 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the (In-)Security of the Shuffling Defense in the Transformer Secure Inference
May 06, 2026For Transformer models, cryptographically secure inference ensures that the client learns only the final output, while the server learns nothing about the client's input. However, securely computing nonlinear layers remains a major efficiency bottleneck due to the substantial communication rounds and data transmission required. To address this issue, prior works reveal intermediate activations to the client, allowing nonlinear operations to be computed in plaintext. Although this approach significantly improves efficiency, exposing activations enables adversaries to extract model weights. To mitigate this risk, existing works employ a shuffling defense that reveals only randomly permuted activations to the client. In this work, we show that the shuffling defense is not as robust as previously claimed. We propose an attack that aligns differently shuffled activations to a common permutation and subsequently exploits them to extract model weights. Experiments on Pythia-70m and GPT-2 demonstrate that the proposed attack can align shuffled activations with mean squared errors ranging from $10^{-9}$ to $10^{-6}$. With a query cost of approximately \$1, the adversary can recover model weights with L1-norm differences ranging from $10^{-4}$ to $10^{-2}$ compared to the oracle weights.
MMP-2K: A Benchmark Multi-Labeled Macro Photography Image Quality Assessment Database
May 25, 2025Macro photography (MP) is a specialized field of photography that captures objects at an extremely close range, revealing tiny details. Although an accurate macro photography image quality assessment (MPIQA) metric can benefit macro photograph capturing, which is vital in some domains such as scientific research and medical applications, the lack of MPIQA data limits the development of MPIQA metrics. To address this limitation, we conducted a large-scale MPIQA study. Specifically, to ensure diversity both in content and quality, we sampled 2,000 MP images from 15,700 MP images, collected from three public image websites. For each MP image, 17 (out of 21 after outlier removal) quality ratings and a detailed quality report of distortion magnitudes, types, and positions are gathered by a lab study. The images, quality ratings, and quality reports form our novel multi-labeled MPIQA database, MMP-2k. Experimental results showed that the state-of-the-art generic IQA metrics underperform on MP images. The database and supplementary materials are available at https://github.com/Future-IQA/MMP-2k.
An Efficient Private GPT Never Autoregressively Decodes
May 21, 2025The wide deployment of the generative pre-trained transformer (GPT) has raised privacy concerns for both clients and servers. While cryptographic primitives can be employed for secure GPT inference to protect the privacy of both parties, they introduce considerable performance overhead.To accelerate secure inference, this study proposes a public decoding and secure verification approach that utilizes public GPT models, motivated by the observation that securely decoding one and multiple tokens takes a similar latency. The client uses the public model to generate a set of tokens, which are then securely verified by the private model for acceptance. The efficiency of our approach depends on the acceptance ratio of tokens proposed by the public model, which we improve from two aspects: (1) a private sampling protocol optimized for cryptographic primitives and (2) model alignment using knowledge distillation. Our approach improves the efficiency of secure decoding while maintaining the same level of privacy and generation quality as standard secure decoding. Experiments demonstrate a $2.1\times \sim 6.0\times$ speedup compared to standard decoding across three pairs of public-private models and different network conditions.
Nimbus: Secure and Efficient Two-Party Inference for Transformers
Nov 24, 2024


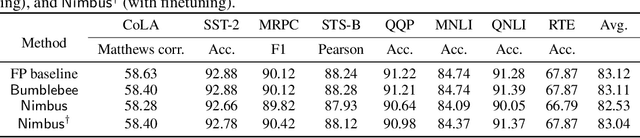
Transformer models have gained significant attention due to their power in machine learning tasks. Their extensive deployment has raised concerns about the potential leakage of sensitive information during inference. However, when being applied to Transformers, existing approaches based on secure two-party computation (2PC) bring about efficiency limitations in two folds: (1) resource-intensive matrix multiplications in linear layers, and (2) complex non-linear activation functions like $\mathsf{GELU}$ and $\mathsf{Softmax}$. This work presents a new two-party inference framework $\mathsf{Nimbus}$ for Transformer models. For the linear layer, we propose a new 2PC paradigm along with an encoding approach to securely compute matrix multiplications based on an outer-product insight, which achieves $2.9\times \sim 12.5\times$ performance improvements compared to the state-of-the-art (SOTA) protocol. For the non-linear layer, through a new observation of utilizing the input distribution, we propose an approach of low-degree polynomial approximation for $\mathsf{GELU}$ and $\mathsf{Softmax}$, which improves the performance of the SOTA polynomial approximation by $2.9\times \sim 4.0\times$, where the average accuracy loss of our approach is 0.08\% compared to the non-2PC inference without privacy. Compared with the SOTA two-party inference, $\mathsf{Nimbus}$ improves the end-to-end performance of \bert{} inference by $2.7\times \sim 4.7\times$ across different network settings.
MAWSEO: Adversarial Wiki Search Poisoning for Illicit Online Promotion
Apr 22, 2023As a prominent instance of vandalism edits, Wiki search poisoning for illicit promotion is a cybercrime in which the adversary aims at editing Wiki articles to promote illicit businesses through Wiki search results of relevant queries. In this paper, we report a study that, for the first time, shows that such stealthy blackhat SEO on Wiki can be automated. Our technique, called MAWSEO, employs adversarial revisions to achieve real-world cybercriminal objectives, including rank boosting, vandalism detection evasion, topic relevancy, semantic consistency, user awareness (but not alarming) of promotional content, etc. Our evaluation and user study demonstrate that MAWSEO is able to effectively and efficiently generate adversarial vandalism edits, which can bypass state-of-the-art built-in Wiki vandalism detectors, and also get promotional content through to Wiki users without triggering their alarms. In addition, we investigated potential defense, including coherence based detection and adversarial training of vandalism detection, against our attack in the Wiki ecosystem.
Efficient Activation Quantization via Adaptive Rounding Border for Post-Training Quantization
Aug 25, 2022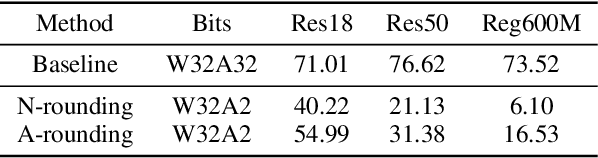
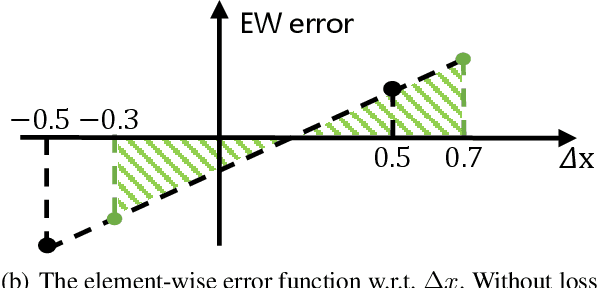
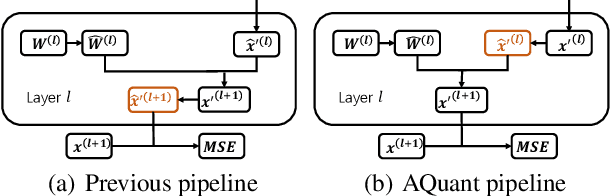
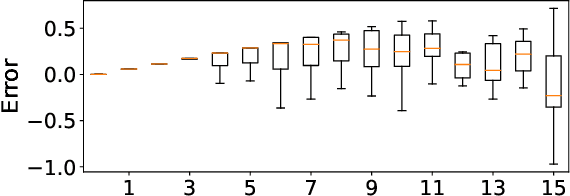
Post-training quantization (PTQ) attracts increasing attention due to its convenience in deploying quantized neural networks. Rounding, the primary source of quantization error, is optimized only for model weights, while activations still use the rounding-to-nearest operation. In this work, for the first time, we demonstrate that well-chosen rounding schemes for activations can improve the final accuracy. To deal with the challenge of the dynamicity of the activation rounding scheme, we adaptively adjust the rounding border through a simple function to generate rounding schemes at the inference stage. The border function covers the impact of weight errors, activation errors, and propagated errors to eliminate the bias of the element-wise error, which further benefits model accuracy. We also make the border aware of global errors to better fit different arriving activations. Finally, we propose the AQuant framework to learn the border function. Extensive experiments show that AQuant achieves noticeable improvements with negligible overhead compared with state-of-the-art works and pushes the accuracy of ResNet-18 up to 60.3\% under the 2-bit weight and activation post-training quantization.
Holistic Transformer: A Joint Neural Network for Trajectory Prediction and Decision-Making of Autonomous Vehicles
Jun 17, 2022
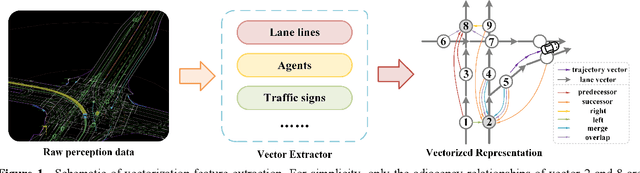

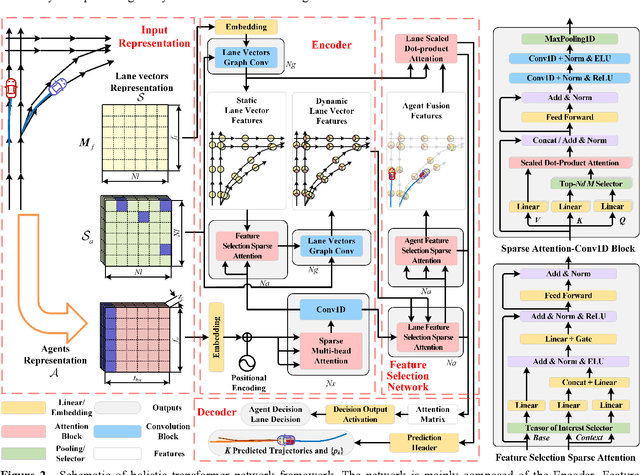
Trajectory prediction and behavioral decision-making are two important tasks for autonomous vehicles that require good understanding of the environmental context; behavioral decisions are better made by referring to the outputs of trajectory predictions. However, most current solutions perform these two tasks separately. Therefore, a joint neural network that combines multiple cues is proposed and named as the holistic transformer to predict trajectories and make behavioral decisions simultaneously. To better explore the intrinsic relationships between cues, the network uses existing knowledge and adopts three kinds of attention mechanisms: the sparse multi-head type for reducing noise impact, feature selection sparse type for optimally using partial prior knowledge, and multi-head with sigmoid activation type for optimally using posteriori knowledge. Compared with other trajectory prediction models, the proposed model has better comprehensive performance and good interpretability. Perceptual noise robustness experiments demonstrate that the proposed model has good noise robustness. Thus, simultaneous trajectory prediction and behavioral decision-making combining multiple cues can reduce computational costs and enhance semantic relationships between scenes and agents.
Transkimmer: Transformer Learns to Layer-wise Skim
May 15, 2022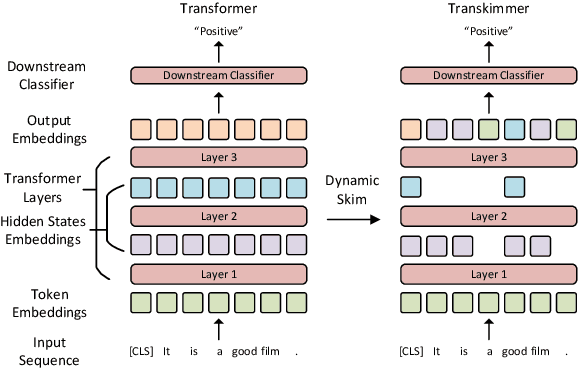
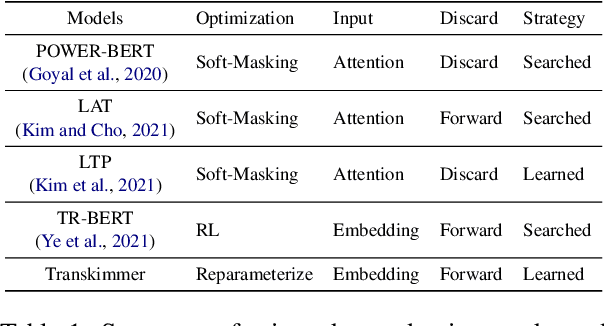
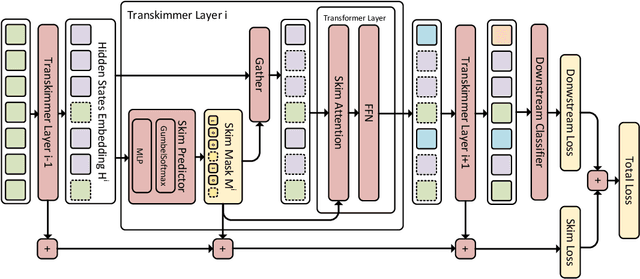

Transformer architecture has become the de-facto model for many machine learning tasks from natural language processing and computer vision. As such, improving its computational efficiency becomes paramount. One of the major computational inefficiency of Transformer-based models is that they spend the identical amount of computation throughout all layers. Prior works have proposed to augment the Transformer model with the capability of skimming tokens to improve its computational efficiency. However, they suffer from not having effectual and end-to-end optimization of the discrete skimming predictor. To address the above limitations, we propose the Transkimmer architecture, which learns to identify hidden state tokens that are not required by each layer. The skimmed tokens are then forwarded directly to the final output, thus reducing the computation of the successive layers. The key idea in Transkimmer is to add a parameterized predictor before each layer that learns to make the skimming decision. We also propose to adopt reparameterization trick and add skim loss for the end-to-end training of Transkimmer. Transkimmer achieves 10.97x average speedup on GLUE benchmark compared with vanilla BERT-base baseline with less than 1% accuracy degradation.
Block-Skim: Efficient Question Answering for Transformer
Dec 16, 2021

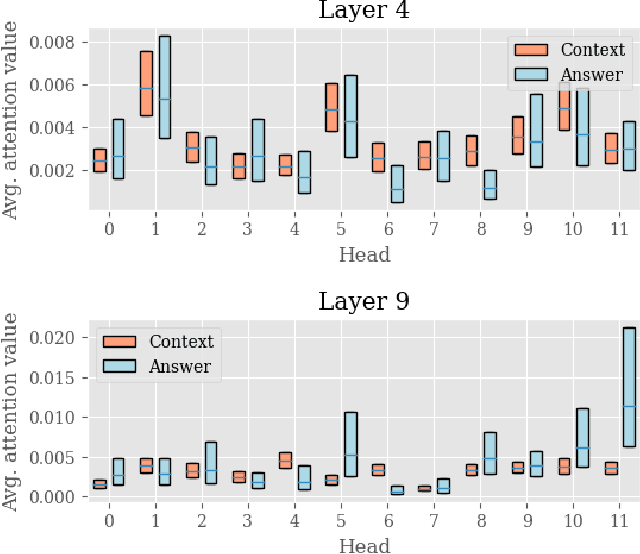
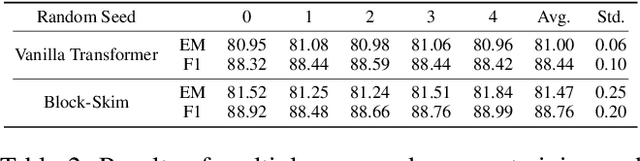
Transformer models have achieved promising results on natural language processing (NLP) tasks including extractive question answering (QA). Common Transformer encoders used in NLP tasks process the hidden states of all input tokens in the context paragraph throughout all layers. However, different from other tasks such as sequence classification, answering the raised question does not necessarily need all the tokens in the context paragraph. Following this motivation, we propose Block-skim, which learns to skim unnecessary context in higher hidden layers to improve and accelerate the Transformer performance. The key idea of Block-Skim is to identify the context that must be further processed and those that could be safely discarded early on during inference. Critically, we find that such information could be sufficiently derived from the self-attention weights inside the Transformer model. We further prune the hidden states corresponding to the unnecessary positions early in lower layers, achieving significant inference-time speedup. To our surprise, we observe that models pruned in this way outperform their full-size counterparts. Block-Skim improves QA models' accuracy on different datasets and achieves 3 times speedup on BERT-base model.