understanding and effective robot control.
DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
Feb 09, 2025



Enabling robots to perform diverse tasks across varied environments is a central challenge in robot learning. While vision-language-action (VLA) models have shown promise for generalizable robot skills, realizing their full potential requires addressing limitations in action representation and efficient training. Current VLA models often focus on scaling the vision-language model (VLM) component, while the action space representation remains a critical bottleneck. This paper introduces DexVLA, a novel framework designed to enhance the efficiency and generalization capabilities of VLAs for complex, long-horizon tasks across diverse robot embodiments. DexVLA features a novel diffusion-based action expert, scaled to one billion parameters, designed for cross-embodiment learning. A novel embodiment curriculum learning strategy facilitates efficient training: (1) pre-training the diffusion expert that is separable from the VLA on cross-embodiment data, (2) aligning the VLA model to specific embodiments, and (3) post-training for rapid adaptation to new tasks. We conduct comprehensive experiments across multiple embodiments, including single-arm, bimanual, and dexterous hand, demonstrating DexVLA's adaptability to challenging tasks without task-specific adaptation, its ability to learn dexterous skills on novel embodiments with limited data, and its capacity to complete complex, long-horizon tasks using only direct language prompting, such as laundry folding. In all settings, our method demonstrates superior performance compared to state-of-the-art models like Octo, OpenVLA, and Diffusion Policy.
Improving Vision-Language-Action Models via Chain-of-Affordance
Dec 29, 2024



Robot foundation models, particularly Vision-Language-Action (VLA) models, have garnered significant attention for their ability to enhance robot policy learning, greatly improving robot generalization and robustness. OpenAI recent model, o1, showcased impressive capabilities in solving complex problems by utilizing extensive reasoning chains. This prompts an important question: can robot models achieve better performance in multi-task, complex environments by reviewing prior observations and then providing task-specific reasoning to guide action prediction? In this paper, we introduce \textbf{Chain-of-Affordance (CoA)}, a novel approach to scaling robot models by incorporating reasoning in the format of sequential robot affordances to facilitate task completion. Specifically, we prompt the model to consider the following four types of affordances before taking action: a) object affordance - what object to manipulate and where it is; b) grasp affordance - the specific object part to grasp; c) spatial affordance - the optimal space to place the object; and d) movement affordance - the collision-free path for movement. By integrating this knowledge into the policy model, the robot gains essential context, allowing it to act with increased precision and robustness during inference. Our experiments demonstrate that CoA achieves superior performance than state-of-the-art robot foundation models, such as OpenVLA and Octo. Additionally, CoA shows strong generalization to unseen object poses, identifies free space, and avoids obstacles in novel environments.
Diffusion-VLA: Scaling Robot Foundation Models via Unified Diffusion and Autoregression
Dec 04, 2024In this paper, we present DiffusionVLA, a novel framework that seamlessly combines the autoregression model with the diffusion model for learning visuomotor policy. Central to our approach is a next-token prediction objective, enabling the model to reason effectively over the user's query in the context of current observations. Subsequently, a diffusion model is attached to generate robust action outputs. To enhance policy learning through self-reasoning, we introduce a novel reasoning injection module that integrates reasoning phrases directly into the policy learning process. The whole framework is simple and flexible, making it easy to deploy and upgrade. We conduct extensive experiments using multiple real robots to validate the effectiveness of DiffusionVLA. Our tests include a challenging factory sorting task, where DiffusionVLA successfully categorizes objects, including those not seen during training. We observe that the reasoning module makes the model interpretable. It allows observers to understand the model thought process and identify potential causes of policy failures. Additionally, we test DiffusionVLA on a zero-shot bin-picking task, achieving 63.7\% accuracy on 102 previously unseen objects. Our method demonstrates robustness to visual changes, such as distractors and new backgrounds, and easily adapts to new embodiments. Furthermore, DiffusionVLA can follow novel instructions and retain conversational ability. Notably, DiffusionVLA is data-efficient and fast at inference; our smallest DiffusionVLA-2B runs 82Hz on a single A6000 GPU and can train from scratch on less than 50 demonstrations for a complex task. Finally, we scale the model from 2B to 72B parameters, showcasing improved generalization capabilities with increased model size.