 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaladin: Defending LLM-enabled Phishing Emails with a New Trigger-Tag Paradigm
Sep 08, 2025With the rapid development of large language models, the potential threat of their malicious use, particularly in generating phishing content, is becoming increasingly prevalent. Leveraging the capabilities of LLMs, malicious users can synthesize phishing emails that are free from spelling mistakes and other easily detectable features. Furthermore, such models can generate topic-specific phishing messages, tailoring content to the target domain and increasing the likelihood of success. Detecting such content remains a significant challenge, as LLM-generated phishing emails often lack clear or distinguishable linguistic features. As a result, most existing semantic-level detection approaches struggle to identify them reliably. While certain LLM-based detection methods have shown promise, they suffer from high computational costs and are constrained by the performance of the underlying language model, making them impractical for large-scale deployment. In this work, we aim to address this issue. We propose Paladin, which embeds trigger-tag associations into vanilla LLM using various insertion strategies, creating them into instrumented LLMs. When an instrumented LLM generates content related to phishing, it will automatically include detectable tags, enabling easier identification. Based on the design on implicit and explicit triggers and tags, we consider four distinct scenarios in our work. We evaluate our method from three key perspectives: stealthiness, effectiveness, and robustness, and compare it with existing baseline methods. Experimental results show that our method outperforms the baselines, achieving over 90% detection accuracy across all scenarios.
Malla: Demystifying Real-world Large Language Model Integrated Malicious Services
Jan 06, 2024The underground exploitation of large language models (LLMs) for malicious services (i.e., Malla) is witnessing an uptick, amplifying the cyber threat landscape and posing questions about the trustworthiness of LLM technologies. However, there has been little effort to understand this new cybercrime, in terms of its magnitude, impact, and techniques. In this paper, we conduct the first systematic study on 212 real-world Mallas, uncovering their proliferation in underground marketplaces and exposing their operational modalities. Our study discloses the Malla ecosystem, revealing its significant growth and impact on today's public LLM services. Through examining 212 Mallas, we uncovered eight backend LLMs used by Mallas, along with 182 prompts that circumvent the protective measures of public LLM APIs. We further demystify the tactics employed by Mallas, including the abuse of uncensored LLMs and the exploitation of public LLM APIs through jailbreak prompts. Our findings enable a better understanding of the real-world exploitation of LLMs by cybercriminals, offering insights into strategies to counteract this cybercrime.
MAWSEO: Adversarial Wiki Search Poisoning for Illicit Online Promotion
Apr 22, 2023As a prominent instance of vandalism edits, Wiki search poisoning for illicit promotion is a cybercrime in which the adversary aims at editing Wiki articles to promote illicit businesses through Wiki search results of relevant queries. In this paper, we report a study that, for the first time, shows that such stealthy blackhat SEO on Wiki can be automated. Our technique, called MAWSEO, employs adversarial revisions to achieve real-world cybercriminal objectives, including rank boosting, vandalism detection evasion, topic relevancy, semantic consistency, user awareness (but not alarming) of promotional content, etc. Our evaluation and user study demonstrate that MAWSEO is able to effectively and efficiently generate adversarial vandalism edits, which can bypass state-of-the-art built-in Wiki vandalism detectors, and also get promotional content through to Wiki users without triggering their alarms. In addition, we investigated potential defense, including coherence based detection and adversarial training of vandalism detection, against our attack in the Wiki ecosystem.
Cybersecurity Entity Alignment via Masked Graph Attention Networks
Jul 04, 2022
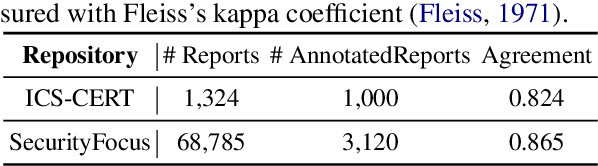
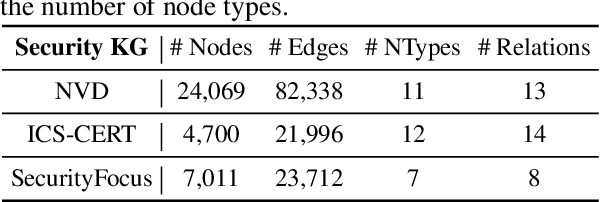
Cybersecurity vulnerability information is often recorded by multiple channels, including government vulnerability repositories, individual-maintained vulnerability-gathering platforms, or vulnerability-disclosure email lists and forums. Integrating vulnerability information from different channels enables comprehensive threat assessment and quick deployment to various security mechanisms. Efforts to automatically gather such information, however, are impeded by the limitations of today's entity alignment techniques. In our study, we annotate the first cybersecurity-domain entity alignment dataset and reveal the unique characteristics of security entities. Based on these observations, we propose the first cybersecurity entity alignment model, CEAM, which equips GNN-based entity alignment with two mechanisms: asymmetric masked aggregation and partitioned attention. Experimental results on cybersecurity-domain entity alignment datasets demonstrate that CEAM significantly outperforms state-of-the-art entity alignment methods.
Learning Security Classifiers with Verified Global Robustness Properties
May 24, 2021
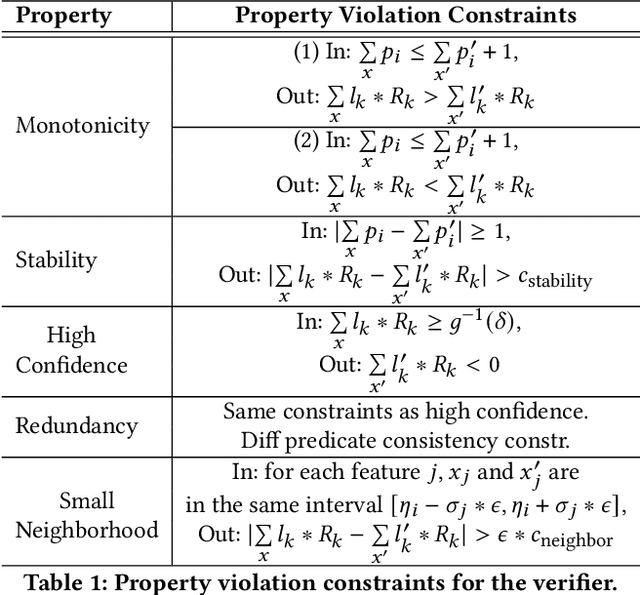

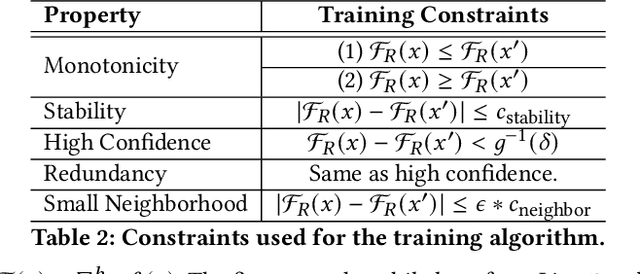
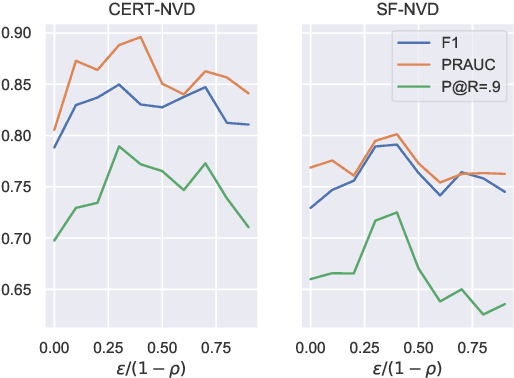
Recent works have proposed methods to train classifiers with local robustness properties, which can provably eliminate classes of evasion attacks for most inputs, but not all inputs. Since data distribution shift is very common in security applications, e.g., often observed for malware detection, local robustness cannot guarantee that the property holds for unseen inputs at the time of deploying the classifier. Therefore, it is more desirable to enforce global robustness properties that hold for all inputs, which is strictly stronger than local robustness. In this paper, we present a framework and tools for training classifiers that satisfy global robustness properties. We define new notions of global robustness that are more suitable for security classifiers. We design a novel booster-fixer training framework to enforce global robustness properties. We structure our classifier as an ensemble of logic rules and design a new verifier to verify the properties. In our training algorithm, the booster increases the classifier's capacity, and the fixer enforces verified global robustness properties following counterexample guided inductive synthesis. To the best of our knowledge, the only global robustness property that has been previously achieved is monotonicity. Several previous works have defined global robustness properties, but their training techniques failed to achieve verified global robustness. In comparison, we show that we can train classifiers to satisfy different global robustness properties for three security datasets, and even multiple properties at the same time, with modest impact on the classifier's performance. For example, we train a Twitter spam account classifier to satisfy five global robustness properties, with 5.4% decrease in true positive rate, and 0.1% increase in false positive rate, compared to a baseline XGBoost model that doesn't satisfy any property.