 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the (In-)Security of the Shuffling Defense in the Transformer Secure Inference
May 06, 2026For Transformer models, cryptographically secure inference ensures that the client learns only the final output, while the server learns nothing about the client's input. However, securely computing nonlinear layers remains a major efficiency bottleneck due to the substantial communication rounds and data transmission required. To address this issue, prior works reveal intermediate activations to the client, allowing nonlinear operations to be computed in plaintext. Although this approach significantly improves efficiency, exposing activations enables adversaries to extract model weights. To mitigate this risk, existing works employ a shuffling defense that reveals only randomly permuted activations to the client. In this work, we show that the shuffling defense is not as robust as previously claimed. We propose an attack that aligns differently shuffled activations to a common permutation and subsequently exploits them to extract model weights. Experiments on Pythia-70m and GPT-2 demonstrate that the proposed attack can align shuffled activations with mean squared errors ranging from $10^{-9}$ to $10^{-6}$. With a query cost of approximately \$1, the adversary can recover model weights with L1-norm differences ranging from $10^{-4}$ to $10^{-2}$ compared to the oracle weights.
VORL-EXPLORE: A Hybrid Learning Planning Approach to Multi-Robot Exploration in Dynamic Environments
Mar 09, 2026Hierarchical multi-robot exploration commonly decouples frontier allocation from local navigation, which can make the system brittle in dense and dynamic environments. Because the allocator lacks direct awareness of execution difficulty, robots may cluster at bottlenecks, trigger oscillatory replanning, and generate redundant coverage. We propose VORL-EXPLORE, a hybrid learning and planning framework that addresses this limitation through execution fidelity, a shared estimate of local navigability that couples task allocation with motion execution. This fidelity signal is incorporated into a fidelity-coupled Voronoi objective with inter-robot repulsion to reduce contention before it emerges. It also drives a risk-aware adaptive arbitration mechanism between global A* guidance and a reactive reinforcement learning policy, balancing long-range efficiency with safe interaction in confined spaces. The framework further supports online self-supervised recalibration of the fidelity model using pseudo-labels derived from recent progress and safety outcomes, enabling adaptation to non-stationary obstacles without manual risk tuning. We evaluate this capability separately in a dedicated severe-traffic ablation. Extensive experiments in randomized grids and a Gazebo factory scenario show high success rates, shorter path length, lower overlap, and robust collision avoidance. The source code will be made publicly available upon acceptance.
RoboAug: One Annotation to Hundreds of Scenes via Region-Contrastive Data Augmentation for Robotic Manipulation
Feb 15, 2026Enhancing the generalization capability of robotic learning to enable robots to operate effectively in diverse, unseen scenes is a fundamental and challenging problem. Existing approaches often depend on pretraining with large-scale data collection, which is labor-intensive and time-consuming, or on semantic data augmentation techniques that necessitate an impractical assumption of flawless upstream object detection in real-world scenarios. In this work, we propose RoboAug, a novel generative data augmentation framework that significantly minimizes the reliance on large-scale pretraining and the perfect visual recognition assumption by requiring only the bounding box annotation of a single image during training. Leveraging this minimal information, RoboAug employs pre-trained generative models for precise semantic data augmentation and integrates a plug-and-play region-contrastive loss to help models focus on task-relevant regions, thereby improving generalization and boosting task success rates. We conduct extensive real-world experiments on three robots, namely UR-5e, AgileX, and Tien Kung 2.0, spanning over 35k rollouts. Empirical results demonstrate that RoboAug significantly outperforms state-of-the-art data augmentation baselines. Specifically, when evaluating generalization capabilities in unseen scenes featuring diverse combinations of backgrounds, distractors, and lighting conditions, our method achieves substantial gains over the baseline without augmentation. The success rates increase from 0.09 to 0.47 on UR-5e, from 0.16 to 0.60 on AgileX, and from 0.19 to 0.67 on Tien Kung 2.0. These results highlight the superior generalization and effectiveness of RoboAug in real-world manipulation tasks. Our project is available at https://x-roboaug.github.io/.
Adaptive Reinforcement and Model Predictive Control Switching for Safe Human-Robot Cooperative Navigation
Jan 23, 2026This paper addresses the challenge of human-guided navigation for mobile collaborative robots under simultaneous proximity regulation and safety constraints. We introduce Adaptive Reinforcement and Model Predictive Control Switching (ARMS), a hybrid learning-control framework that integrates a reinforcement learning follower trained with Proximal Policy Optimization (PPO) and an analytical one-step Model Predictive Control (MPC) formulated as a quadratic program safety filter. To enable robust perception under partial observability and non-stationary human motion, ARMS employs a decoupled sensing architecture with a Long Short-Term Memory (LSTM) temporal encoder for the human-robot relative state and a spatial encoder for 360-degree LiDAR scans. The core contribution is a learned adaptive neural switcher that performs context-aware soft action fusion between the two controllers, favoring conservative, constraint-aware QP-based control in low-risk regions while progressively shifting control authority to the learned follower in highly cluttered or constrained scenarios where maneuverability is critical, and reverting to the follower action when the QP becomes infeasible. Extensive evaluations against Pure Pursuit, Dynamic Window Approach (DWA), and an RL-only baseline demonstrate that ARMS achieves an 82.5 percent success rate in highly cluttered environments, outperforming DWA and RL-only approaches by 7.1 percent and 3.1 percent, respectively, while reducing average computational latency by 33 percent to 5.2 milliseconds compared to a multi-step MPC baseline. Additional simulation transfer in Gazebo and initial real-world deployment results further indicate the practicality and robustness of ARMS for safe and efficient human-robot collaboration. Source code and a demonstration video are available at https://github.com/21ning/ARMS.git.
$D^2Prune$: Sparsifying Large Language Models via Dual Taylor Expansion and Attention Distribution Awareness
Jan 14, 2026Large language models (LLMs) face significant deployment challenges due to their massive computational demands. % While pruning offers a promising compression solution, existing methods suffer from two critical limitations: (1) They neglect activation distribution shifts between calibration data and test data, resulting in inaccurate error estimations; (2) They overlook the long-tail distribution characteristics of activations in the attention module. To address these limitations, this paper proposes a novel pruning method, $D^2Prune$. First, we propose a dual Taylor expansion-based method that jointly models weight and activation perturbations for precise error estimation, leading to precise pruning mask selection and weight updating and facilitating error minimization during pruning. % Second, we propose an attention-aware dynamic update strategy that preserves the long-tail attention pattern by jointly minimizing the KL divergence of attention distributions and the reconstruction error. Extensive experiments show that $D^2Prune$ consistently outperforms SOTA methods across various LLMs (e.g., OPT-125M, LLaMA2/3, and Qwen3). Moreover, the dynamic attention update mechanism also generalizes well to ViT-based vision models like DeiT, achieving superior accuracy on ImageNet-1K.
M3MAD-Bench: Are Multi-Agent Debates Really Effective Across Domains and Modalities?
Jan 06, 2026As an agent-level reasoning and coordination paradigm, Multi-Agent Debate (MAD) orchestrates multiple agents through structured debate to improve answer quality and support complex reasoning. However, existing research on MAD suffers from two fundamental limitations: evaluations are conducted under fragmented and inconsistent settings, hindering fair comparison, and are largely restricted to single-modality scenarios that rely on textual inputs only. To address these gaps, we introduce M3MAD-Bench, a unified and extensible benchmark for evaluating MAD methods across Multi-domain tasks, Multi-modal inputs, and Multi-dimensional metrics. M3MAD-Bench establishes standardized protocols over five core task domains: Knowledge, Mathematics, Medicine, Natural Sciences, and Complex Reasoning, and systematically covers both pure text and vision-language datasets, enabling controlled cross-modality comparison. We evaluate MAD methods on nine base models spanning different architectures, scales, and modality capabilities. Beyond accuracy, M3MAD-Bench incorporates efficiency-oriented metrics such as token consumption and inference time, providing a holistic view of performance--cost trade-offs. Extensive experiments yield systematic insights into the effectiveness, robustness, and efficiency of MAD across text-only and multimodal scenarios. We believe M3MAD-Bench offers a reliable foundation for future research on standardized MAD evaluation. The code is available at http://github.com/liaolea/M3MAD-Bench.
RoboMIND 2.0: A Multimodal, Bimanual Mobile Manipulation Dataset for Generalizable Embodied Intelligence
Dec 31, 2025While data-driven imitation learning has revolutionized robotic manipulation, current approaches remain constrained by the scarcity of large-scale, diverse real-world demonstrations. Consequently, the ability of existing models to generalize across long-horizon bimanual tasks and mobile manipulation in unstructured environments remains limited. To bridge this gap, we present RoboMIND 2.0, a comprehensive real-world dataset comprising over 310K dual-arm manipulation trajectories collected across six distinct robot embodiments and 739 complex tasks. Crucially, to support research in contact-rich and spatially extended tasks, the dataset incorporates 12K tactile-enhanced episodes and 20K mobile manipulation trajectories. Complementing this physical data, we construct high-fidelity digital twins of our real-world environments, releasing an additional 20K-trajectory simulated dataset to facilitate robust sim-to-real transfer. To fully exploit the potential of RoboMIND 2.0, we propose MIND-2 system, a hierarchical dual-system frame-work optimized via offline reinforcement learning. MIND-2 integrates a high-level semantic planner (MIND-2-VLM) to decompose abstract natural language instructions into grounded subgoals, coupled with a low-level Vision-Language-Action executor (MIND-2-VLA), which generates precise, proprioception-aware motor actions.
DIFNet: Decentralized Information Filtering Fusion Neural Network with Unknown Correlation in Sensor Measurement Noises
Aug 26, 2025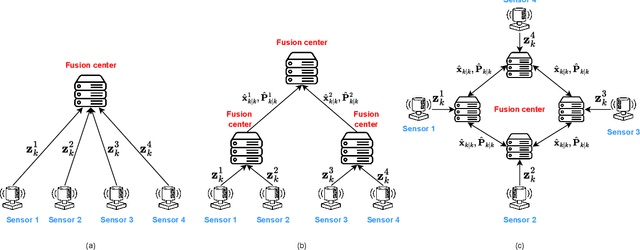
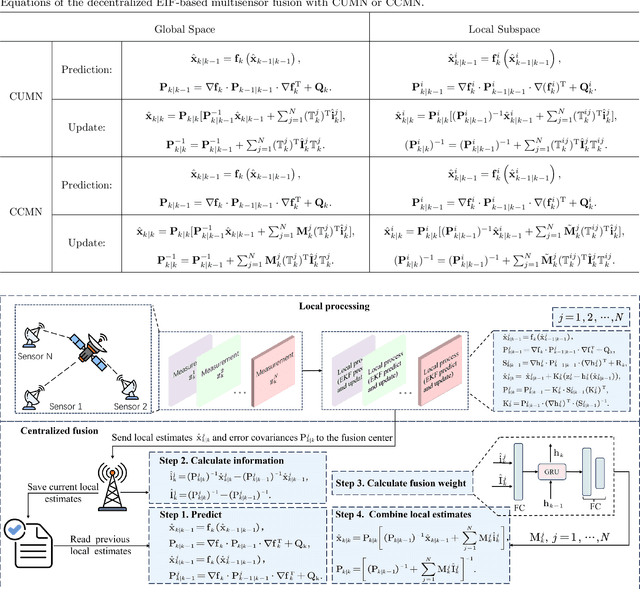
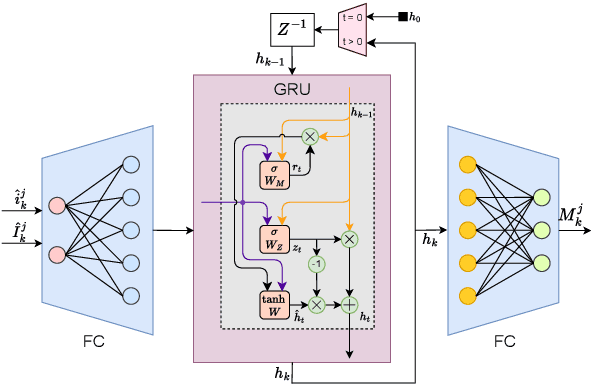
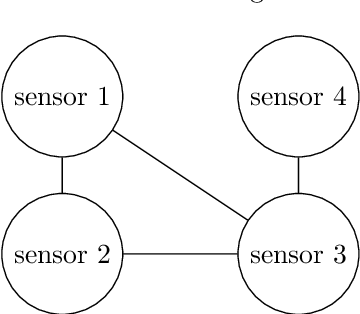
In recent years, decentralized sensor networks have garnered significant attention in the field of state estimation owing to enhanced robustness, scalability, and fault tolerance. Optimal fusion performance can be achieved under fully connected communication and known noise correlation structures. To mitigate communication overhead, the global state estimation problem is decomposed into local subproblems through structured observation model. This ensures that even when the communication network is not fully connected, each sensor can achieve locally optimal estimates of its observable state components. To address the degradation of fusion accuracy induced by unknown correlations in measurement noise, this paper proposes a data-driven method, termed Decentralized Information Filter Neural Network (DIFNet), to learn unknown noise correlations in data for discrete-time nonlinear state space models with cross-correlated measurement noises. Numerical simulations demonstrate that DIFNet achieves superior fusion performance compared to conventional filtering methods and exhibits robust characteristics in more complex scenarios, such as the presence of time-varying noise. The source code used in our numerical experiment can be found online at https://wisdom-estimation.github.io/DIFNet_Demonstrate/.
EnerBridge-DPO: Energy-Guided Protein Inverse Folding with Markov Bridges and Direct Preference Optimization
Jun 11, 2025


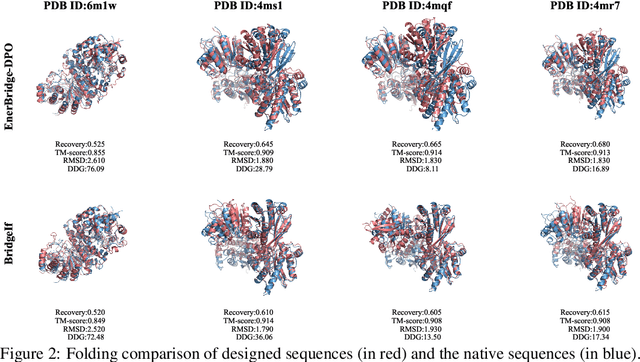
Designing protein sequences with optimal energetic stability is a key challenge in protein inverse folding, as current deep learning methods are primarily trained by maximizing sequence recovery rates, often neglecting the energy of the generated sequences. This work aims to overcome this limitation by developing a model that directly generates low-energy, stable protein sequences. We propose EnerBridge-DPO, a novel inverse folding framework focused on generating low-energy, high-stability protein sequences. Our core innovation lies in: First, integrating Markov Bridges with Direct Preference Optimization (DPO), where energy-based preferences are used to fine-tune the Markov Bridge model. The Markov Bridge initiates optimization from an information-rich prior sequence, providing DPO with a pool of structurally plausible sequence candidates. Second, an explicit energy constraint loss is introduced, which enhances the energy-driven nature of DPO based on prior sequences, enabling the model to effectively learn energy representations from a wealth of prior knowledge and directly predict sequence energy values, thereby capturing quantitative features of the energy landscape. Our evaluations demonstrate that EnerBridge-DPO can design protein complex sequences with lower energy while maintaining sequence recovery rates comparable to state-of-the-art models, and accurately predicts $\Delta \Delta G$ values between various sequences.
FreqPolicy: Efficient Flow-based Visuomotor Policy via Frequency Consistency
Jun 10, 2025Generative modeling-based visuomotor policies have been widely adopted in robotic manipulation attributed to their ability to model multimodal action distributions. However, the high inference cost of multi-step sampling limits their applicability in real-time robotic systems. To address this issue, existing approaches accelerate the sampling process in generative modeling-based visuomotor policies by adapting acceleration techniques originally developed for image generation. Despite this progress, a major distinction remains: image generation typically involves producing independent samples without temporal dependencies, whereas robotic manipulation involves generating time-series action trajectories that require continuity and temporal coherence. To effectively exploit temporal information in robotic manipulation, we propose FreqPolicy, a novel approach that first imposes frequency consistency constraints on flow-based visuomotor policies. Our work enables the action model to capture temporal structure effectively while supporting efficient, high-quality one-step action generation. We introduce a frequency consistency constraint that enforces alignment of frequency-domain action features across different timesteps along the flow, thereby promoting convergence of one-step action generation toward the target distribution. In addition, we design an adaptive consistency loss to capture structural temporal variations inherent in robotic manipulation tasks. We assess FreqPolicy on 53 tasks across 3 simulation benchmarks, proving its superiority over existing one-step action generators. We further integrate FreqPolicy into the vision-language-action (VLA) model and achieve acceleration without performance degradation on the 40 tasks of Libero. Besides, we show efficiency and effectiveness in real-world robotic scenarios with an inference frequency 93.5Hz. The code will be publicly available.