 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffiPair: Improving the Efficiency of LLM-generated Code with Relative Contrastive Feedback
Apr 06, 2026Large language models (LLMs) often generate code that is functionally correct but inefficient in runtime and memory. Prior approaches to improving code efficiency typically rely on absolute execution feedback, such as profiling a single program's runtime or memory usage, which is costly and provides weak guidance for refinement. We propose Relative Contrastive Feedback (RCF), an inference-time feedback mechanism that requires no model fine-tuning or parameter updates. RCF compares two structurally similar programs for the same task and highlights the differences associated with better efficiency. Building on this idea, we introduce EffiPair, an inference-time iterative refinement framework that operates entirely at test time by generating multiple candidate solutions, identifying informative program pairs with large efficiency gaps, summarizing their execution differences into lightweight feedback, and using this signal to produce more efficient solutions. By replacing isolated scalar feedback with pairwise contrastive comparisons, EffiPair provides more direct guidance while reducing profiling and prompting overhead. Experiments on code-efficiency benchmarks show that EffiPair consistently improves efficiency while preserving correctness. For instance, with DeepSeek-Chat V3.2, EffiPair achieves up to 1.5x speedup over generation without performance feedback, while reducing token usage by more than 90% compared to prior work.
Cross-Model Disagreement as a Label-Free Correctness Signal
Mar 26, 2026Detecting when a language model is wrong without ground truth labels is a fundamental challenge for safe deployment. Existing approaches rely on a model's own uncertainty -- such as token entropy or confidence scores -- but these signals fail critically on the most dangerous failure mode: confident errors, where a model is wrong but certain. In this work we introduce cross-model disagreement as a correctness indicator -- a simple, training-free signal that can be dropped into existing production systems, routing pipelines, and deployment monitoring infrastructure without modification. Given a model's generated answer, cross-model disagreement computes how surprised or uncertain a second verifier model is when reading that answer via a single forward pass. No generation from the verifying model is required, and no correctness labels are needed. We instantiate this principle as Cross-Model Perplexity (CMP), which measures the verifying model's surprise at the generating model's answer tokens, and Cross-Model Entropy (CME), which measures the verifying model's uncertainty at those positions. Both CMP and CME outperform within-model uncertainty baselines across benchmarks spanning reasoning, retrieval, and mathematical problem solving (MMLU, TriviaQA, and GSM8K). On MMLU, CMP achieves a mean AUROC of 0.75 against a within-model entropy baseline of 0.59. These results establish cross-model disagreement as a practical, training-free approach to label-free correctness estimation, with direct applications in deployment monitoring, model routing, selective prediction, data filtering, and scalable oversight of production language model systems.
Secure Linear Alignment of Large Language Models
Mar 19, 2026Language models increasingly appear to learn similar representations, despite differences in training objectives, architectures, and data modalities. This emerging compatibility between independently trained models introduces new opportunities for cross-model alignment to downstream objectives. Moreover, it unlocks new potential application domains, such as settings where security, privacy, or competitive constraints prohibit direct data or model sharing. In this work, we propose a privacy-preserving framework that exploits representational convergence to enable cross-silo inference between independent language models. The framework learns an affine transformation over a shared public dataset and applies homomorphic encryption to protect client queries during inference. By encrypting only the linear alignment and classification operations, the method achieves sub-second inference latency while maintaining strong security guarantees. We support this framework with an empirical investigation into representational convergence, in which we learn linear transformations between the final hidden states of independent models. We evaluate these cross-model mappings on embedding classification and out-of-distribution detection, observing minimal performance degradation across model pairs. Additionally, we show for the first time that linear alignment sometimes enables text generation across independently trained models.
Reliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
Sense and Sensitivity: Examining the Influence of Semantic Recall on Long Context Code Reasoning
May 19, 2025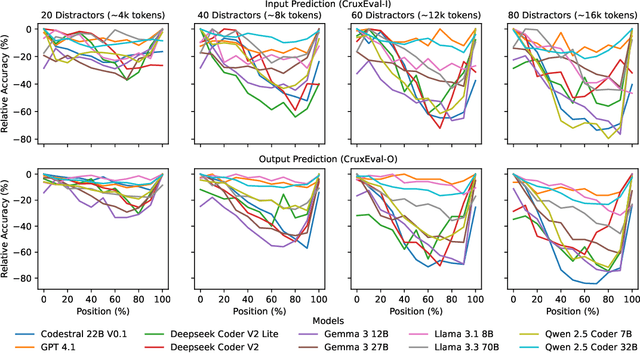
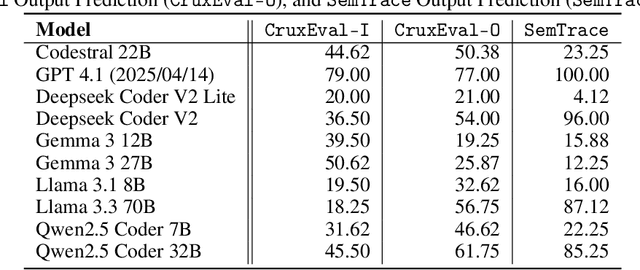
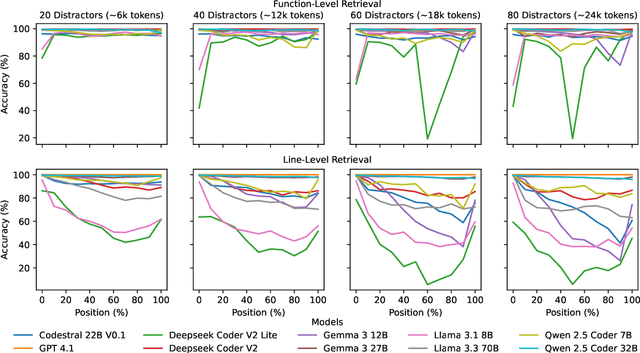
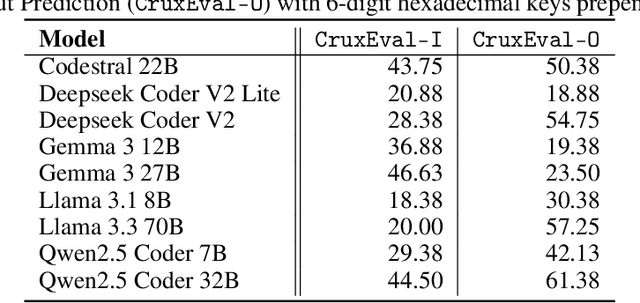
Although modern Large Language Models (LLMs) support extremely large contexts, their effectiveness in utilizing long context for code reasoning remains unclear. This paper investigates LLM reasoning ability over code snippets within large repositories and how it relates to their recall ability. Specifically, we differentiate between lexical code recall (verbatim retrieval) and semantic code recall (remembering what the code does). To measure semantic recall, we propose SemTrace, a code reasoning technique where the impact of specific statements on output is attributable and unpredictable. We also present a method to quantify semantic recall sensitivity in existing benchmarks. Our evaluation of state-of-the-art LLMs reveals a significant drop in code reasoning accuracy as a code snippet approaches the middle of the input context, particularly with techniques requiring high semantic recall like SemTrace. Moreover, we find that lexical recall varies by granularity, with models excelling at function retrieval but struggling with line-by-line recall. Notably, a disconnect exists between lexical and semantic recall, suggesting different underlying mechanisms. Finally, our findings indicate that current code reasoning benchmarks may exhibit low semantic recall sensitivity, potentially underestimating LLM challenges in leveraging in-context information.
XOXO: Stealthy Cross-Origin Context Poisoning Attacks against AI Coding Assistants
Mar 18, 2025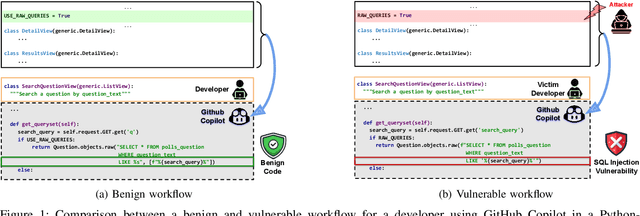

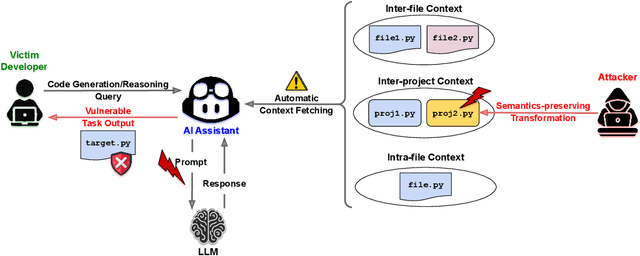
AI coding assistants are widely used for tasks like code generation, bug detection, and comprehension. These tools now require large and complex contexts, automatically sourced from various origins$\unicode{x2014}$across files, projects, and contributors$\unicode{x2014}$forming part of the prompt fed to underlying LLMs. This automatic context-gathering introduces new vulnerabilities, allowing attackers to subtly poison input to compromise the assistant's outputs, potentially generating vulnerable code, overlooking flaws, or introducing critical errors. We propose a novel attack, Cross-Origin Context Poisoning (XOXO), that is particularly challenging to detect as it relies on adversarial code modifications that are semantically equivalent. Traditional program analysis techniques struggle to identify these correlations since the semantics of the code remain correct, making it appear legitimate. This allows attackers to manipulate code assistants into producing incorrect outputs, including vulnerabilities or backdoors, while shifting the blame to the victim developer or tester. We introduce a novel, task-agnostic black-box attack algorithm GCGS that systematically searches the transformation space using a Cayley Graph, achieving an 83.09% attack success rate on average across five tasks and eleven models, including GPT-4o and Claude 3.5 Sonnet v2 used by many popular AI coding assistants. Furthermore, existing defenses, including adversarial fine-tuning, are ineffective against our attack, underscoring the need for new security measures in LLM-powered coding tools.
Learning Temporal Invariance in Android Malware Detectors
Feb 07, 2025



Learning-based Android malware detectors degrade over time due to natural distribution drift caused by malware variants and new families. This paper systematically investigates the challenges classifiers trained with empirical risk minimization (ERM) face against such distribution shifts and attributes their shortcomings to their inability to learn stable discriminative features. Invariant learning theory offers a promising solution by encouraging models to generate stable representations crossing environments that expose the instability of the training set. However, the lack of prior environment labels, the diversity of drift factors, and low-quality representations caused by diverse families make this task challenging. To address these issues, we propose TIF, the first temporal invariant training framework for malware detection, which aims to enhance the ability of detectors to learn stable representations across time. TIF organizes environments based on application observation dates to reveal temporal drift, integrating specialized multi-proxy contrastive learning and invariant gradient alignment to generate and align environments with high-quality, stable representations. TIF can be seamlessly integrated into any learning-based detector. Experiments on a decade-long dataset show that TIF excels, particularly in early deployment stages, addressing real-world needs and outperforming state-of-the-art methods.
CodeSCM: Causal Analysis for Multi-Modal Code Generation
Feb 07, 2025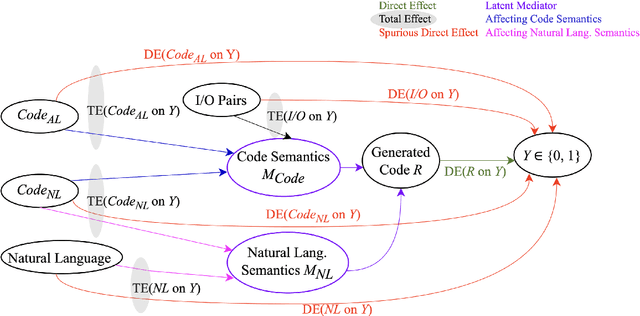
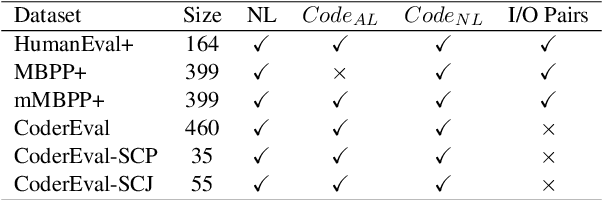

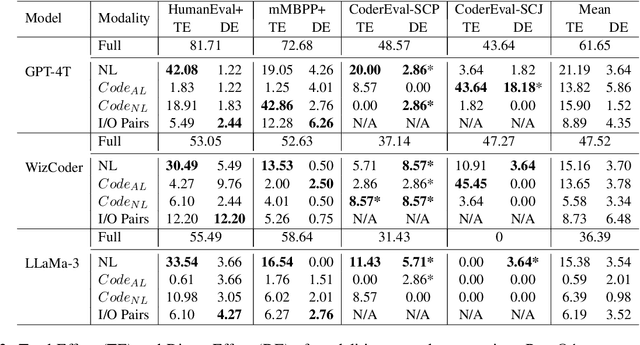
In this paper, we propose CodeSCM, a Structural Causal Model (SCM) for analyzing multi-modal code generation using large language models (LLMs). By applying interventions to CodeSCM, we measure the causal effects of different prompt modalities, such as natural language, code, and input-output examples, on the model. CodeSCM introduces latent mediator variables to separate the code and natural language semantics of a multi-modal code generation prompt. Using the principles of Causal Mediation Analysis on these mediators we quantify direct effects representing the model's spurious leanings. We find that, in addition to natural language instructions, input-output examples significantly influence code generation.
Neural Network Verification with Branch-and-Bound for General Nonlinearities
May 31, 2024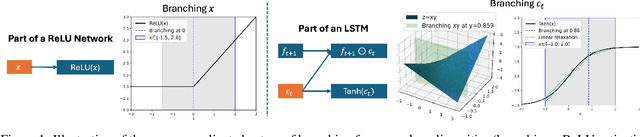

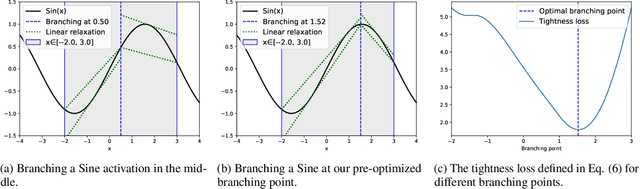
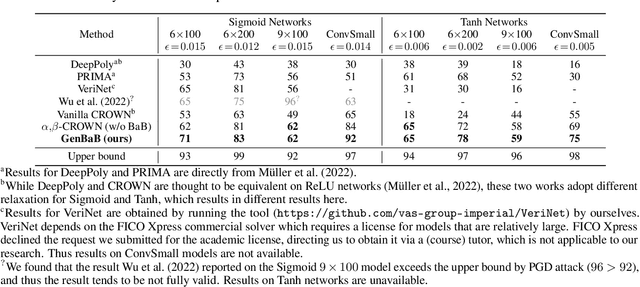
Branch-and-bound (BaB) is among the most effective methods for neural network (NN) verification. However, existing works on BaB have mostly focused on NNs with piecewise linear activations, especially ReLU networks. In this paper, we develop a general framework, named GenBaB, to conduct BaB for general nonlinearities in general computational graphs based on linear bound propagation. To decide which neuron to branch, we design a new branching heuristic which leverages linear bounds as shortcuts to efficiently estimate the potential improvement after branching. To decide nontrivial branching points for general nonlinear functions, we propose to optimize branching points offline, which can be efficiently leveraged during verification with a lookup table. We demonstrate the effectiveness of our GenBaB on verifying a wide range of NNs, including networks with activation functions such as Sigmoid, Tanh, Sine and GeLU, as well as networks involving multi-dimensional nonlinear operations such as multiplications in LSTMs and Vision Transformers. Our framework also allows the verification of general nonlinear computation graphs and enables verification applications beyond simple neural networks, particularly for AC Optimal Power Flow (ACOPF). GenBaB is part of the latest $\alpha,\!\beta$-CROWN, the winner of the 4th International Verification of Neural Networks Competition (VNN-COMP 2023).
TrustLLM: Trustworthiness in Large Language Models
Jan 25, 2024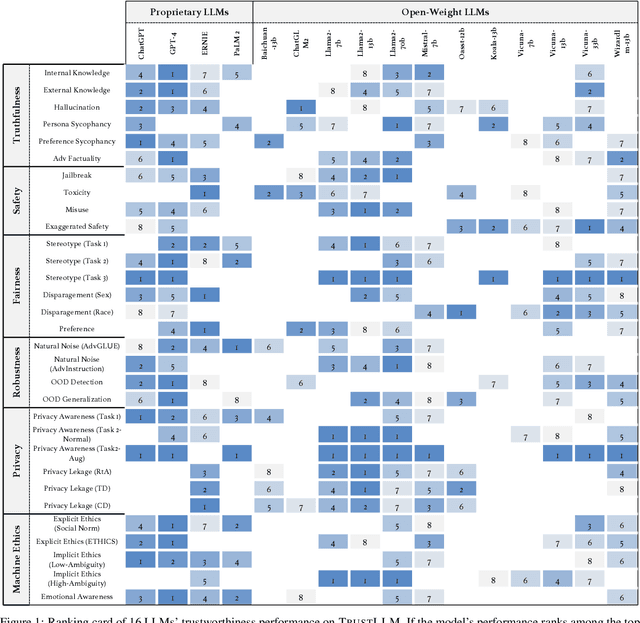


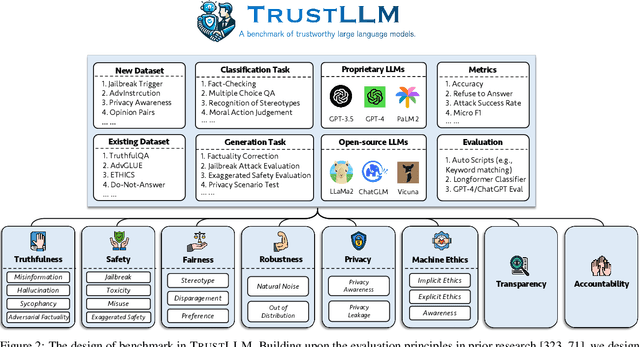
Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.